目录
本篇博客详细讲解常用的几个方法,分别是二分查找和冒泡排序法
一、二分查找
二分查找,意思就是每次都分为两部分,将查找的数字和中间数字相比,判断大小后确定所查找数字在其中的一部分,接着在这部分数字中继续比较分为两部分查找,以此类推。
二分查找的运用比一个一个挨个找所需要的数字效率更高,但是需要注意的是:使用二分查找所满足的条件是必须是排序好的数组(本篇博客讲解的是顺序数组的二分查找法),否则无法运用二分查找。
下面是二分查找的代码部分:
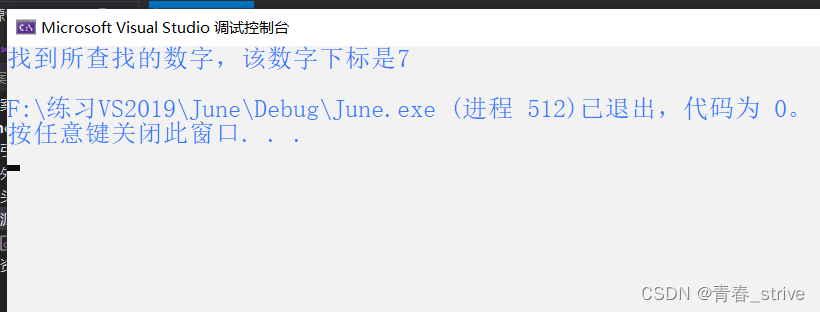
int main() { int arr[] = { 1,2,3,4,5,6,7,8,9,10 }; int n = 8; int sz = sizeof(arr) / sizeof(arr[0]); int left = 0; int right = sz - 1; while (left <= right) { int mid = left + (right - left) / 2; if (arr[mid] < n) { left = mid + 1; } else if (arr[mid] > n) { right = mid - 1; } else { printf("找到所查找的数字,该数字下标是%d\n", mid); break; } } if (left > right) { printf("未找到该数字!\n"); } return 0; }运行结果为下图:
二分查找的需注意的细节:
1、int n = 8;
这里的n就是所查找的数字
2、int sz = sizeof(arr) / sizeof(arr[0]);
sz算的是数组中有几个元素
这里的sizeof(arr)就是算出整个数组的大小,sizeof(arr[0])算的是数组首元素的大小,用整个数组的大小除以数组首元素的大小,即算出数组中有几个元素
3、int left = 0;int right = sz - 1;
令数组首元素的下标是left,数组最后一个元素的下标为right,以便于后续的比较
4、int mid = left + (right - left) / 2;
mid就是所需比较的数字下标,至于为什么不int mid = (left + right)/2,是因为如果left和right数值很大,有可能 left+right 会造成溢出的情况,所以使用int mid = left + (right - left) / 2;
5、if (left > right) printf("未找到该数字!\n");
while循环中left<=right,若直到最后都没有找到数字,那么left就会mid+1超过right,所以若判断left>right成立,则说明没有找到所查找数字,打印出“未找到该数字”
二、冒泡排序
冒泡排序,其实就是从数组的第一个元素开始,与其相邻的元素进行比较,如果不满足顺序就调换,接着与下一个元素相比较,以此类推......
冒泡排序是为了使数组中元素形成升序排序,从而完成更多需求
下面是冒泡排序的代码:
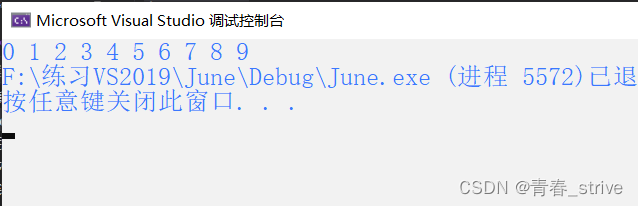
void bubble_sort(int* arr, int sz) { int i = 0; for (i = 0; i < sz - 1; i++) { int flag = 1; int j = 0; for (j = 0; j < sz - 1 - i; j++) { if (arr[j] > arr[j + 1]) { flag = 0; int tmp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = tmp; } } if (flag == 1) { break; } } } int main() { int arr[] = { 9,8,7,6,5,4,3,2,1,0 }; int sz = sizeof(arr) / sizeof(arr[0]); bubble_sort(arr, sz); int i = 0; for (i = 0; i < sz; i++) { printf("%d ", arr[i]); } return 0; }运行结果如下图:
冒泡排序需注意的细节:
1、int sz = sizeof(arr) / sizeof(arr[0]);
main函数中的这行代码和二分查找一样,都是计算数组中的元素个数
2、bubble_sort(arr, sz);
创建一个bubble_sort函数进行冒泡排序的具体操作,并传入数组首元素的地址arr,以及数组元素个数sz
3、void bubble_sort(int* arr, int sz)
int* arr是为了接受main函数中传入的arr,即数组首元素的地址,用整型指针int*接收
int sz就是接收main函数中所传入的数组元素个数
4、for (i = 0; i < sz - 1; i++)
首先对于第一个for循环,是针对总共需要循环几趟
至于为什么是循环sz-1次,因为比如说3个元素,第一趟是第一个元素和另外两个元素相比较,第二趟是第二元素和第三个元素比较,第三个元素已经不需要比较了,所以3个元素只需要循环2趟,以此类推,sz个元素需要循环sz-1趟
5、for (j = 0; j < sz - 1 - i; j++)
对于第二个for循环,是针对于每趟循环所需要的次数
为什么是循环sz - 1 - i次呢,因为因为本来是每个元素都比较sz-1次,但是这样会导致重复比较,第一个元素和后面的所有元素比较后,后面元素比较时就不需要再和第一个元素比较了,因此每趟循环次数除了sz-1这个正常的顺序外,再减去i即前面已经比较过的元素个数,就是每趟所需要比较的次数sz-1-i
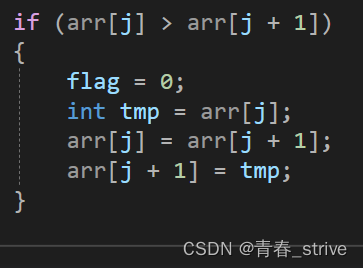
6、
这几行代码很好理解,若不满足顺序排序,令flag = 0;接着创建临时变量tmp,完成下标j和下标为j+1元素的调换
7、if (flag == 1) break;
这里的flag变量是为提升效率,主要是为了防止一个数组中元素本来就是顺序排序,但是却还是进行两次循环,费时费力,那么具体是怎么提升的呢?
在第一个for循环中定义了int flag = 1;在进行第二个for循环的第一次循环后,若flag仍然是1,就说明整个数组元素本身就符合顺序排序,因此,break跳出第一个for循环,整个循环结束,从而提高效率
若发生调换就说明该数组中元素并不是顺序排序,那么就将flag变为0,下方的if语句直接忽略即可,进行正常的冒泡排序即可。
本篇博客到此结束啦,如果对相关内容比较感兴趣的小伙伴,可以关注我的其他博客呦♪(^∇^*)