前言
当你看到这的时候,我经历了崩溃,重构了代码。我发现我之前写的代码,居然会发生死锁!?我通过打印找了一晚上,发现最后会在RequestVote上获取锁的时候失败,导致一直卡在那。我上网看到一位博主也是遇到了这个问题,他也是用的select,属于是同病相怜了。
现在突然回顾起来,教授上课的时候就说不要用select或者timer,会发生意想不到的问题,我当时没有在意这句话,现在才发现怎么那么头铁啊。。。
实在是debug不动了,进行代码重构的时候借鉴了这位博主的代码,然而还是会出一些问题,test并不稳定。鉴于今天已经15号了,我之前的打算就是在15号之前完成前面2个lab,然后去复习,我也没有时间再做了,就先这样吧,或许未来有机会我再来好好打磨一遍。
1. 快照
这一个部分要我们做的是日志压缩,原因就是论文中说的:Raft 的日志在正常运行时会增长,以容纳更多的客户端请求,但在实际系统中,它不能无限制地增长。 随着日志变长,它会占用更多空间并需要更多时间来重播。 如果没有某种机制来丢弃日志中积累的过时信息,这最终会导致可用性问题。也因此我们使用Snapshot(快照)来简单的实现日志压缩。
1.1 快照的概念
快照和备份是不一样的,这一点不要搞混淆了。
- 备份是将整个日志文件原封不动地复制到第二存储设备,文件量大,而且还需要考虑网络的问题,主要用于防止硬件故障造成得数据丢失,也可以用于数据逻辑错误造成的数据不可用。
- 而快照不是数据的完整拷贝,它只是数据的一个影子,要小得多,当数据本身丢失了,影子也就不存在了,也因此,快照只能用于逻辑错误或人为误删造成的数据不可用,不能防止硬件故障造成的数据丢失。
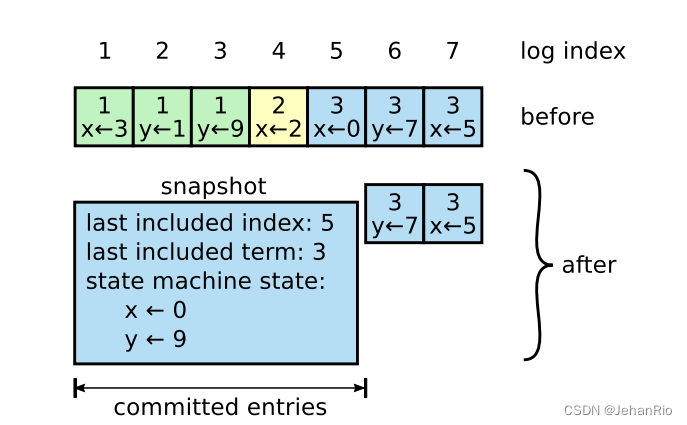
通过图我们也能很清晰地知道快照的道理,我们相当于是只保留了数据的最后存储信息,log的长度也从7变成了2。
也因此可以看出,快照的存储是根据raft的数据决定的,有多少个数据就有多少个快照节点,每个数据都有自己的快照,快照的信息就相当于commit过后的日志。
1.2 快照的优缺点
以下源自论文翻译:
还有两个问题会影响快照性能。首先,服务器必须决定何时快照。如果服务器快照的频率过高,就会浪费磁盘带宽和能源;如果快照的频率过低,就会有耗尽存储容量的风险,而且会增加重启时重放日志所需的时间。
一种简单的策略是,当日志达到以字节为单位的固定大小时拍摄快照。 如果将该大小设置为明显大于快照的预期大小,那么用于快照的磁盘带宽开销就会很小。
第二个性能问题是,写快照可能会耗费大量时间,我们不希望因此耽误正常操作。解决办法是使用写入时复制技术,这样就能在不影响正在写入的快照的情况下接受新的更新。例如,使用功能数据结构构建的状态机自然支持这种方法。另外,也可以使用操作系统的写时拷贝支持(如 Linux 上的 fork)来创建整个状态机的内存快照(我们的实现采用了这种方法)。
总结以下就是两个问题:
- 快照设置过于频繁会造成磁盘带宽和能源问题,设置频率太低会导致存储问题。论文提到的方法是根据日志的大小来进行跟新,超过这个大小更新一次。
- 还有个问题就是时间开销。写入快照时会浪费大量时间(锁、写入等)。论文提到的方法是先暂时备份一份log。
2. 快照的设计
2.1 RPC
这部分是和之前的leader选举、发送日志/心跳一样的,触发RPC后,等待返回结果,结构体参数根据论文来,论文有分片,这里我们就不选择分片了。
type InstallSnapshotArgs struct {
Term int // 发送请求的Term
LeaderId int // 请求方的Id
LastIncludedIndex int // 快照最后applied的日志下标
LastIncludedTerm int // 快照最后applied时的Term
Data []byte // 快照区块的原始字节流数据
// offset int // 次传输chunk在快照文件的偏移量,快照文件可能很大,因此需要分chunk,此次不分片
// Done bool // true表示是最后一个chunk
}
type InstallSnapshotReply struct {
Term int // 让leader自己更新的
}
func (rf *Raft) sendSnapShot(server int, args *InstallSnapshotArgs, reply *InstallSnapshotReply) bool {
ok := rf.peers[server].Call("Raft.InstallSnapShot", args, reply)
return ok
}
2.2 发起快照的时机
什么时候发起快照呢?除了leader收到上层应用层的命令,执行SnapShot以外,我们要发送心跳/日志的时候,leader会去check自己的快照位置即rf.lastIncludedIndex,与rf.next[server]-1相比谁更大,如果快照点更大,说明follower想要的日志已经被我们给优化掉了,就得发送快照过去,快照其实也是一个心跳/日志(所以如果follower发现发来的term更小,依旧会执行那些拒绝操作),你可以理解为发送的之前的一个压缩包,能够更快的跟上leader。
leaderSendSnapShot
func (rf *Raft) leaderSendSnapShot(server int) {
rf.mu.Lock()
args := InstallSnapshotArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
LastIncludedIndex: rf.lastIncludedIndex,
LastIncludedTerm: rf.lastIncludedTerm,
Data: rf.persister.ReadSnapshot(),
}
rf.mu.Unlock()
reply := InstallSnapshotReply{
}
if ok := rf.sendSnapShot(server, &args, &reply); !ok {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != Leader || rf.currentTerm != args.Term {
return
}
if reply.Term > rf.currentTerm {
rf.convert2Follower(reply.Term)
return
}
rf.matchIndex[server] = args.LastIncludedIndex
rf.nextIndex[server] = rf.matchIndex[server] + 1
}
// follower更新leader的快照
func (rf *Raft) InstallSnapShot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentTerm > args.Term {
reply.Term = rf.currentTerm
return
}
reply.Term = args.Term
rf.convert2Follower(args.Term)
// 已经覆盖了这个快照了,不用再写入快照
if rf.lastIncludedIndex >= args.LastIncludedIndex {
return
}
// 将快照后的log切割,快照前的提交
index := args.LastIncludedIndex
tempLog := make([]logEntry, 0)
tempLog = append(tempLog, logEntry{
})
for i := index+1; i <= rf.getLastIndex(); i++ {
tempLog = append(tempLog, rf.restoreLog(i))
}
rf.log = tempLog
rf.lastIncludedIndex = index
rf.lastIncludedTerm = args.LastIncludedTerm
if index > rf.CommitIndex {
rf.CommitIndex = index
}
if index > rf.lastApplied {
rf.lastApplied = index
}
rf.persister.Save(rf.encodeState(), args.Data)
applyMsg := ApplyMsg{
SnapshotValid: true,
Snapshot: args.Data,
SnapshotTerm: rf.lastIncludedTerm,
SnapshotIndex: rf.lastIncludedIndex,
}
rf.applyChan <- applyMsg
}
Snapshot
func (rf *Raft) Snapshot(index int, snapshot []byte) {
// Your code here (2D).
rf.mu.Lock()
defer rf.mu.Unlock()
// 如果下标大于自身commit,说明没被提交,不能执行快照,若自身快照大于index则说明已经执行过快照,也不需要
if rf.lastIncludedIndex >= index || index > rf.CommitIndex {
return
}
// 裁剪日志
sLog := make([]logEntry, 0)
sLog = append(sLog, logEntry{
})
for i := index + 1; i <= rf.getLastIndex(); i++ {
sLog = append(sLog, rf.restoreLog(i))
}
// 更新快照下标和快照Term
if index == rf.getLastIndex() + 1 {
rf.lastIncludedTerm = rf.getLastTerm()
} else {
rf.lastIncludedTerm = rf.restoreLogTerm(index)
}
rf.lastIncludedIndex = index
rf.log = sLog
// 需要重置commitIndex、lastApplied下标
if index > rf.CommitIndex {
rf.CommitIndex = index
}
if index > rf.lastApplied {
rf.lastApplied = index
}
rf.persister.Save(rf.encodeState(), snapshot)
}
2.3 需要注意的一些细节
我觉得Lab2D的细节是令人最作呕的,我一开始在写我的version的时候,就去改变下标(一般都是减去rf.lastIncludedIndex)如果一个下标漏掉了,test就通过不了,调试起来真的太累了。至于为什么用select执行不了,会发生死锁,我至今也没搞明白,我不懂为什么在做第三个lab的时候能够在执行集成测试时通过,我对于测试源码的代码没有去细看,也许就像Frans说的那样,如果在通的过程中遇到了未知的错误,会卡住,导致其他协程无法获取到锁或者资源吧。所以课上教授也说了,用Sleep来实现。
这位博主实现的细节中,他在初始化即Make的时候,加入了一个空日志,每个人的做法不一样,他这样做或许就不用担心一开始发送nil了,而我最初的实现就是判断args.prevLogIndex是否小于0,每个人的实现不一样,这一点需要注意。
还有一个细节是,在Make初始化阶段,当你读取快照后,需要将你的rf.lastApplied重新赋值为rf.lastIncludedIndex,否则你在执行的过程中会报错的。
3. 测试
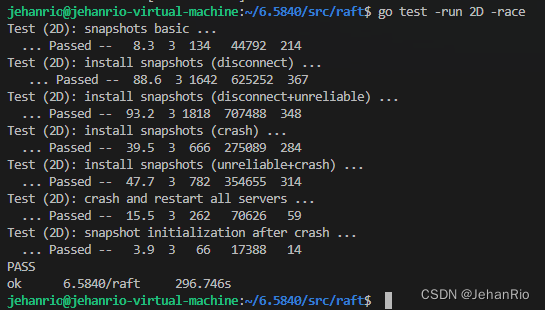
可以很明确的是,这一版的代码依旧有错误,单次测试没有意义,希望读者注意一下,在你准备看此篇文章,拿来借鉴的读者需要谨慎。
4. 总结
总的来说,Lab2的难度着实大,前面3个Part虽经历磨难,但也完成了测试。遗憾的是,我并没有以我的代码实现四个完整的Part,INTJ的人总是特别固执,当我重构代码的时候,一把泪一把泪的流TnT。后面也没有多少时间了,今天是8月15日,离终点只剩一个月了,6.824这一块,我会先放一边,进行课程复习和项目复习了,我想,如果后面有机会,我会继续完成后面两个Lab的,算是给自己挖的一个坑吧,希望自己能够把它填上。也祝我自己好运,如果后面成了的话,我会发一篇长文来好好谈谈我的大学的。
So,Anway,各位有缘再见。Bye~