迄今为止,GPT4 模型是突破性的模型,可以免费或通过其商业门户(供公开测试版使用)向公众提供。它为许多企业家激发了新的项目想法和用例,但对参数数量和模型的保密却扼杀了所有押注于第一个 1 万亿参数模型到 100 万亿参数声明的爱好者!
模型秘密的泄露
6 月 20 日,自动驾驶初创公司 Comma.ai 创始人 George Hotz 透露,GPT-4 并不是单一的整体密集模型(如 GPT-3 和 GPT-3.5),而是 8 x 2200 亿个参数的混合模型组成
当天晚些时候,Meta 的 PyTorch 联合创始人重申了这一事件。
就在前一天,微软 Bing AI 负责人Mikhail Parakhin也暗示了这一点。
GPT 4:不是一个整体
所有推文的含义是什么?GPT-4 不是一个单一的大型模型,而是 8 个共享专业知识的较小模型的联合/集合。据传,这些模型中的每一个都有 2200 亿个参数。

该方法被称为专家模型范式的混合(链接如下)。这是一种众所周知的方法,也称为模型九头蛇。这让我想起了印度神话,我会和拉瓦那一起去。
请持保留态度,这不是官方新闻,但人工智能社区的重要高层成员已经对此表示/暗示。微软尚未证实其中任何一个。
什么是专家混合范例?
既然我们已经讨论了专家的混合,那么让我们深入了解一下它是什么。专家混合是一种专门为神经网络开发的集成学习技术。它与传统机器学习建模的通用集成技术(该形式是广义形式)略有不同。因此,您可以认为法学硕士中的专家混合是集成方法的特例。
简而言之,在该方法中,任务被分为子任务,每个子任务的专家都用来求解模型。这是创建决策树时分而治之的一种方法。人们还可以将其视为每个单独任务的专家模型之上的元学习。
可以针对每个子任务或问题类型训练更小、更好的模型。元模型学习使用哪个模型能够更好地预测特定任务。元学习器/模型充当交通警察。子任务可能重叠也可能不重叠,这意味着输出的组合可以合并在一起以得出最终输出。
专家混合(简称 MoE 或 ME)是一种集成学习技术,它实现了在预测建模问题的子任务上培训专家的想法。
在神经网络社区中,一些研究人员已经研究了分解方法。[...] 专家混合 (ME) 方法分解输入空间,以便每个专家检查空间的不同部分。[…] 门控网络负责组合各个专家。
— 第 73 页,使用集成方法进行模式分类,2010 年。
该方法有四个要素,它们是:
- 将任务划分为子任务。
- 为每个子任务培养一名专家。
- 使用门控模型来决定使用哪位专家。
- 汇集预测和门控模型输出以进行预测。
下图取自 2012 年书籍《集成方法》第 94 页,提供了对该方法的架构元素的有用概述

具有专家成员和门控网络的专家模型混合示例
取自:集成方法
子任务
第一步是将预测建模问题划分为子任务。这通常涉及使用领域知识。例如,图像可以分为单独的元素,例如背景、前景、对象、颜色、线条等。
... ME 采用分而治之的策略,其中一个复杂的任务被分解为几个更简单和更小的子任务,并且个体学习者(称为专家)接受针对不同子任务的培训。
— 第 94 页,集成方法,2012 年。
对于那些任务划分为子任务不明显的问题,可以使用更简单、更通用的方法。例如,人们可以想象一种方法,该方法按列组划分输入特征空间,或者根据标准分布的距离度量、内点和异常值等来分离特征空间中的示例。
……在ME中,一个关键问题是如何找到任务的自然划分,然后从子解决方案中推导出整体解决方案。
— 第 94 页,集成方法,2012 年。
专家模型
接下来,为每个子任务设计一个专家。
专家混合方法最初是在人工神经网络领域开发和探索的,因此传统上,专家本身就是神经网络模型,用于预测回归情况下的数值或分类情况下的类标签。
应该清楚的是,我们可以为专家“插入”任何模型。例如,我们可以使用神经网络来表示门函数和专家。结果被称为混合密度网络。
— 第 344 页,机器学习:概率视角,2012 年。
每个专家都会收到相同的输入模式(行)并做出预测。
门控模型
模型用于解释每位专家做出的预测,并帮助决定对于给定的输入信任哪位专家。这被称为门控模型或门控网络,因为它传统上是一种神经网络模型。
门控网络将提供给专家模型的输入模式作为输入,并输出每个专家在对输入进行预测时应做出的贡献。
…由门网络确定的权重是根据给定的输入动态分配的,因为 MoE 有效地了解每个集成成员学习了特征空间的哪一部分
— 第 16 页,集成机器学习,2012 年。
门控网络是该方法的关键,模型有效地学习为给定输入选择类型子任务,进而选择信任的专家来做出强有力的预测。
专家混合也可以被视为一种分类器选择算法,其中各个分类器被训练成为特征空间某些部分的专家。
— 第 16 页,集成机器学习,2012 年。
当使用神经网络模型时,门控网络和专家一起训练,以便门控网络学习何时信任每个专家做出预测。该训练过程传统上是使用期望最大化(EM)来实现的。门控网络可能有一个 softmax 输出,为每个专家提供类似概率的置信度得分。
一般来说,训练过程试图实现两个目标:对于给定的专家,找到最佳的门函数;对于给定的门函数,根据门函数指定的分布来训练专家。
— 第 95 页,集成方法,2012 年。
汇集法
最后,专家模型的混合必须做出预测,这是通过池化或聚合机制来实现的。这可能就像选择门控网络提供的具有最大输出或置信度的专家一样简单。
或者,可以进行加权和预测,明确地将每个专家做出的预测与门控网络估计的置信度结合起来。您可能会想到其他方法来有效利用预测和门控网络输出。
然后,池化/组合系统可以选择具有最高权重的单个分类器,或者计算每个类别的分类器输出的加权和,并选择接收最高加权和的类别。
— 第 16 页,集成机器学习,2012 年。
交换机路由
我们还应该简要讨论与 MoE 论文不同的交换机路由方法。我提出这个问题是因为微软似乎使用了交换机路由而不是专家模型来节省一些计算复杂性,但我很高兴被证明是错误的。当有多个专家的模型时,它们的路由函数可能有一个不平凡的梯度(何时使用哪个模型)。该决策边界由交换层控制。
交换层的好处有三个。
- 如果令牌仅路由到单个专家模型,则路由计算会减少
- 由于单个令牌进入单个模型,批量大小(专家容量)至少可以减半
- 简化了路由实现并减少了通信。
同一令牌与 1 个以上专家模型的重叠称为容量因子。以下是具有不同专家能力因素的路由如何工作的概念描述

令牌路由动态的图示。
每个专家处理由容量因子调制的固定批量大小的令牌。每个令牌都会路由到具有最高路由概率的专家
,但每个专家都有固定的批量大小
(总令牌/专家数量)×容量因子。如果令牌分配不均匀
,则某些专家将溢出(用红色虚线表示),导致
这些令牌不被该层处理。较大的容量系数可以缓解
这种溢出问题,但也会增加计算和通信成本
(由填充的白色/空槽表示)。(来源https://arxiv.org/pdf/2101.03961.pdf)
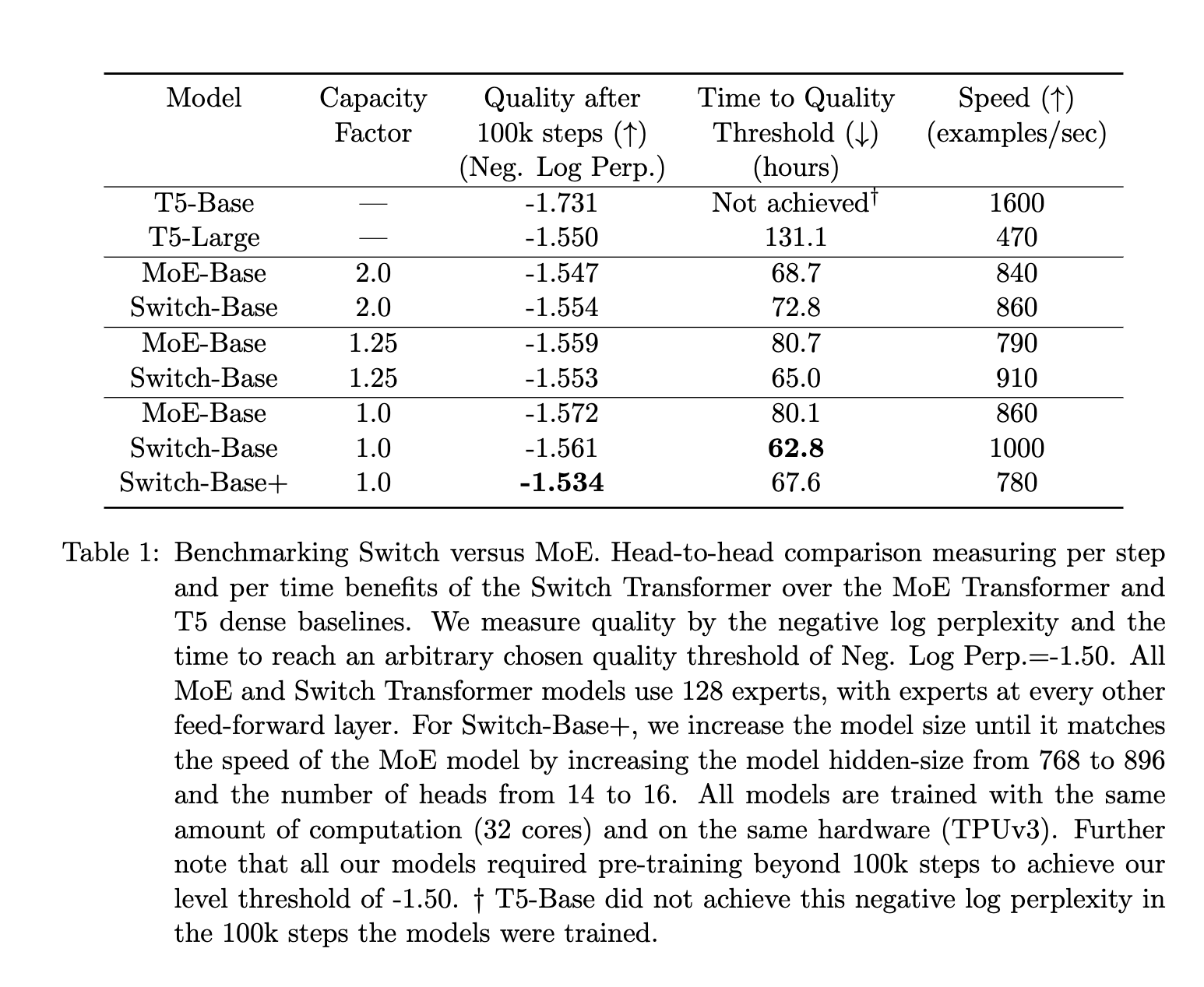
与 MoE 相比,MoE 和 Switch 论文的调查结果表明:
- 开关变压器在速度质量的基础上优于精心调整的密集模型和 MoE 变压器。
- 开关变压器的计算空间比 MoE 更小
- 开关变压器在较低容量系数 (1–1.25) 下表现更好。
结论
有两个警告,第一,这一切都来自道听途说,第二,我对这些概念的理解相当薄弱,所以我敦促读者持保留态度。
但是微软通过隐藏这种架构实现了什么目的呢?好吧,他们引起了轰动,并引发了悬念。这可能有助于他们更好地讲述自己的故事。他们将创新保留在自己手中,避免其他人更快地赶上他们。整个想法很可能是微软惯常的游戏计划,即在向一家公司投资 10B 的同时阻碍竞争。
GPT-4 的性能很棒,但它并不是一个创新或突破性的设计。这是工程师和研究人员开发的方法的巧妙实现,并辅以企业/资本主义部署。OpenAI 既没有否认也没有同意这些说法(https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed),这让我认为 GPT-4 的这种架构很有可能是真的