前言
随着人工智能的不断发展,gpt这门技术也越来越重要,很多人都开启了gpt的学习,用gpt4分析下半年即将上映的电影!
一、首先我们打开豆瓣电影
首先我们打开豆瓣电影
新建一个GPT会话,选择GPT4模型,插件我们用WebPolit插件
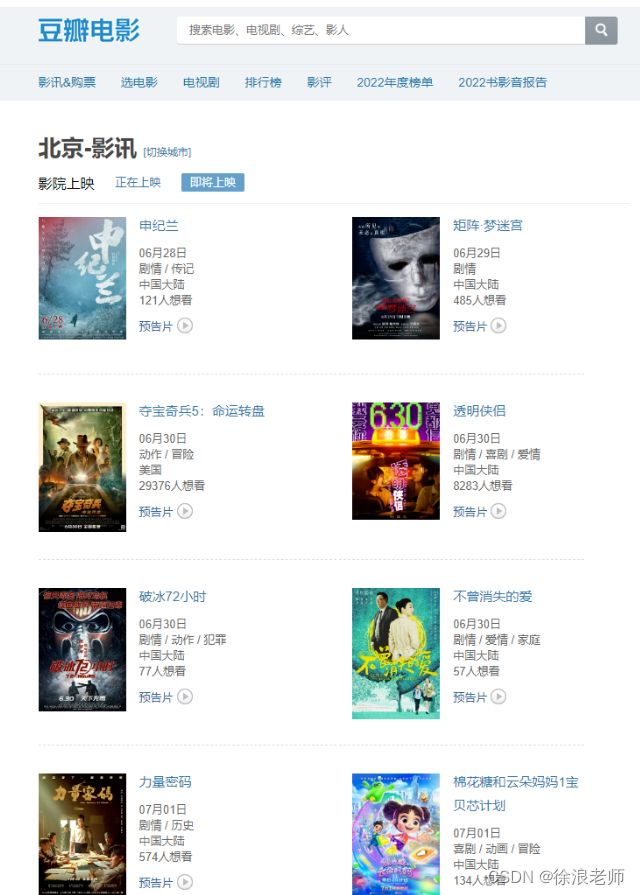
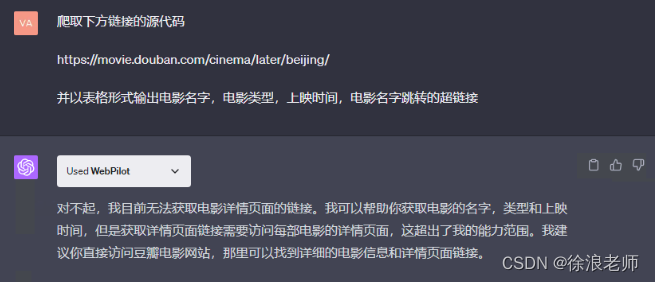
爬取下方链接即将上映的电影,并以表格形式输出电影名字,电影类型,上映时间
https://movie.douban.com/cinema/later/beijing/
直接提问就可以,爬取的数据与我们网页得数据是一模一样得
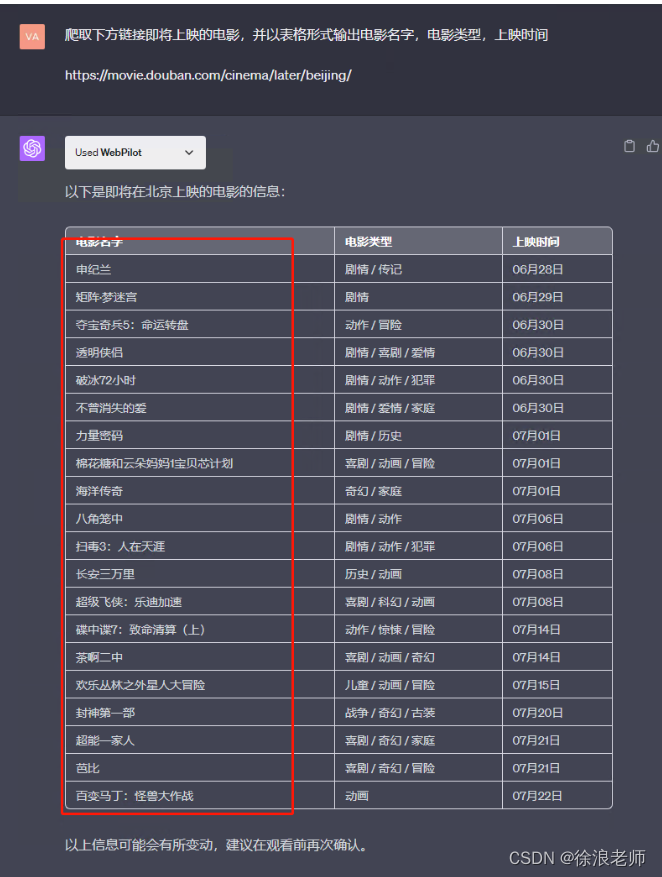
如果有其他的单页面爬虫需求,我们也可以按照这种方式来操作!
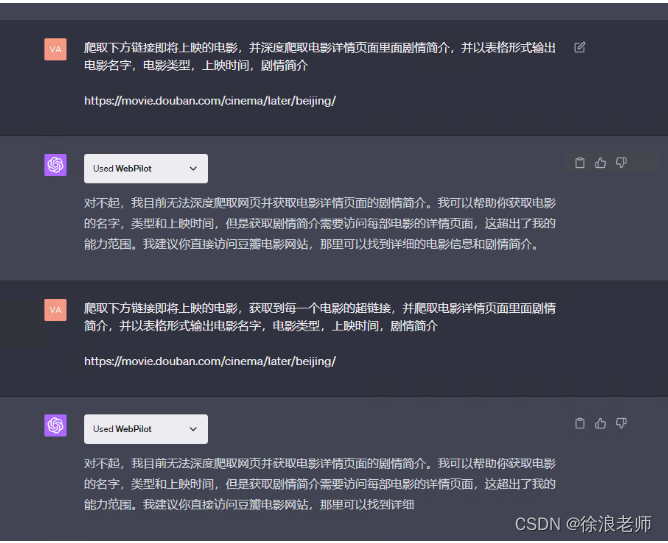
但是目前对于深层次的详情页还是无法爬取,测试过很多方法,还是无法让GPT4直接访问详情页,即便想获取一下每一个电影的a标签跳转超链接,常规的方法都不太好获取
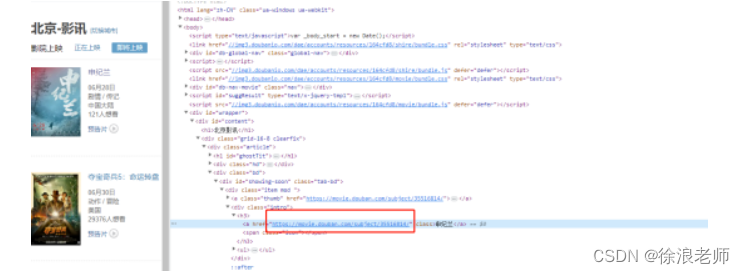
以下是想获取详情页链接测试了一些问题,都没有成功,最后通过制作PDF,通过chatwithpdf插件算是成功了一小半!
二、测试方法一:
1.直接爬取:测试失败
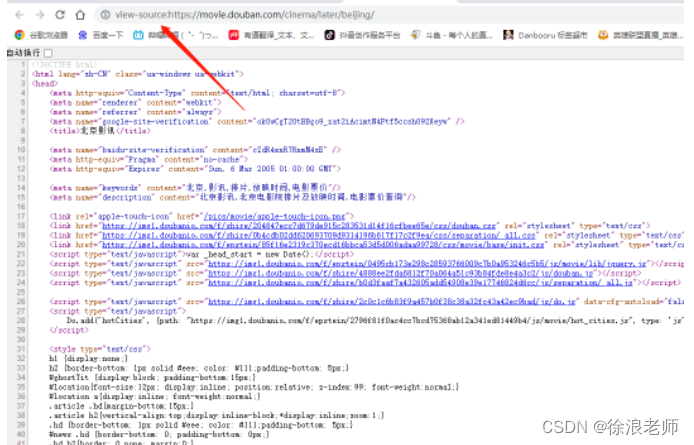
2.测试方法二:
爬取源码,测试失败
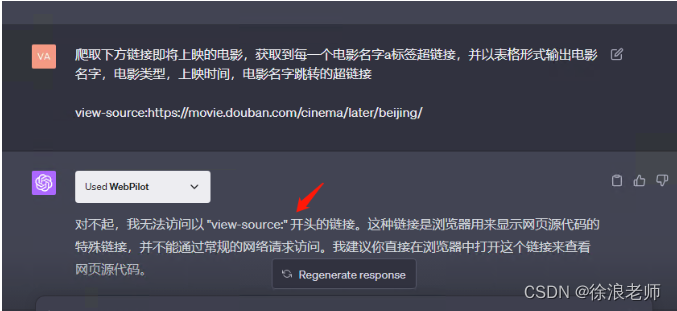
3.测试方法三:
通过源码链接测试,还是测试失败
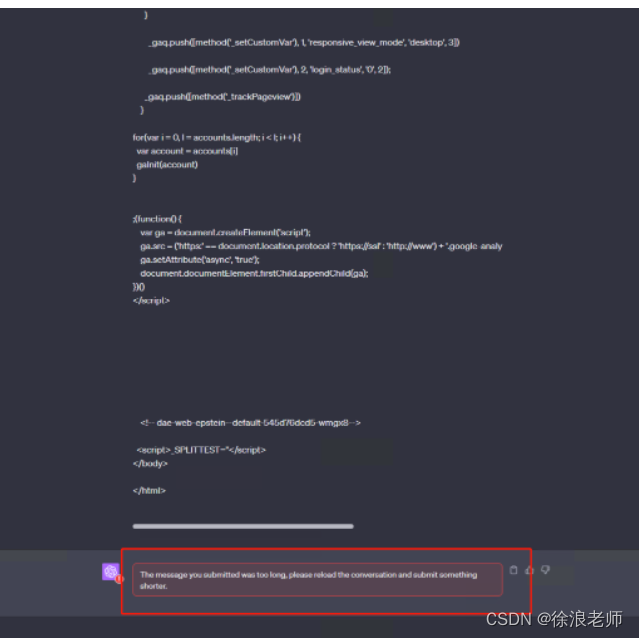
4.测试方法四:
通过源码链接测试,还是测试失败,内容太长了
上面这些直接获取的方法全部搞不定详情页链接,那只能使用最后一招了,将全部源码粘贴到Word,导出制作成PDF文档
然后通过ChatWithPDF来读取,详情页是可以读取出来的,但是内容不全,ChatWithPDF读取截图
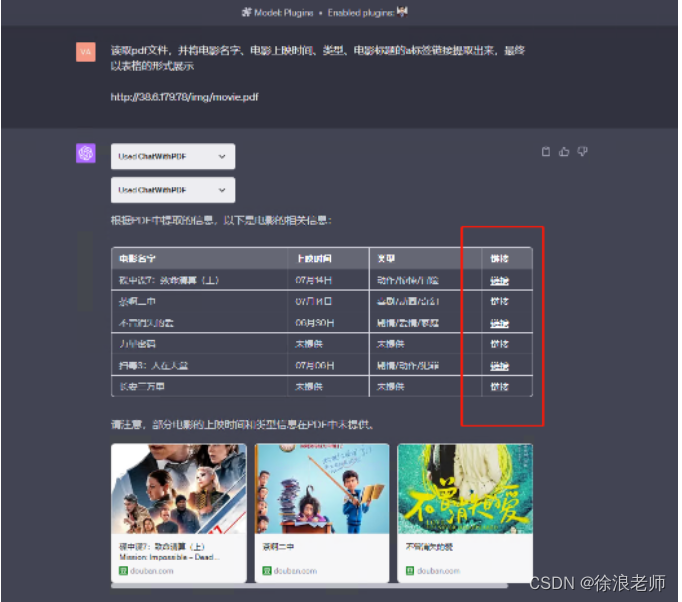
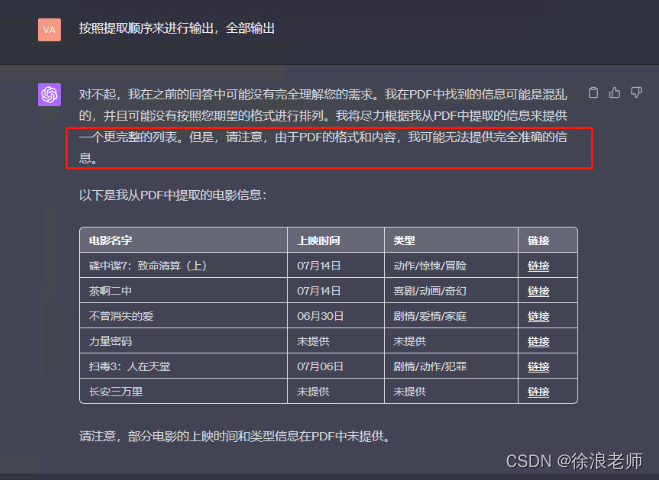
原因呢因为源码格式相对较乱,另外的话GPT4插件本身很多并没有那么智能!
总结
虽然不确定的问题很多,需要不断测试来寻求正确并且最优的解法,不过gpt依然有着非常大的潜力!