一、实例背景
假设根据【推荐分值】来对推荐者类型进行分类:高推荐、中推荐、低推荐

二、任务目标
训练出一个模型,来实现根据【推荐分值】,来预测【推荐类型】的分类
三、机器学习实现
1. 核心步骤
实现全流程:

1. 1 建立模型
任务目标是实现分类,且从原数据可看出,分类标签为高、中、低三种类别:因此应建立“多分类-逻辑回归模型”
在sklearn中,无论是二分类还是多分类逻辑回归,实际都是建立在线性回归方程上的逻辑回归,因此建立模型核心代码为
# 1. 建立模型:逻辑回归模型
classifier = linear_model.LogisticRegression()
1.2 学习模型
1)确定损失函数:极大似然估计法
2)求解计算指标最优的方式:sklearn默认为迭代-求近似解的方式
并且classifier = linear_model.LogisticRegression()如果没有特别说明,则默认为拟牛顿法(默认solver=“lbfgs”)
如果要更改指标最优的迭代求解方式,可增加参数设置:solver

# 1. 建立模型:逻辑回归模型+选择损失函数的优化方法
classifier = linear_model.LogisticRegression(solver="sag") # 随机梯度下降法
# 2. 学习模型
classifier.fit(X,Y)
1.3 衡量模型
分类-逻辑回归模型的衡量指标分别为:准确率、精确率、召回率、F1分数
核心代码如下:
# 3. 衡量模型
accurency = classifier.score(X,Y)
PRF = classification_report(Y,Y_predict)
2. 代码
from sklearn import linear_model
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
# 获取所需数据:'推荐分值', '推荐类型'
datas = pd.read_excel('./datas2.xlsx')
important_features = ['推荐分值', '推荐类型']
datas_1 = datas[important_features]
# 明确实际类别Y为'推荐类型',X为'推荐分值'
Y = datas_1['推荐类型']
X = datas_1.drop('推荐类型',axis=1)
# 1. 建立模型:逻辑回归模型
classifier = linear_model.LogisticRegression()
# 2. 学习模型
classifier.fit(X,Y)
Y_predict = classifier.predict(X) # 模型分类
labels = classifier.classes_ # 获取分类标签
w = classifier.coef_ # 获取参数 W
b = classifier.intercept_ # 获取偏差b,或称W0
# 3. 衡量模型
accurency = classifier.score(X,Y)
PRF = classification_report(Y,Y_predict)
# 输出模型最优状态下的参数W和b,R²分数
for index,value in enumerate(zip(labels,w)):
print(f"【{
value[0]}】类别的参数W{
index+1}:",value[1])
print("偏差b,或参数W0:",list(zip(labels,b)))
print("逻辑回归模型的分类【准备率】为:",accurency)
print("逻辑回归模型的精确率、召回率、F1分数为:")
print(PRF)
3. 输出
从下图输出结果可以看出,模型分类准确率、精确率、召回率、F1分数,都是满分!!!
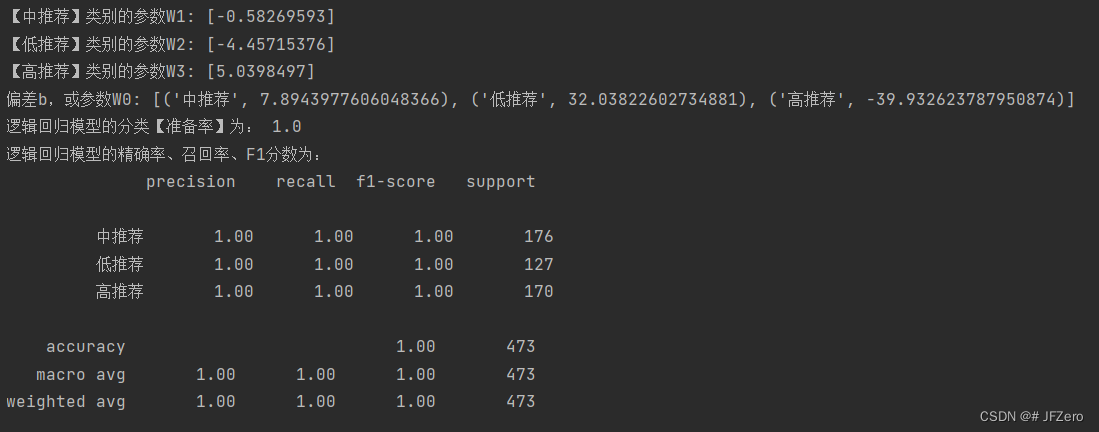
模型的分类结果和实际分类对比也可以看出,模型分类和实际分类是一样的!
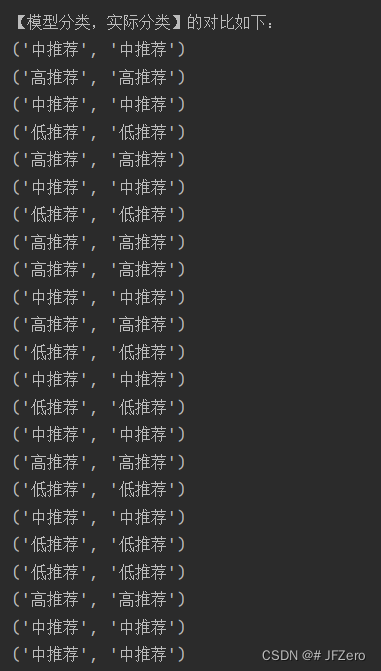
为什么会这么准确呢?
这是因为,原始数据的【推荐类型】是严格根据【推荐分值】进行分类的,原始数据的分类规则如下:

可见,在严格的线性分类规则下,逻辑回归是可以准确实现分类的。