层次化索引(hierarchical indexing)是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低纬度处理高纬度数据。
Series
data=pd.Series(np.random.randn(10),
index=[list('aaabbbccdd'),list('1231231223')])
# a 1 -0.264274
# 2 0.623079
# 3 -0.382485
# b 1 -0.126583
# 2 0.166526
# 3 -0.029227
# c 1 -0.377238
# 2 1.856859
# d 2 -1.154921
# 3 -0.073246
# dtype: float64
data.index
# MultiIndex([('a', '1'),
# ('a', '2'),
# ('a', '3'),
# ('b', '1'),
# ('b', '2'),
# ('b', '3'),
# ('c', '1'),
# ('c', '2'),
# ('d', '2'),
# ('d', '3')],
# )
data['b']
# 1 -0.126583
# 2 0.166526
# 3 -0.029227
data['b':'c'] # data.ix[['b','c']]
# b 1 -0.126583
# 2 0.166526
# 3 -0.029227
# c 1 -0.377238
# 2 1.856859
data.ix[['b','d']]
# b 1 -0.126583
# 2 0.166526
# 3 -0.029227
# d 2 -1.154921
# 3 -0.073246
# 数据重塑
data.unstack()
| 1 | 2 | 3 | |
| a | -2.623162 | 0.625838 | 0.071932 |
| b | 1.041243 | 0.507749 | -1.062712 |
| c | 0.517531 | 0.447269 | NaN |
| d | NaN | 1.485503 | 0.944937 |
# 数据重塑逆运算
data.unstack().stack()
# a 1 -2.623162
# 2 0.625838
# 3 0.071932
# b 1 1.041243
# 2 0.507749
# 3 -1.062712
# c 1 0.517531
# 2 0.447269
# d 2 1.485503
# 3 0.944937
# dtype: float64
DataFrame
frame=pd.DataFrame(np.arange(12).reshape(4,3),
index=[list('aabb'),list('1212')],
columns=[['ohio','ohio','colorado'],
['green','red','green']])
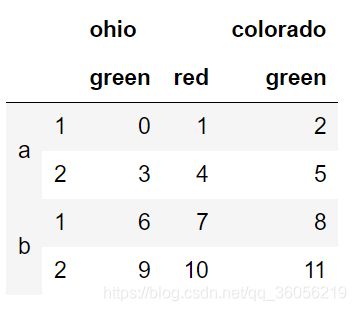
frame.index.names=['keys1','keys2']
frame.columns.names=['state','color']

frame['ohio']

重排分级顺序
有时,我们需要重新调整某条轴上各个级别的顺序,或根据指定级别上的值对数据进行排序。swaplevel接受两个级别编号或名称,并返回一个互换了级别的新对象(但数据不会发生变化)。
frame.swaplevel('keys1','keys2')

根据级别汇总统计
frame.sum(level='keys2')
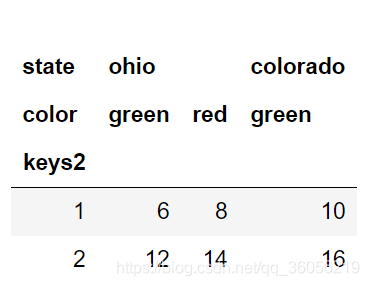
frame.sum(level='color',axis=1)
