NoSQL相关知识
一、单机mysql的演变
1、单机Mysql(演变一)
1.1 用户访问流程
APP——>DAL——>Mysql

1.2 背景
一个基本的网站访问量一般不会太大,单个数据库完全足够。
2、缓存(演变二)
2.1 结构
Memcached(缓存) + MySQL + 垂直拆分
2.2 介绍
由于网站80%的情况都是在读,每次查询十分麻烦,所以为了减轻数据压力,可以使用缓存来保证效率。
2.3 发展过程
优化数据结构和索引——>文件缓存(IO)——>Memcached(当年最火)
2.4 功能
实现读写分离以及缓存
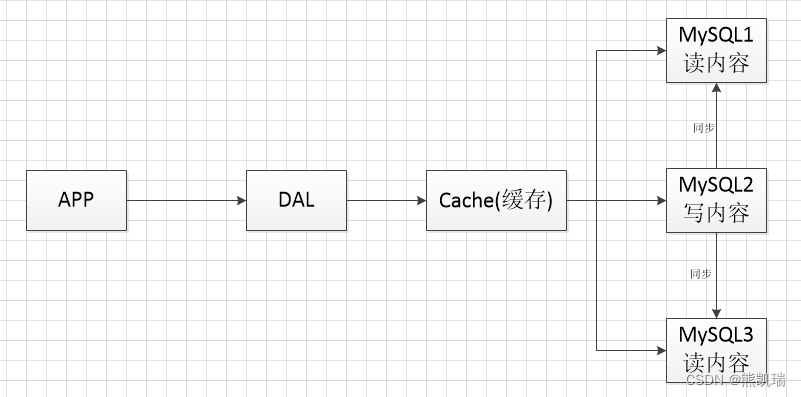
3、集群(演变三)
3.1 结构
分库分表 + 水平拆分 + MySQL集群 + 缓存
3.2 介绍
MyISAM:表锁,十分影响效率,高并发下会出现严重的锁问题。
Innodb:行锁
3.3 流程
使用分库分表来解决写的压力,同时MySQL也推出表分区的概念
3.4 功能
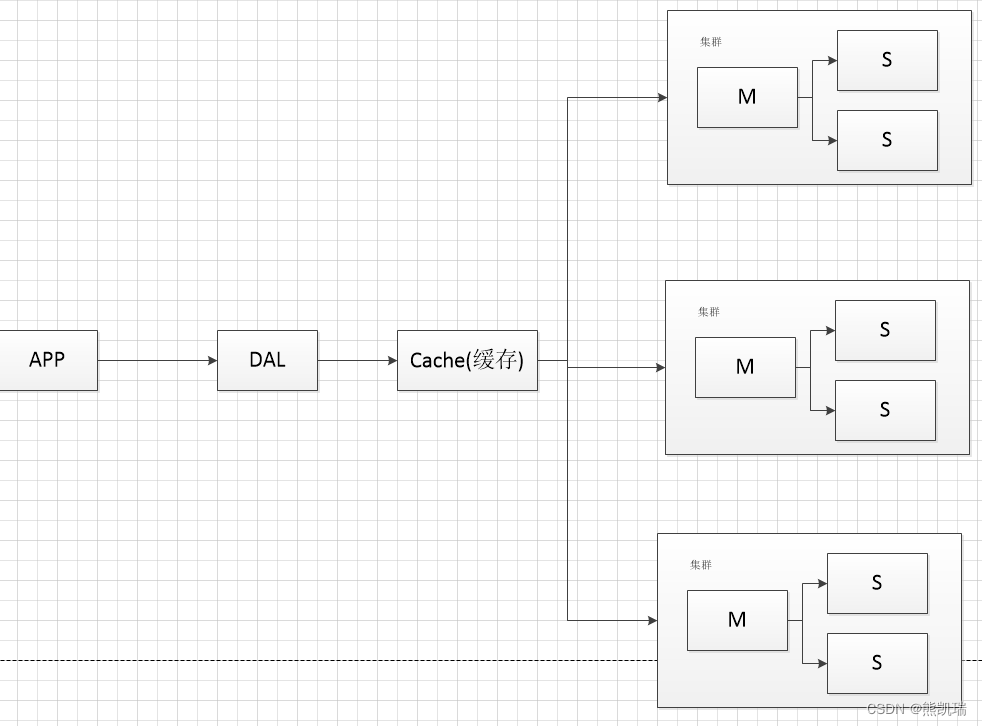
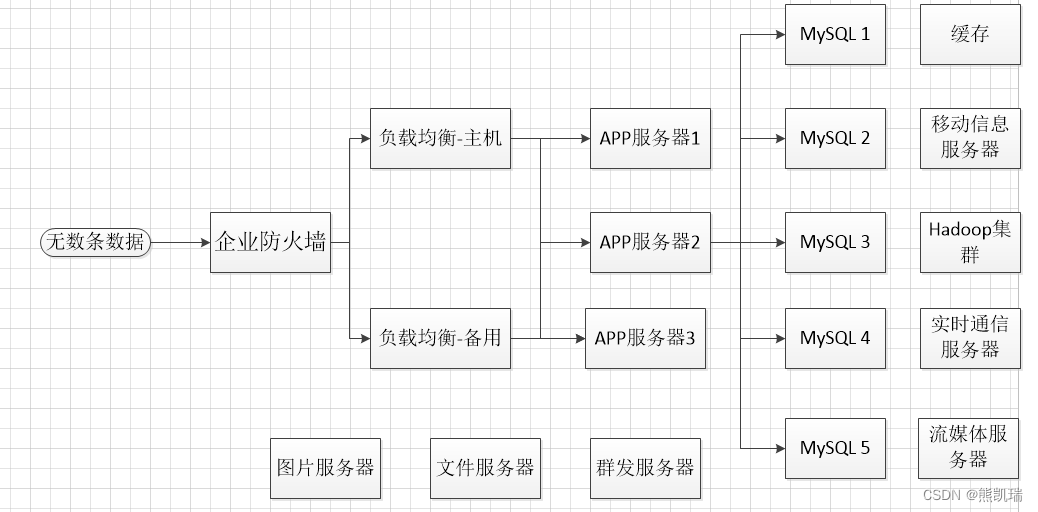
4、现在
4.1 结构
负载均衡 + 分库分表 + 水平拆分 + MySQL集群 + 缓存 + 各种服务器
4.2 背景
数据量很多,变化很快,MySQL等关系型数据库不够用。
4.3 功能
二、NoSQL概述
1、介绍
NoSQL泛指非关系型数据库,随着web2.0互联网的诞生,传统的关系型数据库很难处理超大规模的高并发的社区,于是NoSQL在当下大数据环境下发展十分迅速。(很多的数据类型用户的个人信息,社交网络,地理位置,这些数据类型的存储不需要一个固定的格式)
2、特点
(1) 方便扩展(数据之间没有关系,很好扩展)
(2)大数据量高性能(Redis一秒写8万次,读取11万,NoSQL的缓存记录级,是一种细粒度的缓存,性能会比较高)
(3)数据类型是多样型的(不需要事先设计数据库,随取随用)
3、RDBMS和NoSQL的区别
3.1 RDBMS(关系型数据库)
结构化组织、SQL、数据和关系都存在单独的表中、遵守ACID规则等
3.2 NoSQL(非关系型数据库)
存储不仅仅是数据、没有固定的查询语言、键值对存储、列存储、文档存储、图形数据库
最终一致性,CAP定理和BASE、高性能、高可用、高可扩。
三、3V + 3高
1、大数据时代的3V
(1)海量Volume
(2)多样Variety
(3)实时Velocity
2、大数据时代的3高
(1)高并发
(2)高可括
(3)高性能
四、技术总体概括
1、商品基本信息
1.1 场景
名称、价格、商家信息
1.2 技术
关系型数据库(MySQL/Oracle)
2、商品的描述、评论
2.1 场景
文字比较多
2.2 技术
文档型数据库(MongoDB)
3、图片
3.1 场景
存储图片图片
3.2 技术
分布式文件系统 FastDFS
淘宝文件系统 TFS
Google文件系统 GFS
Hadoop文件系统 HDFS
阿里云文件系统 OSS
4、商品的关键字
4.1 场景
搜索
4.2 技术
搜索引擎 solr、elasticsearch、ISerach
5、商品热门的波段信息
5.1 场景
商品的销售情况
5.2 技术
内存数据库 Redis、Tair、Memache…
6、商品的交易,外部的支付接口
三方应用
五、NoSQL的四大分类
1、KV键值对
1.1 举例
新浪:Redis
美团:Redis + Tair
阿里、百度:Redis + memecache
1.2 应用场景
内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。
1.3 数据模型
key指向Value的键值对,通常用hash table来实现。
1.4 优点
查找速度快
1.5 缺点
数据无结构化,通常只被当做字符串或者二进制数据
2、文档型数据库(bson格式 和 json一样)
1.1 MongoDB、CouchDB
MongoDB是一个基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档
MongoDB是一个介于关系型数据库和非关系型数据库中中间的产品,MongoDB是非关系型数据库中功能最丰富,最像关系型数据库的。
1.2 应用场景
Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容)
1.3 数据模型
Key-Value对应的键值对,Value为结构化数据。
1.4 优点
数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构。
1.5 缺点
查询性能不高,而且缺乏统一的查询语法。
3、列存储数据库
3.1 举例
HBase(大数据)
3.2 应用场景
分布式文件系统
3.3 数据模型
以列簇式存储,将同一列数据存在一起
3.4 优点
查找速度快,可扩展性强,更容易进行分布式扩展。
3.5 缺点
功能相对局限
4、图关系数据库
不是存储图片的数据库,而是存储的是关系
4.1 举例
Neo4J、InfoGrid、Infinite Graph
4.2 应用场景
社交网络,推荐系统等,专注于构建关系图谱
4.3 数据模型
图结构
4.4 优点
利用图结构相关算法,比如最短路径寻址,N度关系查找等。
4.5 缺点
很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式。