-
为什么查询速度会慢
-
慢查询基础:优化数据访问
-
确认应用程序是否在检索大量超过需要的数据,这通常意味着访问了太多的行,但有时候也可能是访问了太多的列
-
查询不需要的数据
-
多表关联时返回全部列
-
总是取出全部列
-
重复查询相同的数据
-
确认mysql服务器层是否在分析大量超过需要的数据行
-
衡量查询开销的三个指标
-
响应时间
-
扫描的行数
-
返回的记录数
-
响应时间
-
响应时间只是一个表面上的值
-
响应时间是两个部分之和:服务时间和排队时间
-
扫描的行数和返回的行数
-
分析查询时,查看该查询扫描的行数十分常有帮助的,这在一定程度上能够说明该查询找到数据的效率高不高
-
扫描的行数和访问类型
-
从慢到快:全表扫描、索引扫描、唯一索引扫描、常数引用,扫描行数也是大到小
-
一般mysql能够使用如下三种方式应用where条件,从好到坏为:
-
在索引中使用where条件来过滤不匹配的记录,这是在存储引擎层完成的
-
使用索引覆盖扫描来返回记录,直接从索引中过滤不需要的记录并返回命中的结果,这是在mysql引擎层完成的,但无需再回表查询记录
-
从数据表中返回数据,然后过滤不满足条件的记录(useng where),这是在mysql服务器层完成的,mysql需要先从数据表中读出记录然后过滤
-
重构查询的方式
-
一个复杂查询还是多个简单查询
-
这是在设计查询的时候一个需要考虑的问题,是否将一个查询分成多个简单的查询
-
切分查询
-
有时候对于一个大查询我们要‘分而治之‘,将大查询切分成小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果
-
分解关联查询
-
很多高性能的应用都会对关联查询进行分解。简单地,可以对每一个表进行单次查询,然后将结果在应用程序中进行关联
-
优势:
-
让缓存的效率更高
-
将查询分解后,执行单个查询可以减少锁竞争
-
在应用层做关联,可以更容易对数据库行进拆分,更容易做到高性能和可扩展
-
查询本身效率也可能有所提升
-
可以减少冗余记录的查询
-
更进一步,这熊当于在应用中实现了hash关联,而不是使用mysql的嵌套循环关联
-
查询执行的基础
-
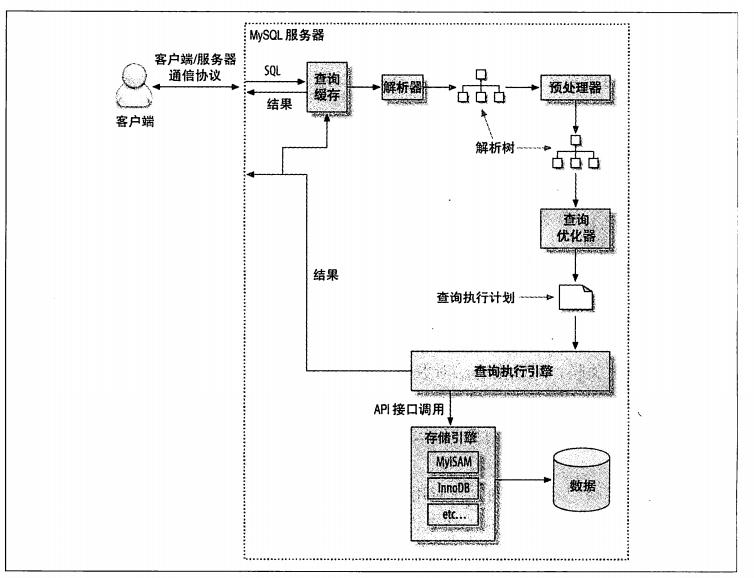
-
客户算首先发送一条查询给服务器
-
服务器先检查缓存,如果命中缓存,则立刻返回存储在缓存中的结果 ,否则进入下一阶段
-
服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划
-
mysql根据优化器生成的执行 计划,条用存储引擎的API来执行查询
-
将结果返回给客户端
-
MySQL客户端/服务器通信协议
-
查询状态
-
sleep
-
query
-
locked
-
analyzing and statistics 线程、正在手机存储引擎的统计信息,并生成查询的执行计划
-
copying to tmp table [on disk]
-
sorting result
-
sending data
-
查询缓存
-
查询和缓存中的查询即使只用一个字节不同,那么也不会匹配缓存结果
-
查询优化处理
-
查询的生命周期的下一步是将一个SQL转换成一个执行计划,mysql再依照这个执行计划和存储引擎进行交互。
-
语法解析器和预处理
-
查询优化器
-
有很多种原因会导致mysql优化器选择错误的执行计划:
-
统计信息不准确
-
执行计划中的成本估算不等同于实际执行的成本
-
mysql只是基于其成本模型选择最优的执行计划,而有些时候这些并不是最快的执行方式
-
mysql从不考虑其他并发执行的查询 ,这可能会影响当前查询的速度
-
mysql并不是任何时候都是基于成本的优化,有时也会基于一些固定的规则
-
mysql不会考虑不受其控制的操作的成本
-
优化器有时候无法去估算所有可能的执行计划,所以他可能错过实际上最优的执行计划
-
优化策略可以简单地分为两种,一种是静态优化,一种是动态优化
-
静态优化可以直接对解析数进行分析,并完成优化
-
静态优化不依赖于特别的数值,如where条件中带入的一些常数等
-
静态优化在第一次完成后就一直有效,即使使用不同的参数重复执行查询也不会发生变化
-
动态优化则和查询上下文有关,也可能和很多 其他因素有关
-
在执行语句和存储过程的时候,动态优化和静态优化的区别非常重要
-
mysql能够处理的优化类型
-
重新定义关联表的顺序
-
将外连接转化成内连接
-
使用等价变换规则
-
优化count(),min()和max()
-
预估并转化为常数表达式
-
覆盖索引扫描
-
子查询优化
-
提前终止查询
-
等值传播
-
列表IN()的比较
-
数据和索引的统计信息
-
统计信息由存储引擎实现,不同的存储引擎可能会有存储不同的统计信息
-
mysql如何执行关联查询(join)
-
mysql中的关联一次所包含的意义比一般意义上理解的要更广泛,mysql认为任何一个查询都是一次关联--并不仅仅是一个查询需要到两个表匹配才叫关联,所以在mysql中 ,每一个查询,每一个片段(包括子查询,基于单表的select)都可能是关联
-
mysql对任何关联都执行嵌套循环关联操作,即mysql现在一个表中循环取出单条数据,然后再嵌套到下一个表中寻找匹配的行,一次下去,直到找到所有表中匹配 的行为止
-
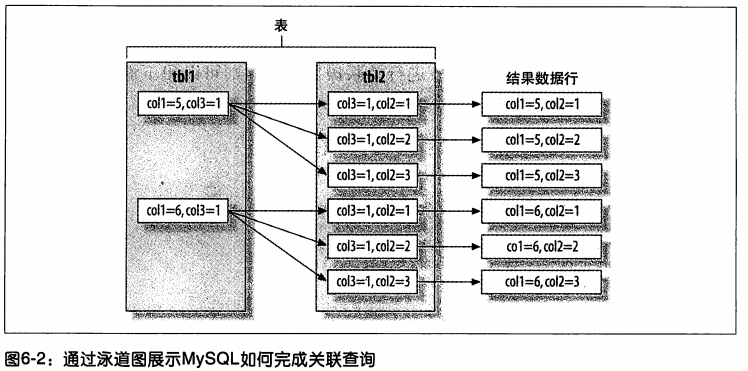
-
执行计划
-
mysql生成查询的一颗指令树,然后通过存储引擎执行完成这颗指令树并返回结果
-
mysql的执行计划是一颗左侧深度优先的树
-
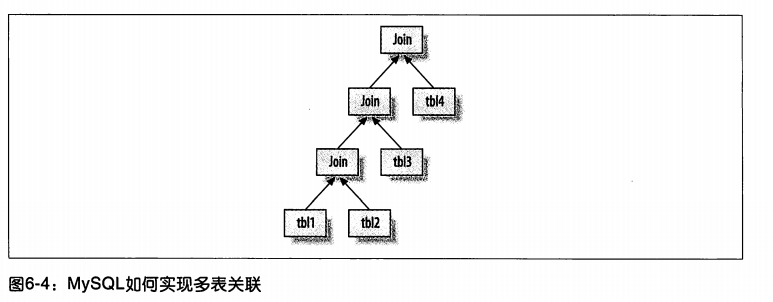
-
关联查询优化器
-
关联查询优化器通过评估不同顺序时的成本来选择一个代价最小的关联顺序
-
排序优化
-
单次传输排序
-
先读取查询所需要的所有列,然后再根据给定的列进行排序,最后直接排序结果
-
查询执行引擎
-
返回结果给客户端
-
查询优化器的局限性
-
关联子查询
-
union的限制
-
如果希望union的各个字句能够根据limit只取部分结果集,或者希望能够先排好序再合并结果集的话,就需要在union的各个子句中分别使用这些子句
-
索引合并优化
-
当where条件的子句中包含多个复杂条件的时候,mysql能够访问单个表的多个索引以合并和交叉过滤的方式来定位需要查找的行
-
等值传递
-
并行执行
-
哈希关联
-
松散索引扫描
-
最大值和最小值优化
-
在同一个表上查询和更新
-
查询优化器的提示(hint)
-
优化特定类型的查询
-
优化count()查询
-
count()的作用
-
count()是一个特殊的函数,有两种不同的作用:它可以统计某个列值的数量也可以统计行数 count不统计null
-
优化关联查询
-
确保on或者using子句中的列上有索引
-
确保任何的group by和order by中的表达式只涉及到一个表中的列,这样才有可能使用索引来优化这个过程
-
优化子查询
-
优化group by 和distinct
-
优化limit分页
-
优化sql_calc_found_rows
-
优化union查询
-
静态查询分析
-
使用用户自定义变量
-
用户自定义变量是一个用来存储内容的临时容器,在连接mysql的整个过程中都一直存在
-
下列场景不能使用
-
使用自定义变量的查询,无法使用查询缓存
-
不能在使用常量或者标识符的地方使用自定义变量
-
用户自定义变量的生命周期是在一个连接中有效,所以不能用他们来做连接间的通信
-
如果使用连接池或者持久化连接,自定义变量可能让看起来毫无关联的代码发生交互
-
不能显式地声明自定义变量的类型
-
mysql优化器在某些场景下可能会将这些变量优化掉,这可能导致代码不按预想的方式运行
-
赋值的顺序和赋值的时间点并不总是固定的
-
赋值符号:=的优先级非常低,所以,赋值表达式应该使用明确的括号
-
使用未定义的变量不会产生任何语法错误
-
优化排名语句
-
避免重复查询刚刚更新的数据
-
统计更新插入的数值
-
确定取值的顺序
-
编写偷懒的union
-
用户自定义变量的其他用处
-
查询运行时计算总数和平均值
-
模拟group 语句中的函数first()和last()
-
对大量数据做一些数据计算
-
计算一个大表的md5散列值
-
编写一个样本处理函数,当样本中的数值超过某个边界值的时候将其变成0
-
模拟读/写游标
-
在show语句的where子句中加入变量值