NoSQL之Redis配置
一.关系数据库与非关系型数据库
1.关系型数据库
1.实例–>数据库–>表(table)–>记录行(row)、数据字段(column)
2.关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。
3.SQL语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系库中数据的检索和操作。
4.简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
5.主流关系数据库:Oracle、MySQL、SQL Server、Microsoft Access、DB2 等。
(1).关系模型中常用的概念
| 解释 | 说明 |
|---|---|
| 关系 | 可以理解为一张二维表,每个关系都具有一个关系名,就是通常说的表名 |
| 元组 | 可以理解为二维表中的一行,在数据库中经常被称为记录 |
| 属性 | 可以理解为二维表中的一列,在数据库中经常被称为字段 |
| 域 | 属性的取值范围,也就是数据库中某一列的取值限制 |
| 关键字 | 一组可以唯一标识元组的属性,数据库中常称为主键,由一个或多个列组成 |
| 关系模式 | 指对关系的描述。其格式为:关系名(属性1,属性2, … … ,属性N),在数据库中成为表结构 |
(2).关系型数据库的优点
1.容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
2.使用方便:通用的SQL语言使得操作关系型数据库非常方便
3.易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
(3).关系型数据库瓶颈
-
1.高并发读写需求
网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈 -
2.海量数据的高效率读写
网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的 -
3.高扩展性和可用性
在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。
对网站来说,关系型数据库的很多特性不再需要了: -
4.事务一致性
关系型数据库在对事物一致性的维护中有很大的开销,而现在很多web2.0系统对事物的读写一致性都不高 -
5.读写实时性
对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比如发一条消息之后,过几秒乃至十几秒之后才看到这条动态是完全可以接受的 -
6.复杂SQL,特别是多表关联查询
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询,特别是SNS类型的网站,从需求以及产品阶级角度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能极大的弱化了
在关系型数据库中,导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,我们必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。每个元组字段的组成都是一样,即使不是每个元组都需要所有的字段,但数据库会为每个元组分配所有的字段,这样的结构可以便于标语表之间进行链接等操作,但从另一个角度来说它也是关系型数据库性能瓶颈的一个因素。
2.非关系型数据库
1.实例–>数据库–>集合(collection)–>键值对(key-value)
2.非关系型数据库不需要手动建数据库和集合(表)。
3.NoSQL(NoSQL = Not Only SQL),意思是“不仅仅是SQL”,是非关系型数据库的总称。
4.除了主流的关系型数据库外的数据库,都认为是非关系型。
5.主流的 NoSQL 数据库有 Redis、MongBD、Hbase、CouhDB 等。
(1)非关系型数据库产生背景
可用于应对 Web2.0 纯动态网站类型的三高问题。
(1)High performance——对数据库高并发读写需求
(2)Huge Storage——对海量数据高效存储与访问需求
(3)High Scalability && High Availability——对数据库高可扩展性与高可用性需求
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给Web2.0的数据库发展带来新的思路。让关系数据库关注在关系上,非关系型数据库关注在存储上。例如,在读写分离的MySQL数据库环境中,可以把经常访问的数据存储在非关系型数据库中,提升访问速度。
(2)NoSQL
- NoSQL一词首先是Carlo Strozzi在1998年提出来的,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。这个定义跟我们现在对NoSQL的定义有很大的区别,它确确实实字如其名,指的就是“没有SQL”的数据库。但是NoSQL的发展慢慢偏离了初衷,我们要的不是“no sql”,而是“no relational”,也就是我们现在常说的非关系型数据库了。
- 2009年初,Johan Oskarsson举办了一场关于开源分布式数据库的讨论,Eric Evans在这次讨论中再次提出了NoSQL一词,用于指代那些非关系型的,分布式的,且一般不保证遵循ACID原则的数据存储系统。Eric Evans使用NoSQL这个词,并不是因为字面上的“没有SQL”的意思,他只是觉得很多经典的关系型数据库名字都叫“**SQL”,所以为了表示跟这些关系型数据库在定位上的截然不同,就是用了“NoSQL“一词。
- 注:数据库事务必须具备ACID特性,ACID是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
- 非关系型数据库提出另一种理念,例如,以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。但非关系型数据库由于很少的约束,他也不能够提供像SQL所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数据库显的更为合适。
(3)非关系型数据库分类
- 由于非关系型数据库本身天然的多样性,以及出现的时间较短,因此,不想关系型数据库,有几种数据库能够一统江山,非关系型数据库非常多,并且大部分都是开源的。
- 这些数据库中,其实实现大部分都比较简单,除了一些共性外,很大一部分都是针对某些特定的应用需求出现的,因此,对于该类应用,具有极高的性能。依据结构化方法以及应用场合的不同,主要分为以下几类:
- 1.面向高性能并发读写的key-value数据库:
key-value数据库的主要特点即使具有极高的并发读写性能,Redis,Tokyo Cabinet,Flare就是这类的代表 - 2.面向海量数据访问的面向文档数据库:
这类数据库的特点是,可以在海量的数据中快速的查询数据,典型代表为MongoDB以及CouchDB - 3.面向可扩展性的分布式数据库:
这类数据库想解决的问题就是传统数据库存在可扩展性上的缺陷,这类数据库可以适应数据量的增加以及数据结构的变化
3.关系型数据库和非关系型数据库区别
1.数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据。
与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。
2.扩展方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。
要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多个表,这都需要通过提高计算机性能来客服。虽然SQL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限。
而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
3.对事务性的支持不同
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
二.Redis
概念:Redis 是一个开源的、使用 C 语言编写的 NoSQL 数据库。
Redis 基于内存运行并支持持久化,采用key-value(键值对)的存储形式,是目前分布式架构中不可或缺的一环。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。即:在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若 CPU 资源比较紧张,采用单进程即可。
1.Redis 与 Memcached 区别
- Memcached是多线程,而Redis使用单线程。(个人认为–Memcached在读写处理速度上由于Redis)
- Memcached使用预分配的内存池的方式,Redis使用现场申请内存的方式来存储数据,并且可以配置虚拟内存。
- Redis可以实现持久化(也就是说redis需要经常将内存中的数据同步到硬盘中来保证持久化),主从复制,实现故障恢复。
- Memcached只是简单的key与value,但是Redis支持数据类型比较多。包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
| / | Memcached | Redis |
|---|---|---|
| 类型 | Key-value数据库 | Key-value数据库 |
| 过期政策 | 支持 | 支持 |
| 数据类型 | 单一数据类型 | 五大数据类型 |
| 主从复制 | 不支持 | 支持 |
| 持久化支持 | 不支持 | 支持 |
| 虚拟内存 | 不支持 | 支持 |
| 存储value容量 | 最大1M | 最大512M |
| 内存分配 | 预分配内存池的方式管理内存,能够省去内存分配时间 | 临时申请空间,科能导致碎片 |
| 离可用支持 | 需要二次开发 | Redis天然支持集群功能,可以实现主动复制,读写分离。官方也提供了sentinel集群管理工具,能够实现主从服务监控,故障自动转移这一切,杜宇客户端都是透明的,无需程序改动,也无需人工介入 |
| 网络模型 | 非阻塞IO复用模型 | 非阻塞IO复用模型,提供一些非KV存储之外的排序,聚合功能,在执行这些功能时,复杂的CPU计算,会阻塞整个IO调度 |
| 水平扩展支持 | 暂无 | 暂无 |
| 多线程 | 支持多线程,CPU利用方面优于Redis | 支持单线程 |
| 支持的数据结构 | 纯Kev-value | 哈希、列表、集合、有序集合 |
2.Redis 的优点
- (1)具有极高的数据读写速度:数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
- (2)支持丰富的数据类型:支持 key-value、Strings、Lists、Hashes、Sets 及 Ordered Sets 等数据类型操作。
- (3)支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- (4)原子性:Redis 所有操作都是原子性的。
- (5)支持数据备份:即 master-salve 模式的数据备份。
- Redis作为基于内存运行的数据库,缓存是其最常应用的场景之一。除此之外,Redis常见应用场景还包括获取最新N个数据的操作、排行榜类应用、计数器应用、存储关系、实时分析系统、日志记录。
- (6)完全居于内存,数据实时的读写内存,定时闪回到文件中。采用单线程,避免了不必要的上下文切换和竞争条件
- (7)灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
-(8)虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘;
3.Redis支持两种持久化方式
-
(1)snapshotting(快照)也是默认方式.(把数据做一个备份,将数据存储到文件)
-
(2)Append-only file(缩写aof)的方式
-
快照是默认的持久化方式,这种方式是将内存中数据以快照的方式写到二进制文件中,默认的文件名称为dump.rdb.可以通过配置设置自动做快照持久化的方式。我们可以配置redis在n秒内如果超过m个key键修改就自动做快照.
-
aof方式:由于快照方式是在一定间隔时间做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。aof比快照方式有更好的持久化性,是由于在使用aof时,redis会将每一个收到的写命令都通过write函数追加到文件中,当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。
4.redis的架构
| 架构 | 解释 |
|---|---|
| File Event | 处理文件事件,接受它们发来的命令请求(读事件),并将命令的执行结果返回给客户端(写事件) |
| Time Event | 时间事件(更新统计信息,清理过期数据,附属节点同步,定期持久化等) |
| AOF | 命令日志的数据持久化 |
| RDB | 实际的数据持久化 |
| Lua Environment | Lua 脚本的运行环境. 为了让 Lua 环境符合 Redis 脚本功能的需求,Redis 对 Lua 环境进行了一系列的修改, 包括添加函数库、更换随机函数、保护全局变量, 等等 |
| Command table(命令表) | 在执行命令时,根据字符来查找相应命令的实现函数 |
| Share Objects | 两种分类,一类是LSO——Local Share Object(本地共享对象)其实类似于cookie,而另一种RSO——Remote Share Object(远程共享对象) 比较类似于JSP中的Application对象 |
三.Redis安装部署
systemctl stop firewalld
setenforce 0
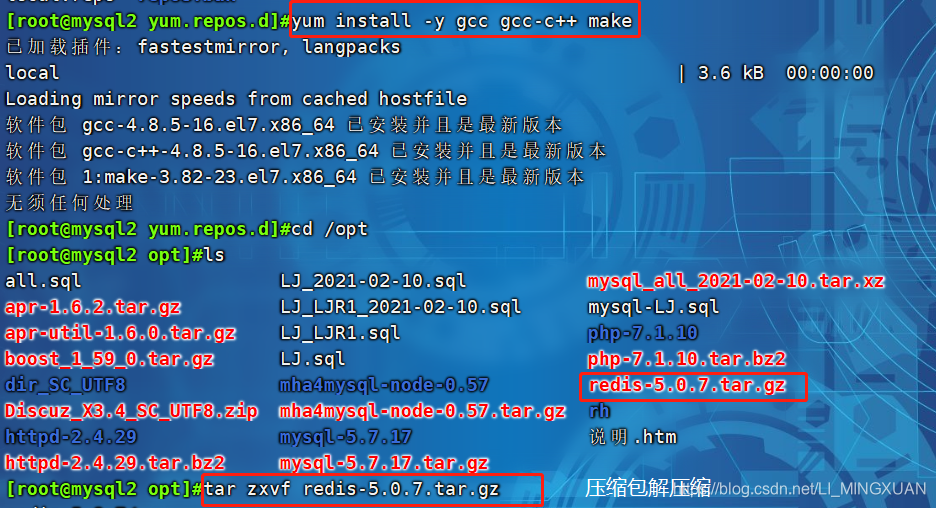
yum install -y gcc gcc-c++ make
tar zxvf redis-5.0.7.tar.gz -C /opt/
cd /opt/redis-5.0.7/
make
make PREFIX=/usr/local/redis install
#由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。
#执行软件包提供的 install_server.sh 脚本文件设置 Redis 服务所需要的相关配置文件
cd /opt/redis-5.0.7/utils
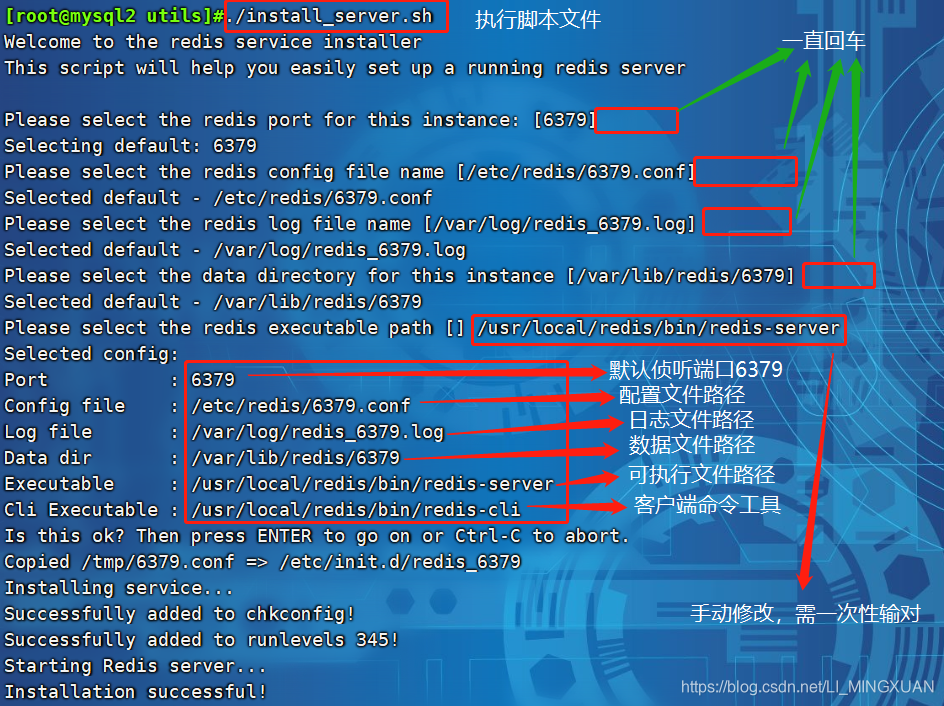
./install_server.sh
...... #一直回车
Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server #需要手动修改为 /usr/local/redis/bin/redis-server ,注意要一次性正确输入
----------------------------------------------------------------------------------------------------------
Selected config:
Port : 6379 #默认侦听端口为6379
Config file : /etc/redis/6379.conf #配置文件路径
Log file : /var/log/redis_6379.log #日志文件路径
Data dir : /var/lib/redis/6379 #数据文件路径
Executable : /usr/local/redis/bin/redis-server #可执行文件路径
Cli Executable : /usr/local/bin/redis-cli #客户端命令工具
----------------------------------------------------------------------------------------------------------
#把redis的可执行程序文件放入路径环境变量的目录中便于系统识别
ln -s /usr/local/redis/bin/* /usr/local/bin/
#当 install_server.sh 脚本运行完毕,Redis 服务就已经启动,默认侦听端口为 6379
netstat -natp | grep redis
#Redis 服务控制
/etc/init.d/redis_6379 stop #停止
/etc/init.d/redis_6379 start #启动
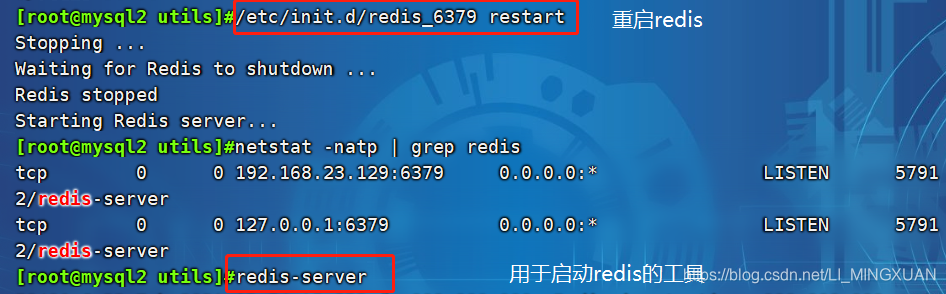
/etc/init.d/redis_6379 restart #重启
/etc/init.d/redis_6379 status #状态
#修改配置 /etc/redis/6379.conf 参数
vim /etc/redis/6379.conf
bind 127.0.0.1 192.168.80.10 #70行,添加 监听的主机地址
port 6379 #93行,Redis默认的监听端口
daemonize yes #137行,启用守护进程
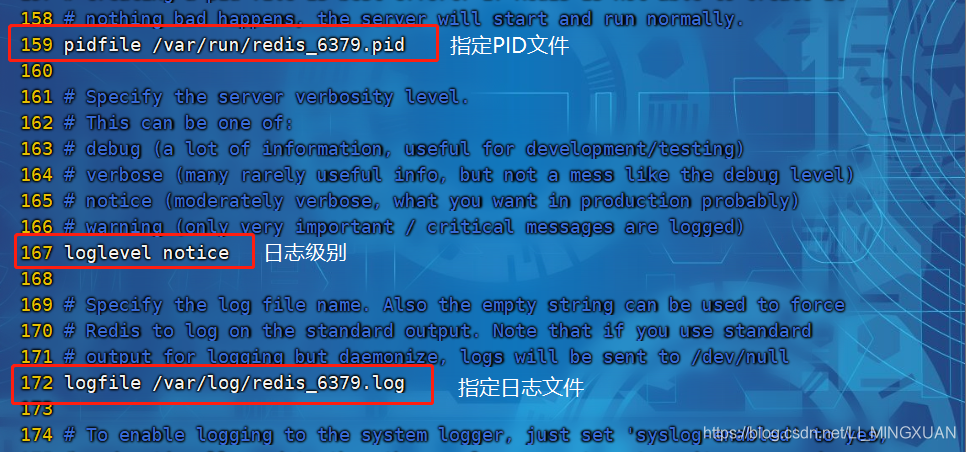
pidfile /var/run/redis_6379.pid #159行,指定 PID 文件
loglevel notice #167行,日志级别
logfile /var/log/redis_6379.log #172行,指定日志文件
/etc/init.d/redis_6379 restart