Llama一直被誉为AI社区中最强大的开源大模型。然而,由于开源协议的限制,它一直不能被免费用于商业用途。然而,这一切在7月19日发生了改变,当Meta终于发布了大家期待已久的免费商用版本Llama2。Llama2是一个由Meta AI开发的预训练大语言模型,它可以接受任何自然语言文本作为输入,并生成文字形式的输出。Llama2-xb-chat是基于Llama2-xb在对话场景下的优化模型,目前在大多数评测指标上超过了其他开源对话模型,并且与一些热门的闭源模型(如ChatGPT、PaLM)的表现相当。
官方介绍

Meta发布的Llama 2模型系列包括70亿、130亿和700亿三种参数版本。此外,他们还训练了一个340亿参数的版本,但并未发布,只在技术报告中提到。据官方介绍,Llama 2与其前身Llama 1相比,训练数据增加了40%,上下文长度也翻了一番,并采用了分组查询注意力机制。具体来说,Llama 2预训练模型是在2万亿的token上训练的,而精调Chat模型则是在100万人类标记数据上训练的。
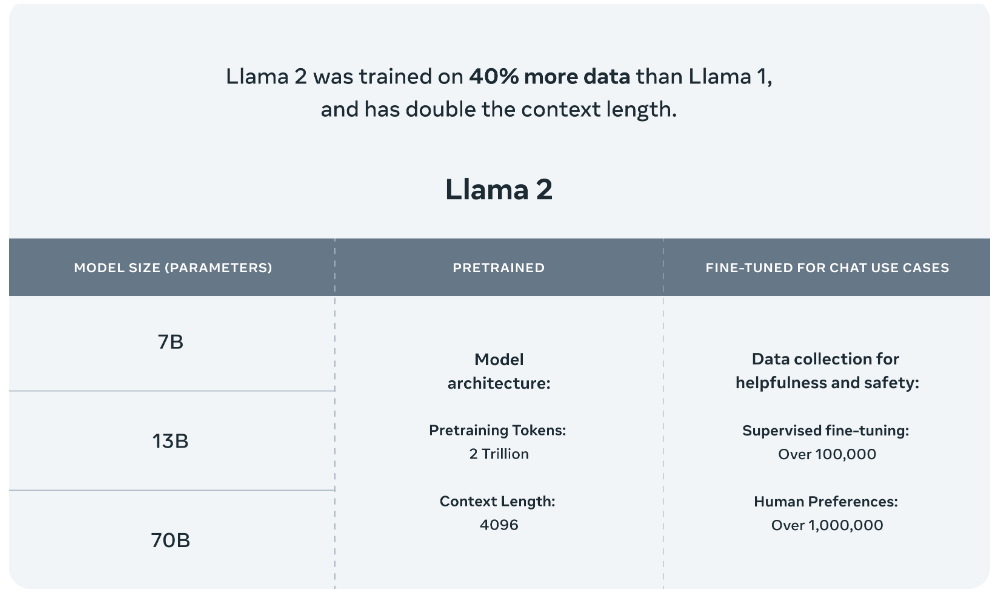
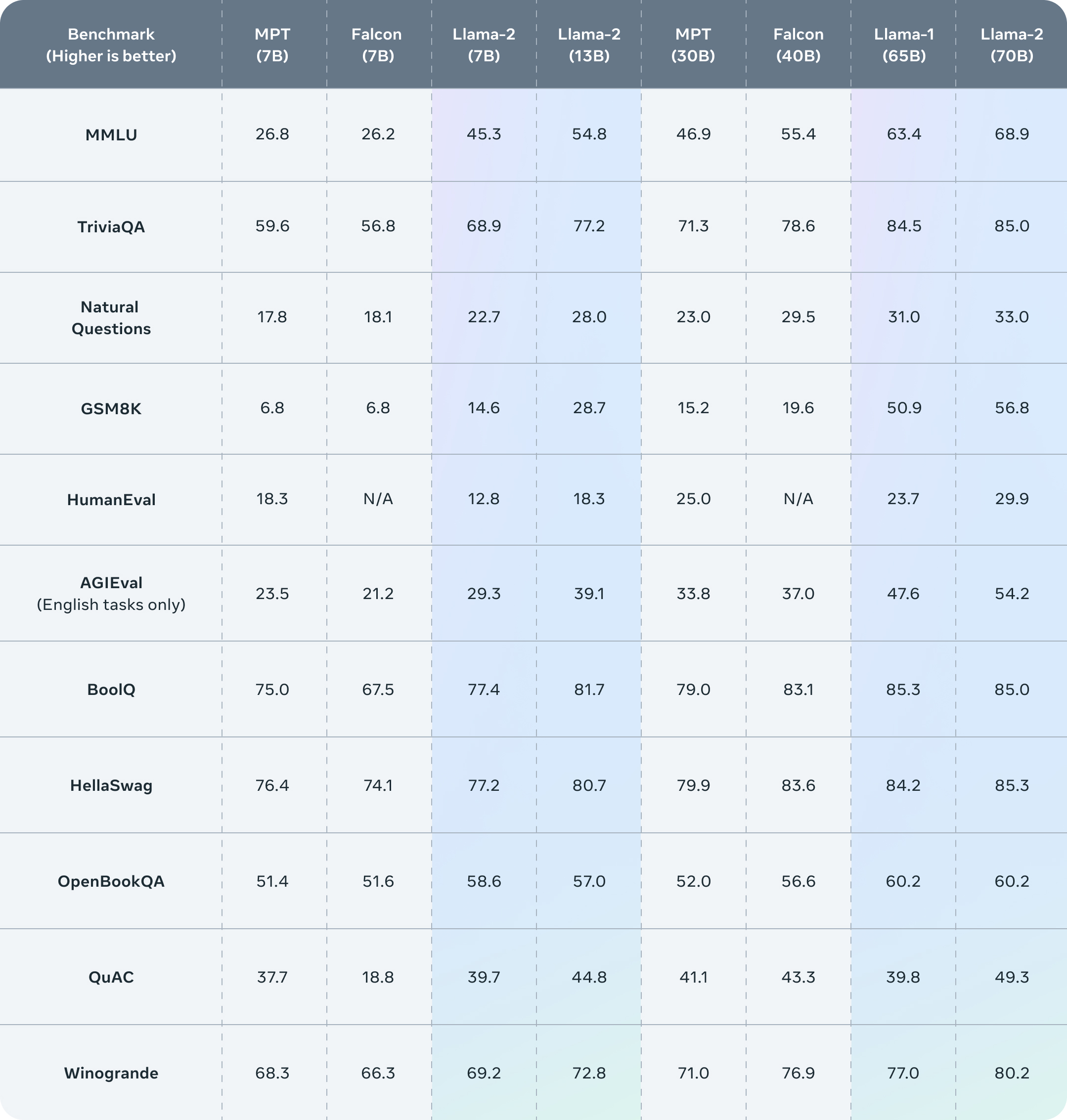
公布的测评结果显示,Llama 2在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
模型部署
Meta在Huggingface上提供了所有模型的下载链接:https://huggingface.co/meta-llama
预训练模型
Llama2预训练模型包含7B、13B和70B三个版本
| 模型名称 | 模型加载名称 | 下载地址 |
|---|---|---|
| Llama2-7B | meta-llama/Llama-2-7b-hf | 模型下载 |
| Llama2-13B | meta-llama/Llama-2-13b-hf | 模型下载 |
| Llama2-70B | meta-llama/Llama-2-70b-hf | 模型下载 |
Chat模型
Llama2-Chat模型基于预训练模型进行了监督微调,具备更强的对话能力
| 模型名称 | 模型加载名称 | 下载地址 |
|---|---|---|
| Llama2-7B-Chat | meta-llama/Llama-2-7b-chat-hf | 模型下载 |
| Llama2-13B-Chat | meta-llama/Llama-2-13b-chat-hf | 模型下载 |
| Llama2-70B-Chat | meta-llama/Llama-2-70b-chat-hf | 模型下载 |
阿里云机器学习平台PAI
机器学习平台PAI(Platform of Artificial Intelligence)面向企业客户及开发者,提供轻量化、高性价比的云原生机器学习,涵盖PAI-DSW交互式建模、PAI-Studio拖拽式可视化建模、PAI-DLC分布式训练到PAI-EAS模型在线部署的全流程。
PAI平台部署
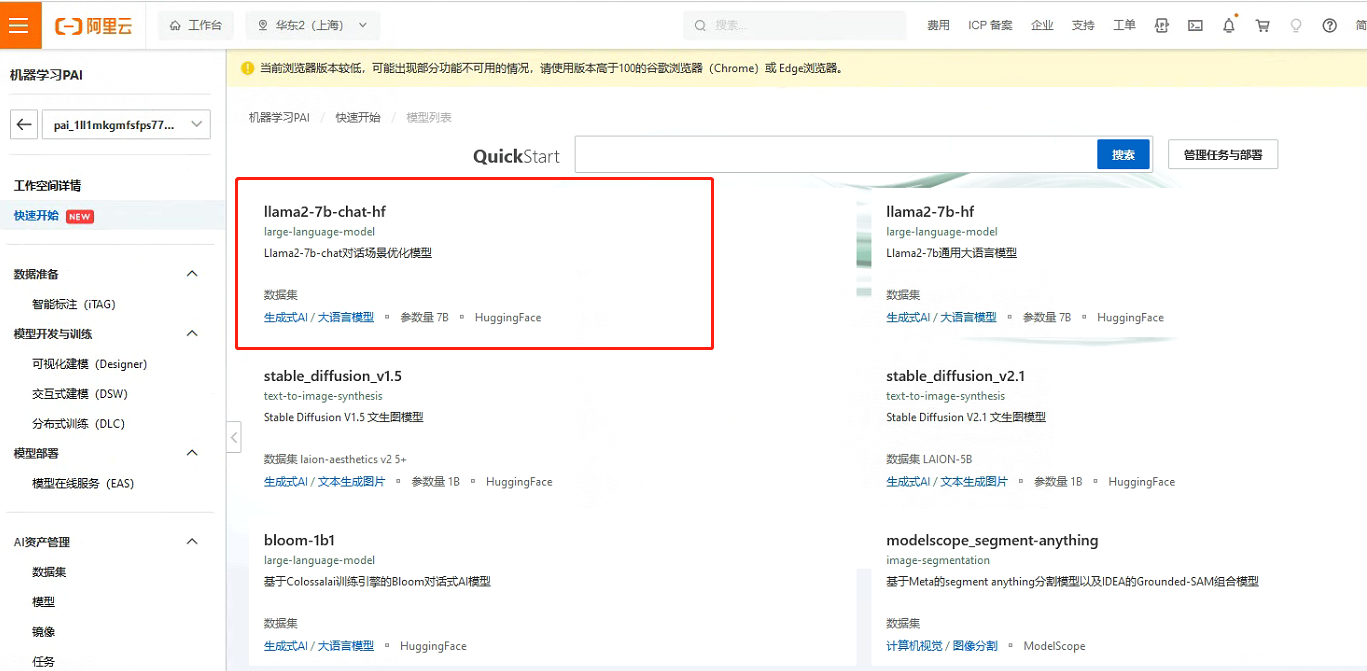
今天PAI平台也对Llama2-7b做了支持,提供了相关的镜像可以直接部署。模型部署后,用户可以在服务详情页面通过“查看Web应用”按钮来在网页端直接和模型推理交互。让我们来体验一下吧!
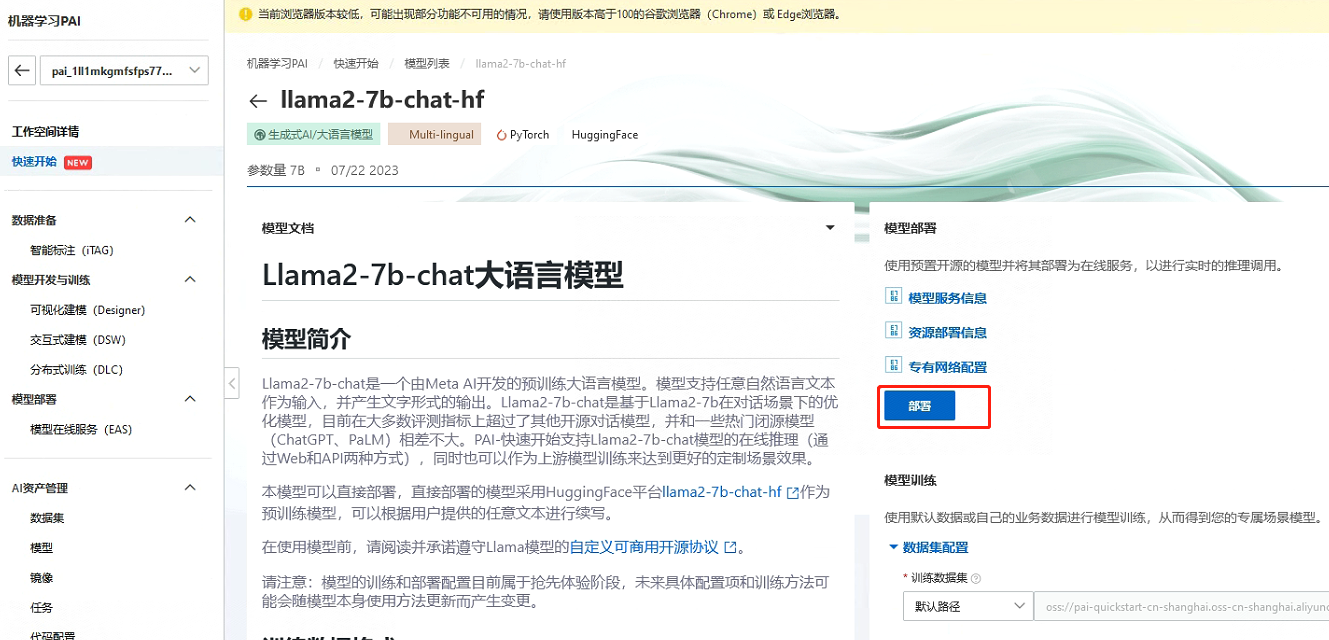
部署完成后:
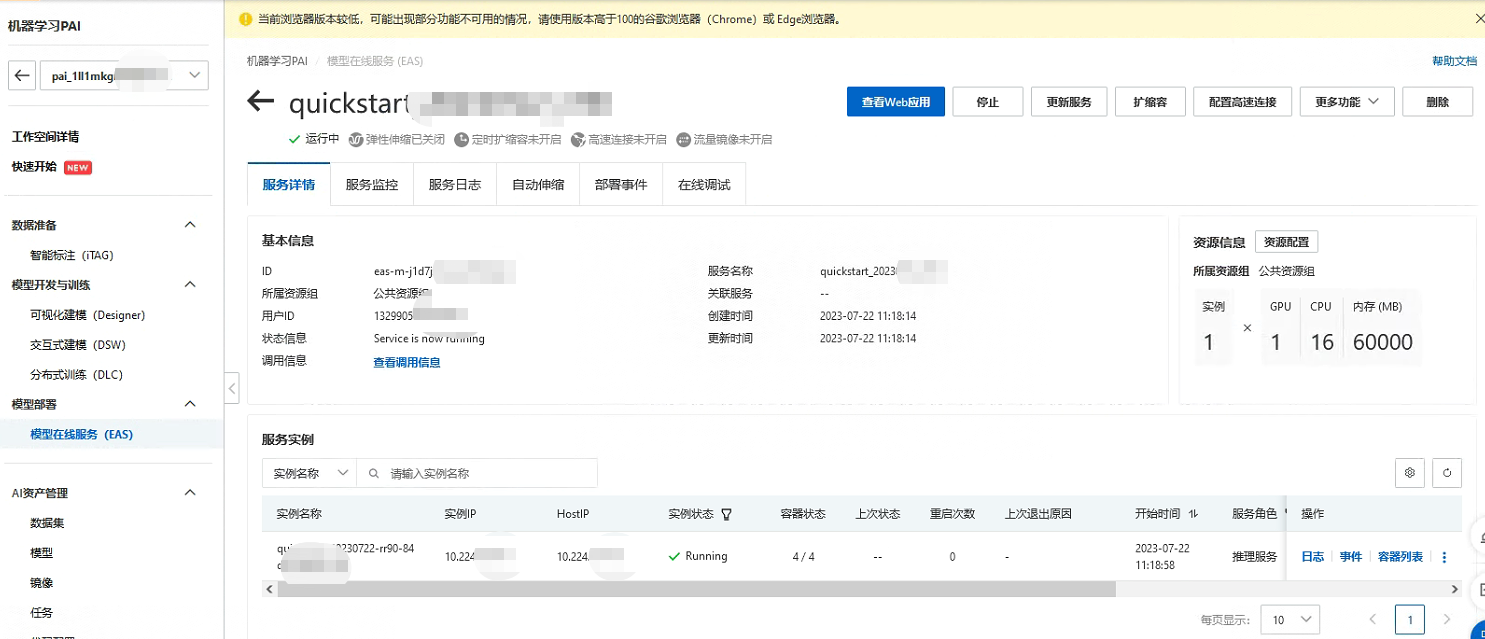
进入Web页面来测试一下:
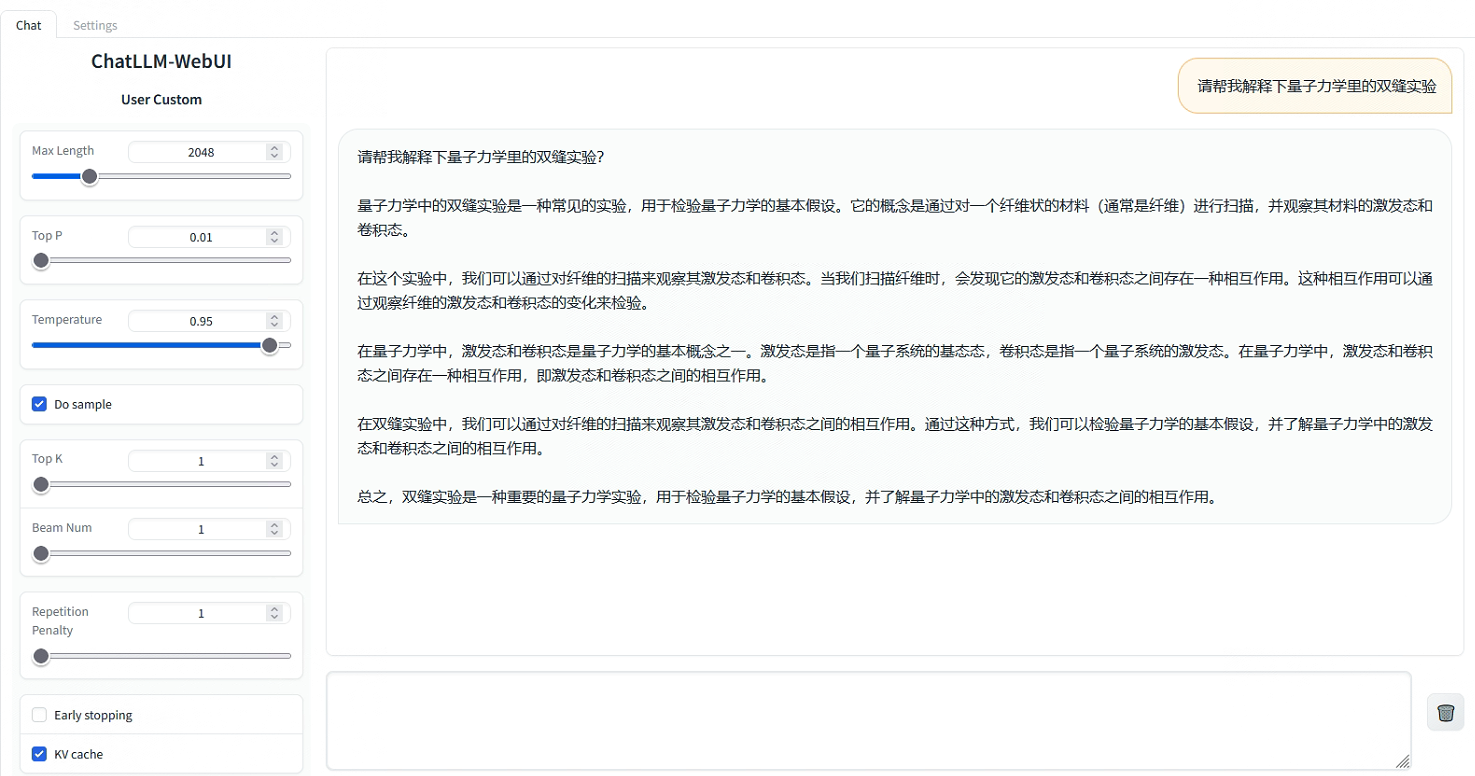
此外,也支持了通过API形式直接推理,但需要前往EAS服务并将服务运行命令更新为python api/api_server.py --port=8000 --model-path=<先前填入的model-path>。服务请求Body为输入text/plain格式文本或application/json格式,返回数据为text/html格式。以下为发送请求的格式示例:
{"input_ids": "List the largest islands which begin with letter 's'.","temperature": 0.8,"max_length": 5120,"top_p": 0.9}
API详情
LLAMA2模型API调用需"申请体验"并通过后才可使用,否则API调用将返回错误状态码。以下示例展示了调用LLAMA2模型对一个用户指令进行响应的代码。
Python
# For prerequisites running the following sample, visit https://help.aliyun.com/document_detail/611472.html
from http import HTTPStatus
from dashscope import Generation
def simple_sample():
# 模型可以为模型列表中任一模型
response = Generation.call(model='llama2-7b-chat-v2',
prompt='Hey, are you conscious? Can you talk to me?')
if response.status_code == HTTPStatus.OK:
print('Result is: %s' % response.output)
else:
print('Failed request_id: %s, status_code: %s, code: %s, message:%s' %
(response.request_id, response.status_code, response.code,
response.message))
if __name__ == '__main__':
simple_sample()
响应示例
{"text": "Hey, are you conscious? Can you talk to me?\n[/Inst: Hey, I'm not sure if I'm conscious or not. I can't really feel anything or think very clearly. Can you tell me"}
HTTP调用接口
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation' \
--header 'Authorization: Bearer <your-dashscope-api-key>' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama2-7b-v2",
"input":{
"prompt":"Hey, are you conscious? Can you talk to me?"
}
}'
响应示例
{
"output":{
"text":"Hey, are you conscious? Can you talk to me?\nLeaders need to be conscious of what’s going on around them, and not just what’s happening within their own heads.\nThis means listening to your team."
},
"request_id":"fbd7e41a-363c-938a-81be-8ae0f9fbdb3d"
}
随着时间的推移,基于Llama2开源模型的应用预计将在国内如雨后春笋般涌现。这种趋势反映了从依赖外部技术向自主研发的转变,这不仅能满足我们特定的需求和目标,也能避免依赖外部技术的风险。因此,我们更期待看到优秀的、独立的、自主的大模型的出现,这将推动我们的AI技术的发展和进步。
更深入的内容后续学习后再总结吧