1. 第1周资源
以下是本周视频中讨论的研究论文的链接。您不需要理解这些论文中讨论的所有技术细节 - 您已经看到了您需要回答讲座视频中的测验的最重要的要点。
然而,如果您想更仔细地查看原始研究,您可以通过以下链接阅读这些论文和文章。
1.1 Transformer架构
- 注意力就是你需要的 《Attention is All You Need》
- 本文介绍了Transformer架构,以及核心的“自注意力”机制。这篇文章是LLMs的基础。
- BLOOM:BigScience 176B模型《BLOOM: BigScience 176B Model 》
- BLOOM是一个开源的LLM,拥有176B的参数(类似于GPT-4),以开放透明的方式进行训练。在这篇论文中,作者详细讨论了用于训练模型的数据集和过程。您还可以在这里查看模型的高级概述。
- 向量空间模型 《Vector Space Models》
- DeepLearning.AI的自然语言处理专项课程系列课程,讨论了向量空间模型的基础及其在语言建模中的应用。
1.2 预训练和缩放法则
- 神经语言模型的缩放法则《Scaling Laws for Neural Language Models》
- OpenAI的研究人员进行的实证研究,探索了大型语言模型的缩放法则。
1.3 模型架构和预训练目标
- 什么语言模型架构和预训练目标最适合Zero-shot泛化?《What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?》
- 本文研究了大型预训练语言模型中的建模选择,并确定了零射击泛化的最佳方法。
- 使用HuggingFace库处理各种机器学习任务的资源集合。
- LLaMA:开放和高效的基础语言模型《LLaMA: Open and Efficient Foundation Language Models》
- Meta AI提出的高效LLMs文章(他们的13 Billion模型在大多数基准测试上的性能超过了拥有175Billion参数的GPT3)
1.4 缩放法则和计算最佳模型
- 语言模型是少射击学习者《Language Models are Few-Shot Learners》
- 本文研究了大型语言模型中少射击学习的潜力。
- 训练计算最佳大型语言模型 《Training Compute-Optimal Large Language Models》
- DeepMind的研究,评估训练LLMs的最佳模型大小和令牌数量。也被称为“Chinchilla论文”。
- BloombergGPT:金融领域的大型语言模型 《BloombergGPT: A Large Language Model for Finance》
- 专门为金融领域训练的LLM,是一个试图遵循chinchilla法则的好例子。
2. BloombergGPT
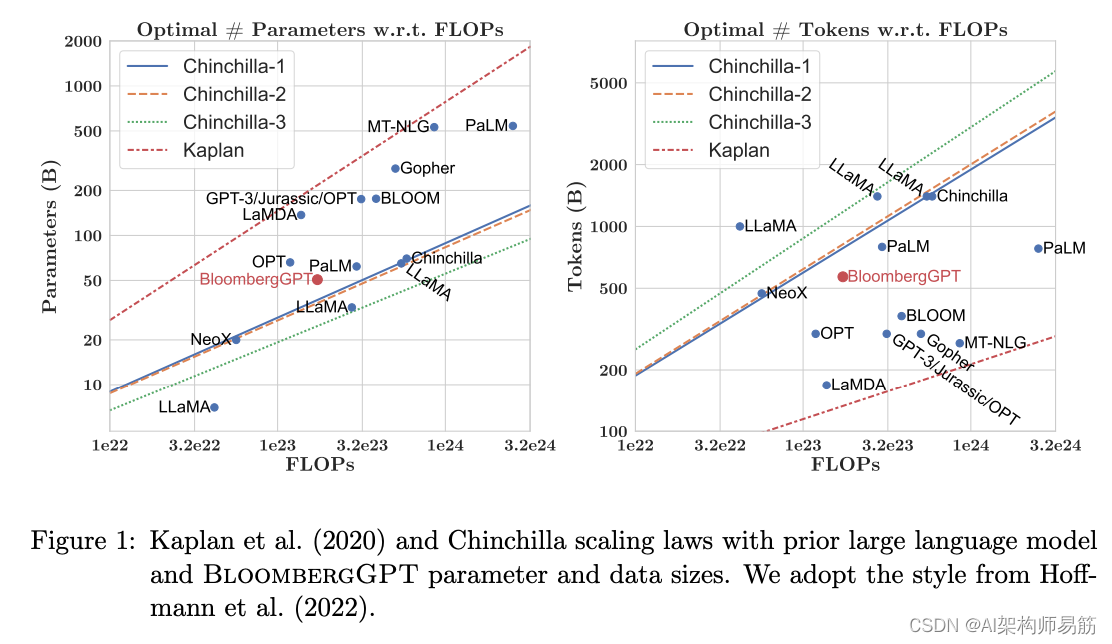
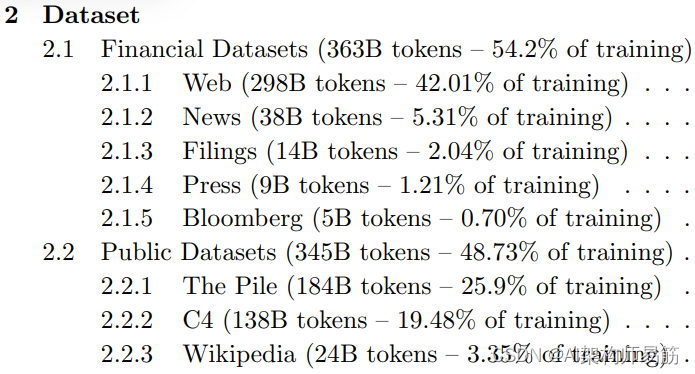
BloombergGPT是由Bloomberg开发的大型仅解码器语言模型。它使用了包括新闻文章、报告和市场数据在内的广泛金融数据集进行预训练,以增强其对金融的理解,并使其能够生成与金融相关的自然语言文本。数据集在上面的图片中显示。
在BloombergGPT的训练过程中,作者使用了Chinchilla缩放法则来指导模型中的参数数量和训练数据的量,以令牌为单位进行测量。Chinchilla的建议由图片中的Chinchilla-1、Chinchilla-2和Chinchilla-3线表示,我们可以看到BloombergGPT与其非常接近。
尽管团队可用的训练计算预算的推荐配置是500亿参数和1.4万亿令牌,但在金融领域获得1.4万亿令牌的训练数据证明是具有挑战性的。因此,他们构建了一个只包含7000亿令牌的数据集,少于计算最佳值。此外,由于提前停止,训练过程在处理5690亿令牌后终止。
BloombergGPT项目是一个很好的例子,说明了如何为增加领域特异性进行模型预训练,以及可能迫使您在计算最佳模型和训练配置之间做出权衡的挑战。
您可以在这里阅读BloombergGPT的文章。
参考
- https://www.coursera.org/learn/generative-ai-with-llms/supplement/Adylf/domain-specific-training-bloomberggpt
- https://www.coursera.org/learn/generative-ai-with-llms/supplement/kRX5c/week-1-resources