在学习LLAMA2的generate源码之前,先介绍Temperature超参数及sample_top_p的原理。
Temperature
Temperature 是一个超参数,可用于控制生成语言模型中生成文本的随机性和创造性。用于调整模型的softmax输出层中预测词的概率。
softmax函数:
p ( x i ) = e x i ∑ j = 1 V e x j p\left(x_i\right)=\frac{e^{x_i}}{\sum_{j=1}^V e^{x_j}} p(xi)=∑j=1Vexjexi
Temperature 参数(T)添加到softmax函数:
p ( x i ) = e x i T ∑ j = 1 V e x j T p\left(x_i\right)=\frac{e^{\frac{x_i}{T}}}{\sum_{j=1}^V e^{\frac{x_j}{T}}} p(xi)=∑j=1VeTxjeTxi
Temperature参数通常设置为 0.1 到 1.0 之间(T=1时形变为标准的Softmax函数),下图分别显示了 x i / T x_i/T xi/T在5:0.5和5:0.1时的图像(紫线为softmax,黑线为添加T参数的softmax),可以看到:
-
当T值更大时,函数图像会变的更加的平缓,预测词的概率被拉平,这意味着所有词被选择的可能性更大。 这会产生更有创意和多样化的文本,因为模型更有可能生成不寻常或意想不到的词。
-
当T值更小时,函数图像会变的更加的陡峭,预测词的概率会变尖锐,这意味着选择最有可能的词的概率更高。 这会产生更保守和可预测的文本,因为模型不太可能生成意想不到或不寻常的词。
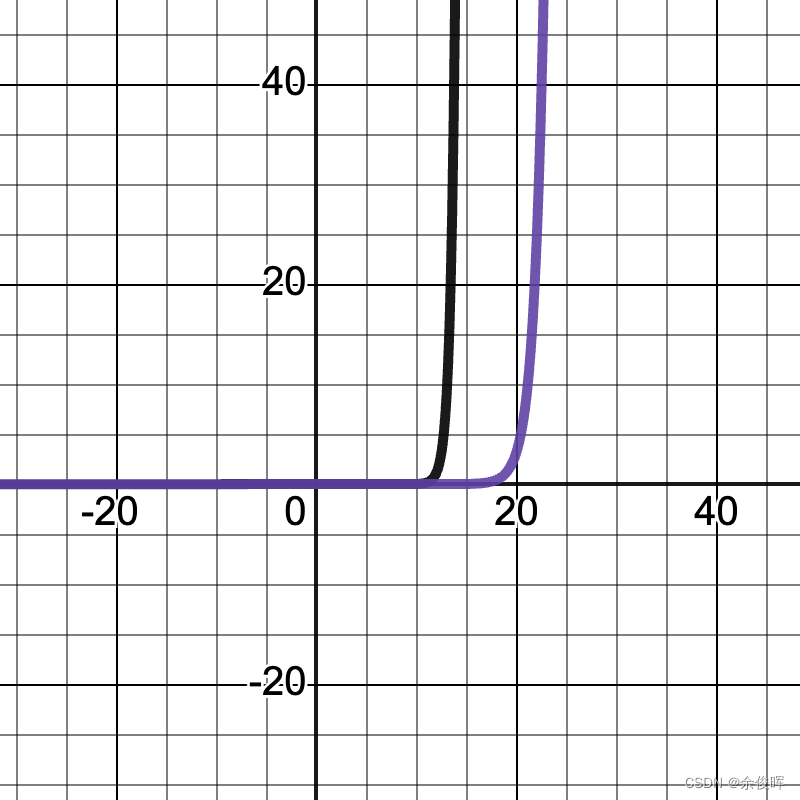
x i / T x_i/T xi/T=5:0.5
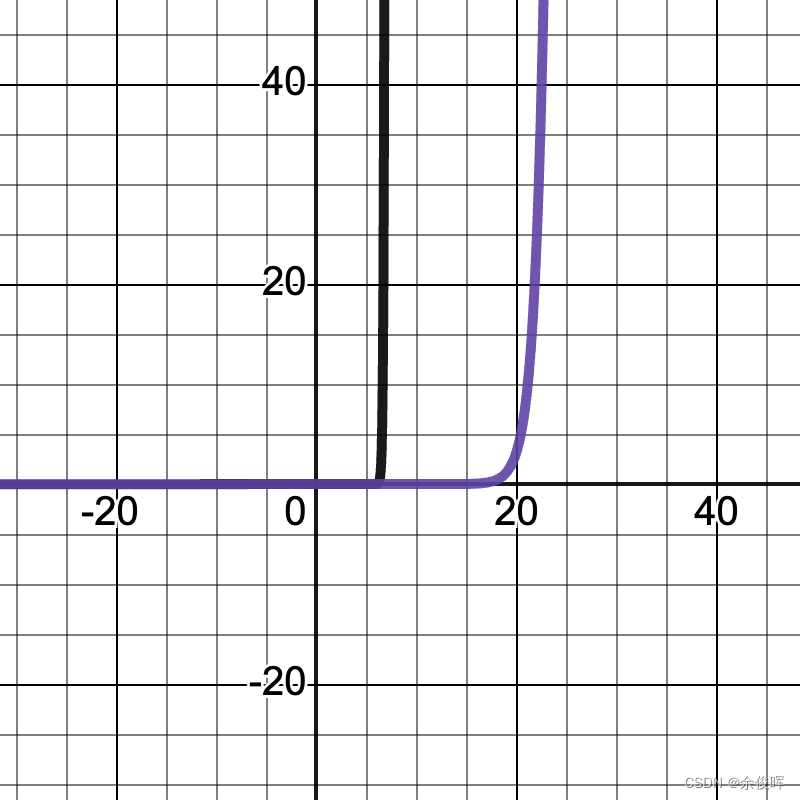
x i / T 5 = 0.1 x_i/T5=0.1 xi/T5=0.1
小结:Temperature 参数是文本生成模型中用于控制生成文本的随机性和创造性的一个重要的超参数。
sample_top_p
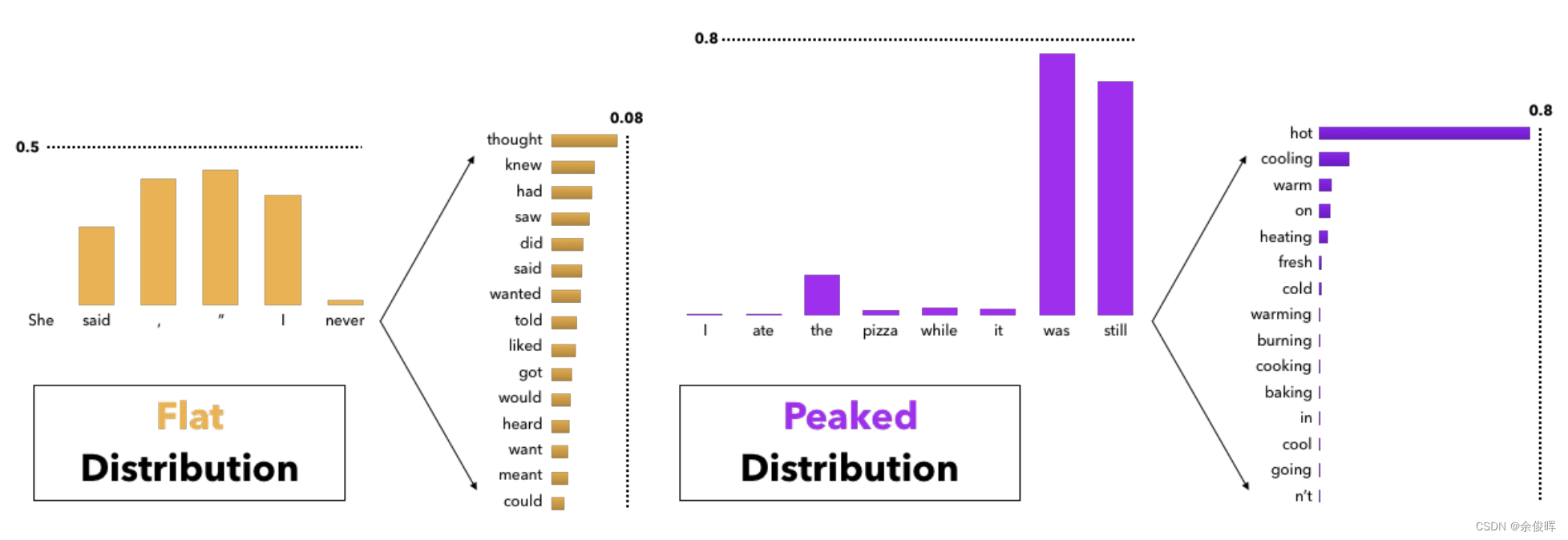
平缓和陡峭的概率分布图-文献【2】
采样意味着根据当前条件概率分布随机选择输出词 ,使用采样方法时文本生成本身不再是确定性的。对单词序列进行采样时的大问题: 模型通常会产生不连贯的乱码。在LLAMA2中,缓解这一问题的方式是通过top_p(也称:nucleus sampling)
def sample_top_p(probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
# 归一化
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
# multinomial为多项式抽样函数
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
return next_token_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
sample_top_p函数的作用:每个时间步,按照字出现的概率由高到底排序,当概率之和大于top-p的时候,就不取后面的样本了。然后对取到的这些字的概率重新归一化后,进行采样。这样做的好处是,既保证了质量,又增加了适当的随机性。
核心函数generate()
这一块直接在代码中进行注释:
def generate(
self,
prompt_tokens: List[List[int]], # 输入的提示
max_gen_len: int, # 最大生成长度
temperature: float = 0.6, # 影响生成文本的随机性
top_p: float = 0.9, # 用于决定采样过程中保留的 token 集合的概率阈值
logprobs: bool = False, # 是否返回每个 token 的对数概率
echo: bool = False, # 是否返回输入的提示
) -> Tuple[List[List[int]], Optional[List[List[float]]]]:
# ---------------------------初始化长度为 total_len tokens张量,并填充 pad_id----------------------------------
params = self.model.params
bsz = len(prompt_tokens)
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
min_prompt_len = min(len(t) for t in prompt_tokens)
max_prompt_len = max(len(t) for t in prompt_tokens)
assert max_prompt_len <= params.max_seq_len
total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)
pad_id = self.tokenizer.pad_id
tokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")
# 将prompt_tokens中的token复制到tokens张量中。
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")
if logprobs:
# 创建一个与tokens相同形状的token_logprobs张量,并用0填充
token_logprobs = torch.zeros_like(tokens, dtype=torch.float)
prev_pos = 0
eos_reached = torch.tensor([False] * bsz, device="cuda")
input_text_mask = tokens != pad_id
# -------------------------------------------------------------
for cur_pos in range(min_prompt_len, total_len):
# 调用模型的forward方法获取logits
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if logprobs:
# 计算token level的logprobs
token_logprobs[:, prev_pos + 1: cur_pos + 1] = -F.cross_entropy(
input=logits.transpose(1, 2),
target=tokens[:, prev_pos + 1: cur_pos + 1],
reduction="none",
ignore_index=pad_id,
)
# 根据温度参数和top_p参数对logits进行softmax和采样,得到下一个token
if temperature > 0:
# sample_top_p函数对probs进行采样
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
# 将logits中概率最大的token作为下一个token。
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
# tokens张量更新
tokens[:, cur_pos] = next_token
eos_reached |= (~input_text_mask[:, cur_pos]) & (
next_token == self.tokenizer.eos_id
)
prev_pos = cur_pos
# 检查是否已经生成了所有的eos token,如果是则停止生成
if all(eos_reached):
break
if logprobs:
# token_logprobs列表化
token_logprobs = token_logprobs.tolist()
out_tokens, out_logprobs = [], []
for i, toks in enumerate(tokens.tolist()):
# cut to max gen len
# 对于 tokens 张量中的每一行(即每一个生成的序列),如果 echo 参数为假,则去掉提示部分
start = 0 if echo else len(prompt_tokens[i])
toks = toks[start: len(prompt_tokens[i]) + max_gen_len]
probs = None
if logprobs:
probs = token_logprobs[i][start: len(prompt_tokens[i]) + max_gen_len]
# cut to eos tok if any
# 存在结束标记,则去掉结束标记之后的部分
if self.tokenizer.eos_id in toks:
eos_idx = toks.index(self.tokenizer.eos_id)
toks = toks[:eos_idx]
probs = probs[:eos_idx] if logprobs else None
out_tokens.append(toks)
out_logprobs.append(probs)
# 返回生成的tokens和对数概率(如果logprobs参数为真)
return (out_tokens, out_logprobs if logprobs else None)
总结
本文介绍了Temperature以及sample_top_p的原理,并且阅读了LLAMA2的核心生成函数的源码。关于更多细节实现,请关注llama源码。
参考文献
【1】https://github.com/facebookresearch/llama/blob/main/llama/generation.py
【2】The Curious Case of Neural Text Degeneration