1.为什么需要分库分表
- 单个表的数据量超过了千万甚至到了亿级别
- 对于MySQL来说,单个库只能存储在一台服务器中,单服务器的存储容量出现瓶颈
- 数据量的增加也占据了磁盘的空间,数据库在备份和恢复的时间变长
- 写入请求TPS很大,单个数据库无法处理更高的写入请求
2.垂直&水平分库分表
分库分表后,每个节点只保存部分的数据,这样可以有效地减少单个数据库节点和单个数据表中存储的数据量,在解决了数据存储瓶颈的同时也能有效地提升数据查询的性能。同时,因为数据被分配到多个数据库节点上,那么数据的写入请求也从请求单一主库变成了请求多个数据分片节点,在一定程度上也会提升并发写入的性能。
- 垂直分库分表
垂直拆分,顾名思义就是对数据库竖着拆分,也就是将数据库的表拆分到多个不同的数据库中,这样就可以缓解单个库中表数据量过多问题。垂直拆分的原则一般是按照业务类型来拆分,核心思想是专库专用,将业务耦合度比较高的表拆分到单独的库中。比如电商系统将订单表、购物车表、用户表、优惠卷表单独建库,即订单库、购物车库、用户库、优惠卷库。
垂直拆分后,把不同的业务的数据分拆到不同的数据库节点上,这样一旦数据库发生故障时只会影响到某一个模块的功能,不会影响到整体功能,从而实现了数据层面的故障隔离。 - 水平分库分表
对数据库进行垂直拆分是一种偏常规的方式,可以暂时缓解存储容量的瓶颈。但是数据库垂直拆分后依然不能解决某一个业务模块的数据大量膨胀的问题,一旦你的系统遭遇某一个业务库的数据量暴增,在这个情况下,可以选择水平分库分表的方案。
和垂直拆分的关注点不同,垂直拆分的关注点在于业务相关性,而水平拆分指的是将单一数据表按照某一种规则拆分到多个数据库和多个数据表中
水平拆分的规则一般有按字段的哈希值来拆分和按字段的区间来拆分: - 哈希值拆分适用于实体表,比如用户表、内容表等,一般按照这些实体表的 ID 字段来拆分。比如说我们想把用户表拆分成 16 个库,每个库是 64 张表,那么可以先对用户 ID 做哈希,哈希的目的是将 ID 尽量打散,然后再对 16 取余,这样就得到了分库后的索引值;对 64 取余,就得到了分表后的索引值。
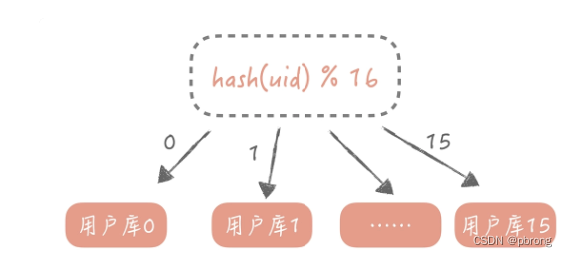
- 区间拆分适用于和时间存在关联关系的表,比如内容表中可能会要看昨天的内容,也可能会看一个月前发布的内容,这时就可以按照创建时间的区间来分库分表。般来说,列表数据可以使用这种拆分方式,比如一个人一段时间的订单,一段时间发布的内容。
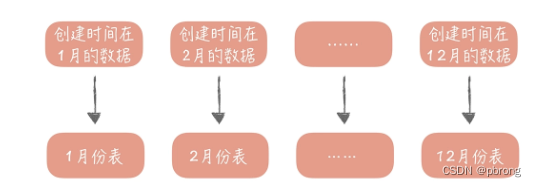
3.分片键的选择
数据库在分库分表之后,数据的访问方式也有了极大的改变,原先只需要根据查询条件到从库中查询数据即可,现在则需要先确认数据在哪一个库表中。
分库分表键,也叫做分区键,也就是我们对数据库做分库分表所依据的字段。之后所有的查询都需要带上这个字段,才能找到数据所在的库和表,否则就只能向所有的数据库和数据表发送查询命令。如果像上面说的要拆分成 16 个库和 64 张表,那么一次数据的查询会变成 16*64=1024 次查询,查询的性能肯定是极差的。
在用户库中我们使用 ID 作为分区键,这时如果需要按照昵称来查询用户时,你可以按照昵称作为分区键再做一次拆分,但是这样会极大地增加存储成本,如果以后我们还需要按照注册时间来查询时要怎么办呢?
最合适的思路是建立一个昵称和 ID 的映射表,在查询的时候要先通过昵称查询到 ID,再通过 ID 查询完整的数据,这个表也可以是分库分表的,也需要占用一定的存储空间,但是因为表中只有两个字段,所以相比重新做一次拆分还是会节省不少的空间的。通常使用ES存储模糊查询的内容,并映射到对应的 ID 中,这样就可以实现使用非分片键查询的需求。
4.全局唯一ID
在单库单表的场景下,我们可以使用数据库的自增字段作为 ID,因为这样最简单,对于开发人员来说也是透明的。但是当数据库分库分表后,使用自增字段就无法保证 ID 的全局唯一性了。分库分表之后,同一个逻辑表的数据被分布到多个库中,这时如果使用数据库自增字段作为主键,那么只能保证在这个库中是唯一的,无法保证全局的唯一性。那么假如你来设计用户系统的时候,使用自增 ID 作为用户 ID,就可能出现两个用户有两个相同的 ID,这是不可接受的。
一般来说可以通过发号器来解决全局唯一ID的生成问题。
Snowflake 的核心思想是将 64bit 的二进制数字分成若干部分,每一部分都存储有特定含义的数据,比如说时间戳、机器 ID、序列号等等,最终生成全局唯一的有序 ID。它的标准算法是这样的:
![[图片]](https://img-blog.csdnimg.cn/c4d762237d264996a305f253a099f1dd.png)
41 位的时间戳大概可以支撑 pow(2,41)/1000/60/60/24/365 年,约等于 69 年,对于一个系统是足够了。如果你的系统部署在多个机房,那么 10 位的机器 ID 可以继续划分为 2~3 位的 IDC 标示(可以支撑 4 个或者 8 个 IDC 机房)和 7~8 位的机器 ID(支持 128-256 台机器);12 位的序列号代表着每个节点每毫秒最多可以生成 4096 的 ID。
不同公司也会依据自身业务的特点对 Snowflake 算法做一些改造,比如说减少序列号的位数增加机器 ID 的位数以支持单 IDC 更多的机器,也可以在其中加入业务 ID 字段来区分不同的业务。比如1 位兼容位恒为 0 + 41 位时间信息 + 6 位 IDC 信息(支持 64 个 IDC)+ 6 位业务信息(支持 64 个业务)+ 10 位自增信息(每毫秒支持 1024 个号)。
对于发号器的使用可以分为嵌入式及单独服务式:
- 嵌入到业务代码里,也就是分布在业务服务器中。这种方案的好处是业务代码在使用的时候不需要跨网络调用,性能上会好一些,但是就需要更多的机器 ID 位数来支持更多的业务服务器。另外,由于业务服务器的数量很多,我们很难保证机器 ID 的唯一性,所以就需要引入 ZooKeeper 等分布式一致性组件来保证每次机器重启时都能获得唯一的机器 ID。
- 独立的服务部署,这也就是我们常说的发号器服务。业务在使用发号器的时候就需要多一次的网络调用,但是内网的调用对于性能的损耗有限,却可以减少机器 ID 的位数,如果发号器以主备方式部署,同时运行的只有一个发号器,那么机器 ID 可以省略,这样可以留更多的位数给最后的自增信息位。即使需要机器 ID,因为发号器部署实例数有限,那么就可以把机器 ID 写在发号器的配置文件里,这样可以保证机器 ID 唯一性,也无需引入第三方组件了。
5.替代方案:NoSQL
对于存储服务来说,我们一般会从两个方面对它做改造:
- 提升它的读写性能,尤其是读性能,因为我们面对的多是一些读多写少的产品。比方说,你离不开的微信朋友圈、微博和淘宝,都是查询 QPS 远远大于写入 QPS。常规做法是采用主从复制+读写分离的模式来水平承载读压力。
- 增强它在存储上的扩展能力,从而应对大数据量的存储需求。常规做法是采用分库分表来均分写压力和数量。
比如,在微博项目中关系的数据量达到了千亿,那么即使分隔成 1024 个库表,每张表的数据量也达到了亿级别,并且关系的数据量还在以极快的速度增加,即使你分隔成再多的库表,数据量也会很快增加到瓶颈。这个问题用传统数据库很难根本解决,因为它在扩展性方面是很弱的,这时,就可以利用 NoSQL,因为它有着天生分布式的能力,能够提供优秀的读写性能,可以很好地补充传统关系型数据库的短板。
对于海量数据存储来说,可以考虑使用MongoDB及HBase,前者具备副本集和分片,自身就可以支持水平拓展及读写分离,而后者基于HDFS进行数据存储,同样具有良好的水平拓展能力。
6.总结
- 如果在性能上没有出现瓶颈,尽量不要分库分表
- 如果要分库分表,尽量一次做到位,预估后续几年的数据量增长来进行分库分表(比如拆分1024个库,1024张表等)
- 使用分库分表后,跨库JOIN及查询总数时不能直接给予数据库实现,可以先捞出数据来在程序逻辑中实现
- 分库分表后,可以将查询条件与分片键存储在ES中,通过ES检索到分片键后,再通过分片键查询分片库表
- 全局唯一ID不能使用自增的模式,而应该使用全局唯一ID生成器来生成ID(通常基于雪花算法进行优化,支持更多的服务集群及机器数量)
- 许多NoSQL如MongoDB、HBase等都有良好的水平拓展能力,可以基于这个NoSQL来存储海量数据,替换掉MySQL