pandas层次化索引
# 导入模块,将其别名
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt一. 创建多层行索引
1、 隐式构造
1)最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组,Series也可以创建多层索引。
s = Series(np.random.randint(0,150,size=10),index=list('qwertyuiop'))# 输出
q 131
w 80
e 31
r 144
t 31
y 87
u 83
i 40
o 102
p 36
dtype: int32s = Series(np.random.randint(0,150,size=6),index=[['a','a','b','b','c','c'],['期中','期末','期中','期末','期中','期末']])# 输出
a 期中 59
期末 43
b 期中 28
期末 99
c 期中 92
期末 58
dtype: int32df = DataFrame(s,columns=['python'])
2)DataFrame建丽2级列索引
df1 = DataFrame(np.random.randint(0,150,size=(4,6)),
index = list('东南西北'),
columns=[['python','python','math','math','En','En'],['期中','期末','期中','期末','期中','期末']])
2、 显示构造pd.MultiIndex
1)使用数组构造
df2 = DataFrame(np.random.randint(0,150,size=(4,6)),
index = list('东南西北'),
columns=[['python','python','math','math','En','En'],['期中','期末','期中','期末','期中','期末']])
2)使用tuple构造
df3 = DataFrame(np.random.randint(0,150,size=(4,6)),
index = list('东南西北'),
columns =pd.MultiIndex.from_tuples([('python','期中'),('python','期末'),
('math','期中'),('math','期末'),
('En','期中'),('En','期末')]))
3)使用product构造(推荐)
df4 = DataFrame(np.random.randint(0,150,size=(8,12)),
columns = pd.MultiIndex.from_product([['模拟考','正式考'],
['数学','语文','英语','物理','化学','生物']]),
index = pd.MultiIndex.from_product([['期中','期末'],
['雷军','李斌'],
['测试一','测试二']]))
二. 多层索引对象的索引与切片操作
1、Series的操作
注意:对于Series来说,直接中括号[]与使用.loc()完全一样,推荐使用中括号索引和切片。
s = Series(np.random.randint(0,150,size=6),index=[['a','a','b','b','c','c'],['期中','期末','期中','期末','期中','期末']])# 输出
a 期中 59
期末 43
b 期中 28
期末 99
c 期中 92
期末 58
dtype: int32s['a','期中']
# 输出
59s[['a','b']] #取多层的外层索引时,内层索引不可用#输出
a 期中 59
期末 43
b 期中 28
期末 99
dtype: int32s['a'][['期中','期末']]['期中']
# 输出
59s.loc['a']
# 输出
期中 59
期末 43
dtype: int32s.iloc[:5] #iloc计算的事最内层索引
# 输出
a 期中 59
期末 43
b 期中 28
期末 99
c 期中 92
dtype: int322、DataFrame操作
(1) 可以直接使用列名称来进行列索引
(2) 使用行索引需要用ix(),loc()等函数
推荐使用loc()函数
注意:在对行索引的时候,若一级行索引还有多个,对二级行索引会遇到问题!也就是说,无法直接对二级索引进行索引,必须让二级索引变成一级索引后才能对其进行索引!
df4 = DataFrame(np.random.randint(0,150,size=(8,12)),
columns = pd.MultiIndex.from_product([['模拟考','正式考'],
['数学','语文','英语','物理','化学','生物']]),
index = pd.MultiIndex.from_product([['期中','期末'],
['雷军','李斌'],
['测试一','测试二']]))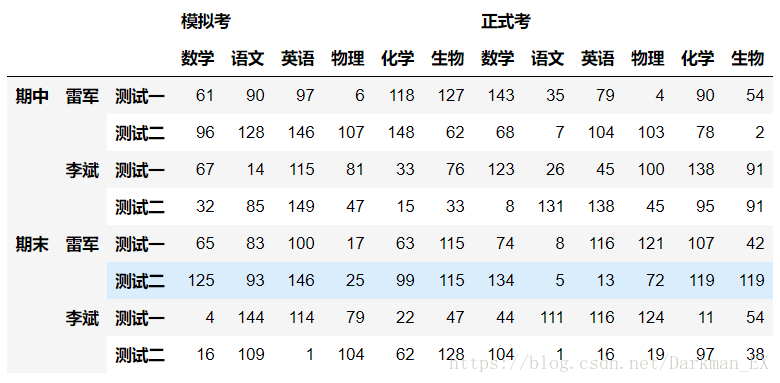
df4['模拟考'][['语文','数学']]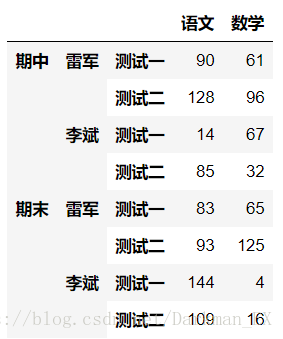
df4.loc['期中','雷军','测试一']['模拟考','数学']
# 输出
61df4.loc['期中','雷军','测试一']
# 输出
模拟考 数学 61
语文 90
英语 97
物理 6
化学 118
生物 127
正式考 数学 143
语文 35
英语 79
物理 4
化学 90
生物 54
Name: (期中, 雷军, 测试一), dtype: int32df4.iloc[0] #iloc是只取最内层的索引的
模拟考 数学 61
语文 90
英语 97
物理 6
化学 118
生物 127
正式考 数学 143
语文 35
英语 79
物理 4
化学 90
生物 54
Name: (期中, 雷军, 测试一), dtype: int32df4['正式考']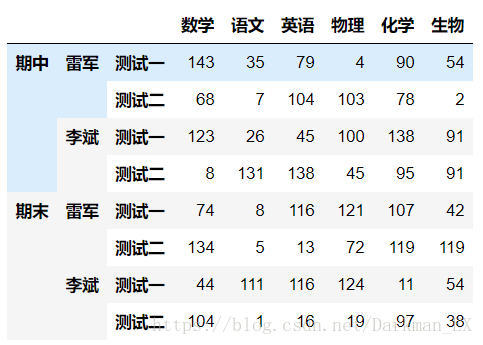
注意:列索引从列开始取,必须一层层取,取完列索引,才可以取行索引,先取行索引同理。