Visual Blocks for ML是一个由Google开发的开源可视化编程框架。它使你能够在易于使用的无代码图形编辑器中创建ML管道。
为了运行Visual Blocks for ML。需要确保你的GPU是可以工作的。剩下的就是clone代码,然后运行,下面我们做一个简单的介绍:
Visual Blocks for ML是运行在支持javascript的web浏览器上,他主要使用TensorFlow.js,也就是说并不是服务器的GPU资源而是本地的GPU,所以数据不会上传,数据隐私是被保护的,但是对于其他框架可能就不支持了。
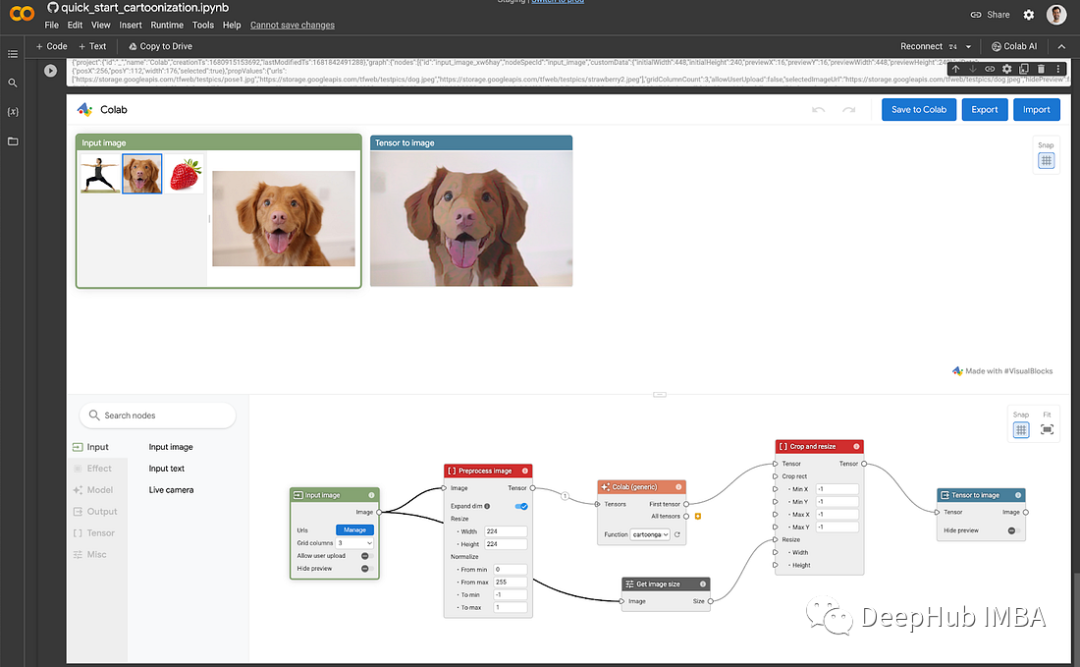
但是Visual Blocks for ML的最大特点是以可视化的方式一步一步地解释所发生的事情,并且能够帮助你更快地迭代并最终更快地发布成果,加速设计过程!
在本文中,我使用ML分割模型为现有照片,添加贴纸和虚拟背景,为例做个简单的介绍。
官方DEMO
1、图像分割
官方的DEMO是这里:https://visualblocks.withgoogle.com/#/demo,点击“Demo: Create Your Own”选项卡。
访问这个页面时可能需要开启摄像头权限。
从左侧的组件库中加载图像,单击Input并将其拖拽到项目的底部面板中。
你可以选择一个预加载的库存图片,上传你自己的照片
应用Body segmentation model—不需要从组件库中拖动节点,只需单击并拖动表示输入图像节点输出的小圆圈,然后从可用候选节点列表中进行选择或搜索。
添Mask visualizer ——为了显示分割模型的输出,需要在工作流中添加一个Mask可视化器节点。从上面的Body segmentation model的输出拖动,并选择推荐的节点:Mask visualizer。
如果到目前为止按照正确的步骤操作,应该会看到类似下面的截图:

应用Face landmark model,我们的目标是在头上添加一个贴纸,所以我们需要创建一个模型来定位面部区域。Face landmark model可以定义锚点,例如“face top”,这样我们的贴纸就能放置在正确的位置。
最后就是添加虚拟贴纸:首先需要从左侧组件库中拖动一个新的输入图像节点,这里我使用了一个灯泡的图像。你可以用任何你想要的图片作为贴纸;只要确保它有一个透明的背景。
然后需要从Face landmark 输出中拖动并选择Virtual sticker。它需要两个更多的输入才能工作,贴纸图像和Mask vizualiser。
最后就是调整“Scale”和“OffsetX/Y”参数来调整位置,结果如下图所示

在上图中,还使用Landmark visualizer进行了可视化,它可以将人脸的映射结果作为图片显示。
有了前景,我们还可以使用Image Mixer添加背景图像:
从左侧的组件库中选取一个新的输入图像节点,也就是预加载的背景。
然后在左侧的组件库的Effect选项卡中拖动Virtual sticker节点,将上面我们配置的最后节点输出新Virtual sticker节点的输入Image1中,然后将背景图像中连接到输入Image2中。将下拉模式更改为“destination-over”。最后的结果如下:

这个工具还提供了导出或共享,可以将管道转换为.js代码,以便其他人可以导入并重新创建工作流!
上面我们使用的是官网的DEMO,下面看看如何使用Jupyter Notebook本地运行。
Jupyter Notebook
我们还可以在自己的环境中运行Visual Blocks,这里使用Colab,作为演示。
为Visual block安装必要的Python库:
!pip install visualblocks
启动Visual Blocks服务器:
import visualblocks
server = visualblocks.Server()
然后就是开启Visual Blocks UI:
server.display()
现在就可以在本地创建工作流了,创建完成后可以点击“Save to Colab”,这样工作流的.js将会保存在Jupyter Notebook,以供将来运行:
如果你想自己尝试,可以使用下面这个文件。
https://avoid.overfit.cn/post/ed762d829e1d40d4968a1c4f24018663
总结
谷歌刚开源的这个Visual Blocks for ML我个人感觉对于实际应用没有什么意义,可能只是一个TensorFlow.js的技术展示,但是它研究的方向应该是非常好的,比如对于摄像头来说,通过浏览器本地进行特征提取,而不需要再进行网络传说,从而节省了带宽和服务器资源,并且用户的隐私也得到了保证。这不就是联邦学习的一个方向么?有兴趣的可以看看,还是挺好玩的。