1、什么是分库分表
1.1、分表
将同一个库中的一张表(比如SPU表)按某种方式(垂直拆分、水平拆分)拆分成SPU1、SPU2、SPU3、SPU4…等若干张表,如下图所示:
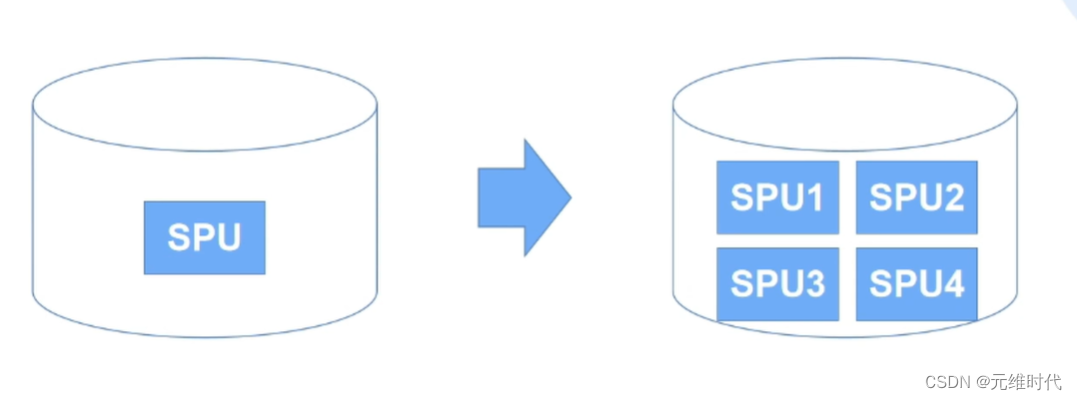
1.2、分库
在表数据不变的情况下,对数据库进行拆分,即将一个库中的若干张表按某种方式拆分出来,放到不同的数据中,如下图所示:
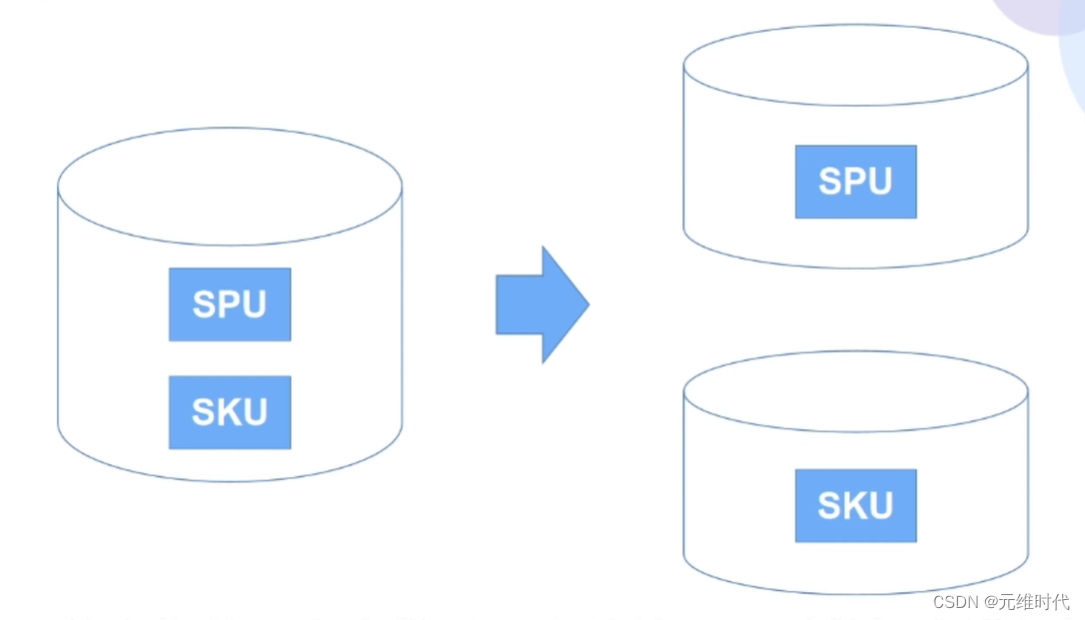
1.3、分库+分表
数据库的数量和表的数量都有变化,例如将一个数据库中的一张表(比如SPU表)拆分成SPU1、SPU2、SPU3、SPU4…等若干张表,并放到不同的数据里面,如下图所示:
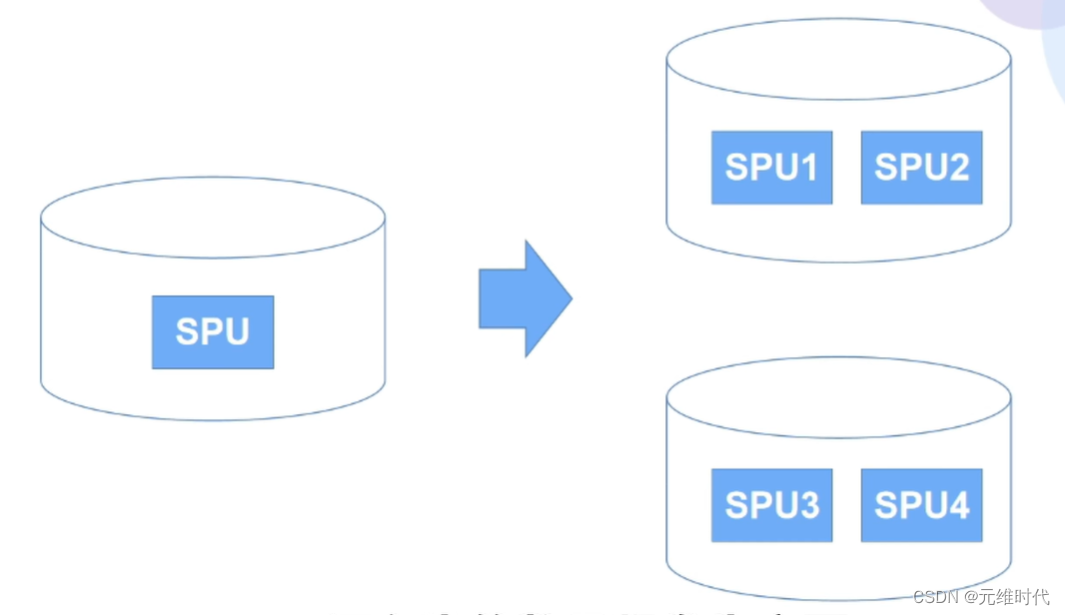
2、拆分方式
2.1、水平拆分
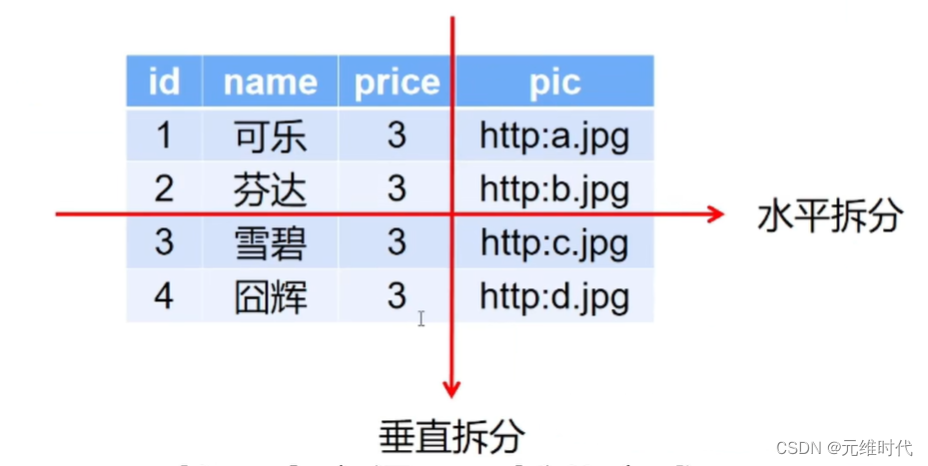
水平拆分指的是在整个表数据结构不发生变化的前提下,我们将一张表的数据拆分成多张表,如下图所示:
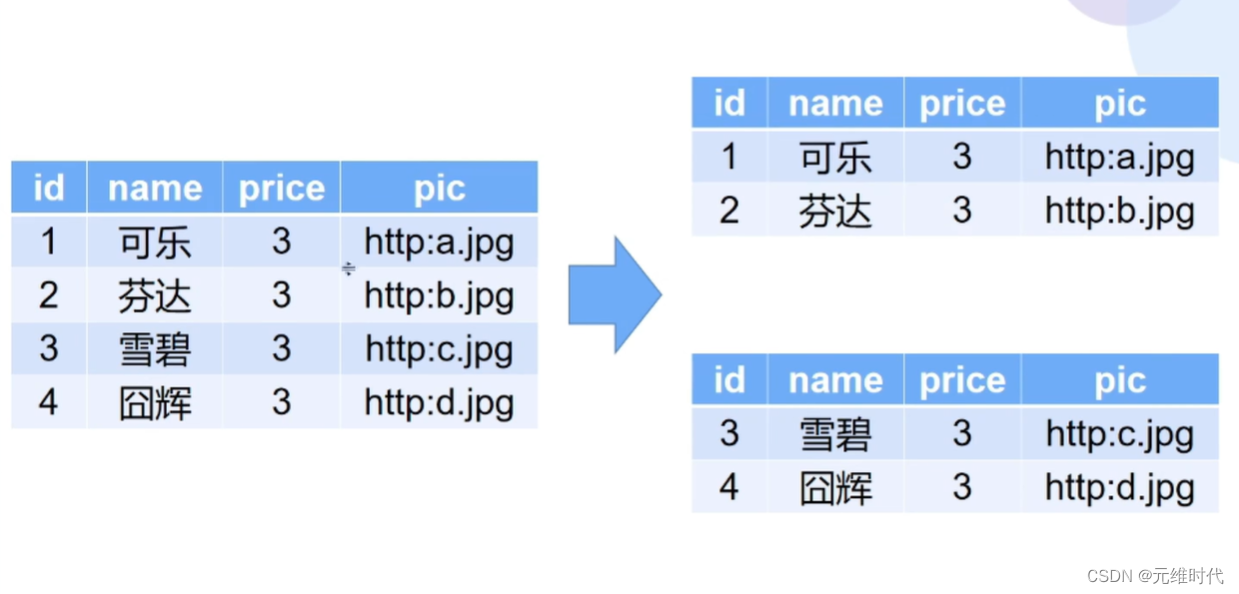
这样拆分完以后,单张表的数据量就降下来了,读写性能自然就上去了。
2.2、垂直拆分
垂直拆分指将本来放在一张表中的字段,按业务需求拆分开放到多张表中,如下图所示:
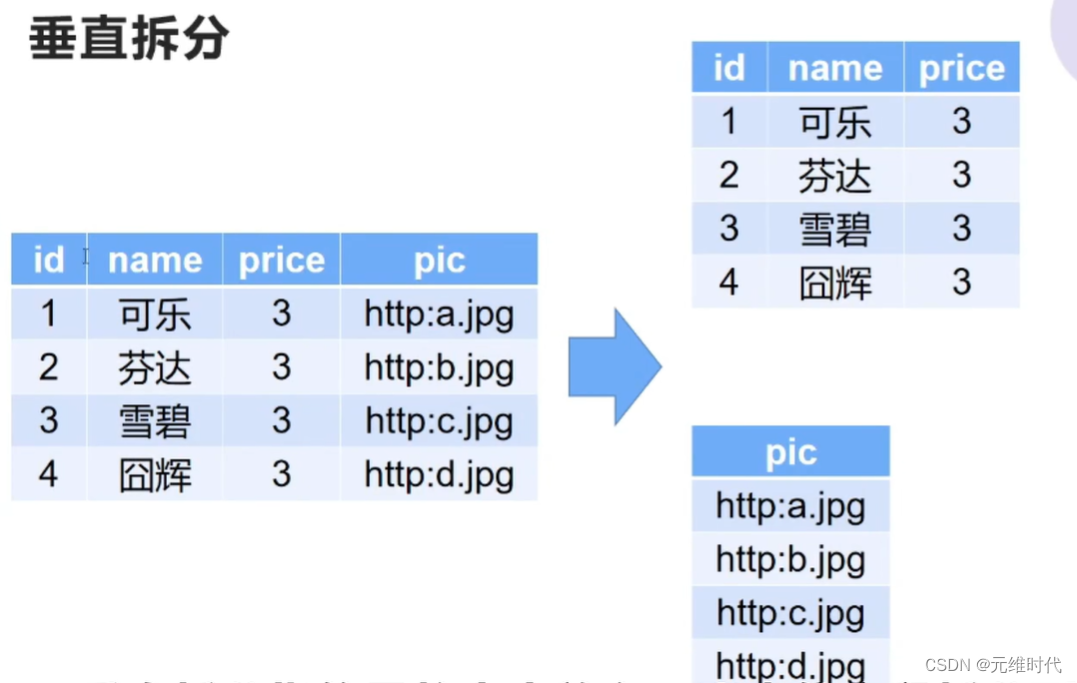
这样拆分完后,就将需要经常查询的数据单独放到一张表中了,性能也就提上去了。
2、何时进行分库分表?
当系统性能出现瓶颈,我们通过代码优化、加缓存、JVM性能调优、限流、搭建集群等常用的技术手段依然无法很好的解决问题时,就可以考虑采用分库分表来提高系统的性能。常见需要进行分表分表的场景有以下几点:
2.1、单表出现性能瓶颈
单表数据量较大,导致读写性能较慢。
2.2、单库出现性能瓶颈
- CPU压力过大(busy、load过高),导致读写性能较慢。
- 内存不足(缓存池命中率较低、磁盘读写IOPS过高),导致读写性能较慢。
- 磁盘空间不足,导致无法正常写入数据。
- 网络带宽不足,导致读写性能较慢。
3、如何选择分库、分表或者分库+分表
3.1、只分表
- 单表数据量较大,单表读写性能出现瓶颈。
- 经过评估单库的容量和性能可以支撑未来几年的数据量增长。
3.2、只分库
- 数据库(读)写压力较大,数据库出现存储性能瓶颈。
3.3、分库分表
- 单表数据量较大,单表读写性能出现瓶颈。
- 数据库(读)写压力较大,数据库出现存储性能瓶颈。
4、分库分表带来的问题
4.1、分布式唯一ID
分库分表后,一张表被拆成了多张表,数据库的自增ID无法保证数据的唯一性了,因此需要映入一种方案来保证数据ID的唯一性。成熟的解决方案有以下几个:
4.1.1、UUID
优点:本地生成,性能高。
缺点:
- 更占用存储空间,一般为长度36的字符串。
- 不适合作为MySQL主键:无序性会导致磁盘随机IO、叶分裂等问题;普通索引需要存储主键值,导致B+树“变高”,IO次数变多。
- 基于MAC地址的送算法可能会导致MAC地址泄漏。
4.1.2、雪花算法
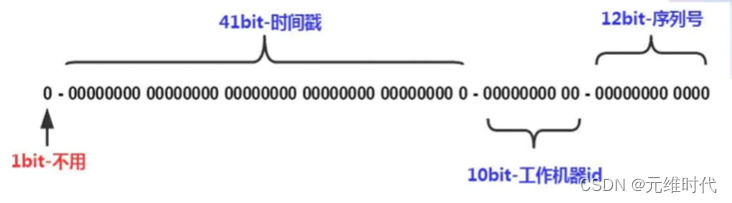
- 41bit时间戳:可用69年
- 10bit工作机器:可部署1024台服务器
- 12bit序列号:每毫秒可生成4096个ID,每秒也就是409万。
4.1.3、号段模式

4.2、分布式事务
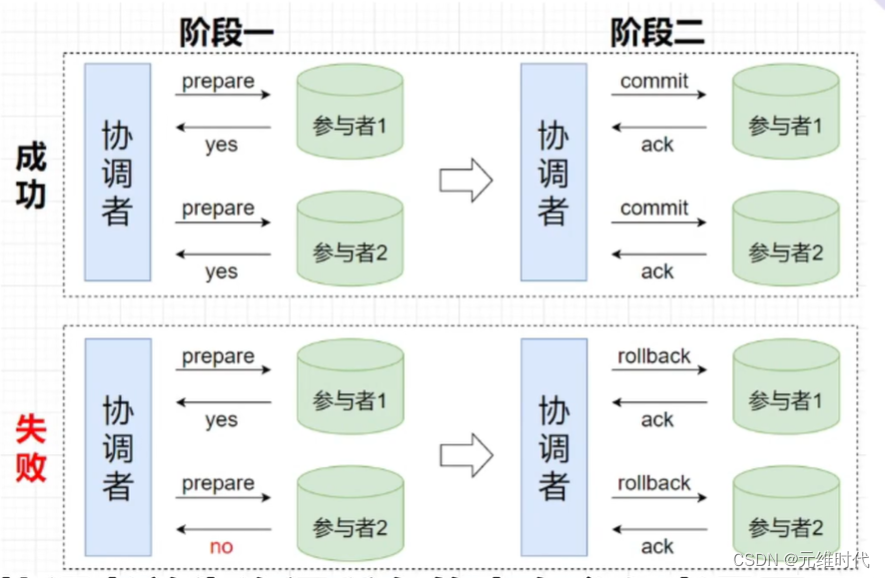
4.2.1、2PC
2PC 即两阶段提交协议,是将整个事务流程分为两个阶段,准备阶段(Prepare phase)、提交阶段(commit phase),2 是指两个阶段,P 是指准备阶段,C 是指提交阶段。
4.2.2、TCC
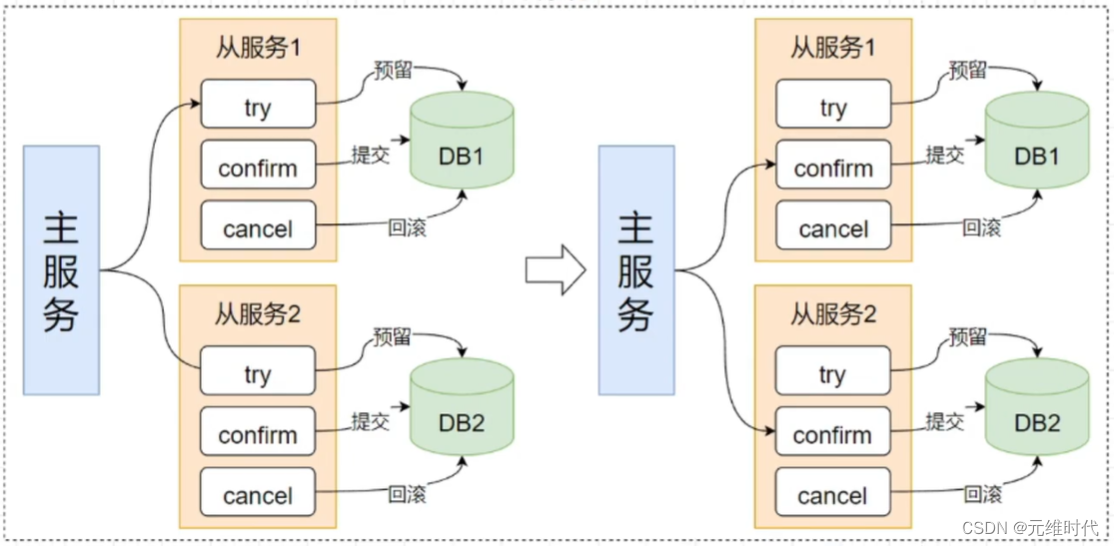
TCC(Try-Confirm-Cancel)是一种事务模型,其概念源自于Pat Helland的论文《Life beyond Distributed Transactions:an Apostate’s Opinion》。
TCC提出了一种基于业务层面的事务定义方式,通过由业务自身控制锁粒度,解决了复杂业务中跨表跨库等大颗粒度资源锁定的问题。
TCC将事务过程分为Try(尝试)、Confirm(确认)和Cancel(取消)三个阶段,每个阶段由业务代码控制,避免了长事务的问题,从而提高了性能。
TCC 的具体流程如下图所示:
4.2.3、常见的保证最终一致的处理方法
- 回滚
- 重试
- 监控
- 告警
- 幂等
- 对账
- 人工补偿
4.3、跨库JOIN/分页查询
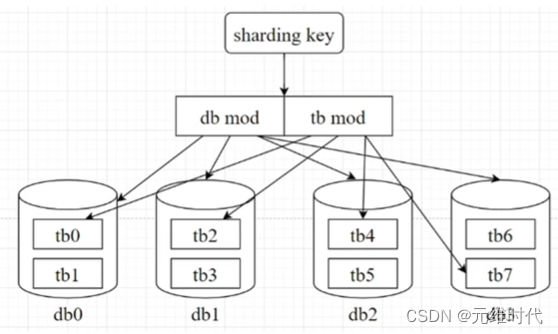
4.3.1、合适的分表字段(sharding key)
合理选择,避免大多数跨库查询
4.3.2、搜索引擎支持:ES
数据冗余到ES,使用ES支持复杂查询。
核心流程:
- 使用ES查询出关键字段,例如:门店id和商品id。
- 再使用关键字段去查询完整数据。
注意点: - ES只需要存储需要搜索的字段。
4.3.3、分开查询,内存中聚合
先查询出A表数据,然后根据A表的结果查询B表。
注意点:
- 查询出来的数据量
- 内存占用情况
4.3.4、冗余字段
A表查询需要B表的field1字段,则将B表的field1存储一份到A表上。
适用场景:只需要少量字段,则可以直接冗余。