这篇文章主要介绍了python做大数据需要学哪方面?,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。

前言
本文的主要技术是采用Python的Scrapy框架爬取网站的待租房数据,然后使用Mysq的对数据继续简单处理然后存储,再Flask和Highcharts对数据进行可视化展示,逻辑很简单,只能算是对这几天的学习做一个简单的总结和实战练习,
注:本次采集已适当控制采集频率,并且采集的数据仅用于学习使用
一、数据采集
1.1目标网站选取
先选择目标网站,这次我采集的是链家网的数据,特别提醒:在使用scrapy爬取数据时,一定要注意爬取频率,以免影响网站的正常用户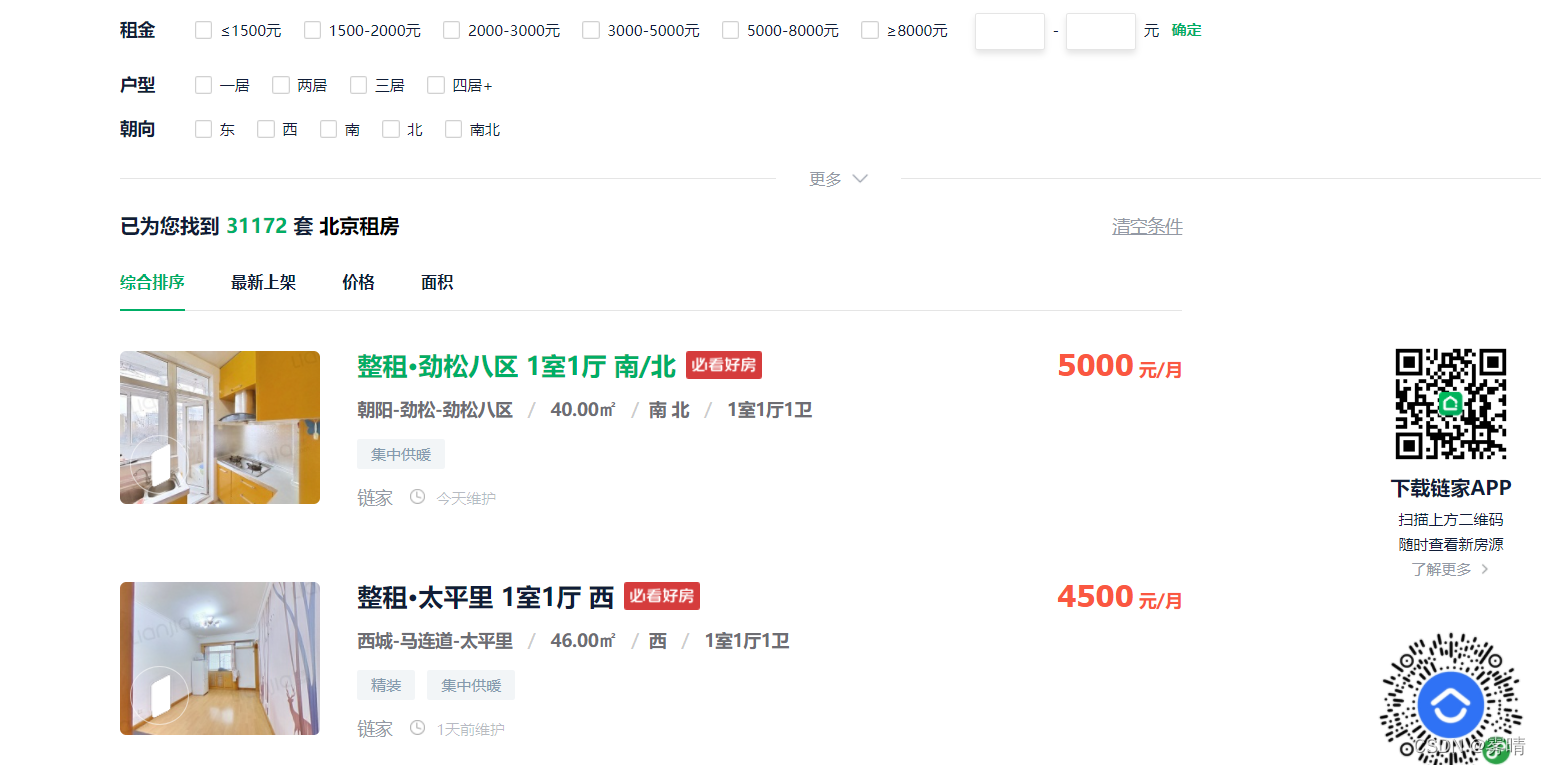
1.2 创建爬虫项目
目标网站选取好了之后,我们创建一个爬虫项目,首先需要安装scrapy的库,安装教程;
Scrapy爬虫的安装教程
使用命令scrapy startproject myfrist(your_project_name创建项目
创建完了之后大概是这样子的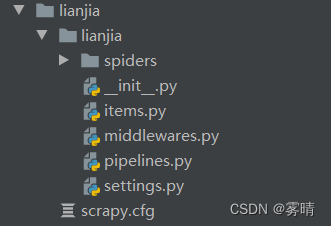
解释一下,后面我会专门出一个scrapy的简单笔记,是笔记哈
| 名称 | 作用 |
|---|---|
| scrapy.cfg | 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中) |
| items.py | 设置数据存储模板,用于结构化数据,如:Django的Model |
| pipelines | 数据处理行为,如:一般结构化的数据持久化 |
| settings.py | 配置文件,如:递归的层数、并发数,延迟下载等 |
| spiders | 爬虫目录,如:创建文件,编写爬虫规则 |
| 下一步创建爬虫 ,使用命令:scrapy genspider 爬虫名 爬虫的地址 | |
| 使用这个命令之后,spiders目录下就会出现一个爬虫文件 | |
 |
|
| 到这里我们的项目就创建完了,下一步就编写数据持久化模型, |
1.3 数据持久化模型
就是items.py文件
class LianjiaItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
url = scrapy.Field()
addres1 = scrapy.Field()
addres2 = scrapy.Field()
area = scrapy.Field()
cx = scrapy.Field()
rz = scrapy.Field()
zq = scrapy.Field()
kf = scrapy.Field()
zj=scrapy.Field()
模型编写完成之后,下面就是创建爬虫了
1.3 编写爬虫
需要注意:下面的代码,由于一些原因,我修改了一些xpath语句,所以直接复制使用是无法运行的,但是逻辑是绝对正确,不影响学习,如果各位看官确实需要能直接运行的代码,可私信我
class ZfSpider(scrapy.Spider):
name = 'zf'
allowed_domains = ['bj.lianjia.com']
start_urls = ['https://bj.lianjia.com/zufang/']
def parse(self, response):
#构造分页Url
url1='https://bj.lianjia.com/zufang/pg'
url2='/#contentList'
for i in range(1,100):
url=url1+str(i)+url2
#丢到下一层去
yield scrapy.Request(url=url,callback=self.one_data_list,meta={})
def one_data_list(self,response):
data_list = response.xpath('//*[@id="content"]/div[1]/div[1]/div')
for i in data_list:
url='https://bj.lianjia.com'+i.xpath('./div/p[1]/a/@href').get()
name=i.xpath('./div/p[1]/a/text()').get()
addres1=i.xpath('./div/p[1]/a/text()').get()
addres2=i.xpath('./div/p[1]/a[3]/text()').get()
meta={
'url':url,
'name':name,
'addres1':addres1,
'addres2':addres2
}
yield scrapy.Request(url=url,callback=self.data_donw,meta=meta)
def data_donw(self,response):
lianjIetm=LianjiaItem()
lianjIetm['url']=response.meta['url']
lianjIetm['name']=response.meta['name']
lianjIetm['addres1']=response.meta['addres1']
lianjIetm['addres2'] = response.meta['addres2']
#取出数据
lianjIetm['area']=response.xpath('//*[@id="info"]/ul[1]/li[1]/text()').get()
lianjIetm['cx']=response.xpath('//*[@id="info"]/ul[1]/li[3]/text()').get()
lianjIetm['rz']=response.xpath('//*[@id="info"]/ul[1]/li[4]/text()').get()
lianjIetm['zq']=response.xpath('//*[@id="info"]/ul[2]/li[2]/text()').get()
lianjIetm['kf']=response.xpath('//*[@id="info"]/ul[2]/li[5]/text()').get()
lianjIetm['zj'] = response.xpath('//*[@id="aside"]/div[0]/span/text()').get()
#推到下载器去
yield lianjIetm
到这里我们爬虫就编写完了来试试效果
启动爬虫命令: scrapy crawl 爬虫名
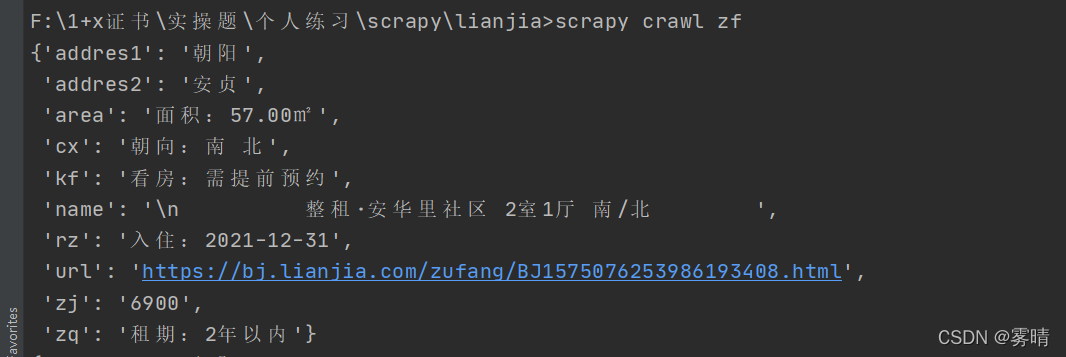
没有问题,下面编写管道,项目管道用人话解释 就是用于将数据持久化存储的,我们要将数据存储到mysql数据库中去,当然在这之前,需要先去mysql里面创建好数据库和表结构,就跟我们的模型类一致火车采集器伪原创。
1.4编写项目管道
也就是pipelines.py文件。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
from itemadapter import ItemAdapter
class LianjiaPipeline:
'''保存数据'''
def open_spider(self, spider):
self.db = pymysql.connect(host='192.168.172.131', port=3306, user='root', password='12346', charset='utf8',
database='lj')
self.cur = self.db.cursor()
def process_item(self, item, spider):
print(item)
sql="insert into data values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cur.execute(sql,[item['name'],item['url'],item['addres1'],item['addres2'],item['area'],item['cx'],item['rz'],item['zq'],item['kf'],item['zj']])
self.db.commit()
return item
def close_spider(self,spider):
self.db.close()
这里编写完了之后,直接启动会发现数据库中没有数据,是因为还没有启用,需要去settings.py里面去配置一下,

下面启动爬虫 
可以看到已经有数据了,到此数据采集就完成了,下面是数据清洗
数据清洗
我并不是一个专业学习大数据放心,只能说是混在大数据班混了一个大数据的二流竞赛,对于数据清洗呢,这里只是我自己的理解,如有错误,敬请指正。
先说说问题。
1、地址没有合并
2、面积使用数字方便排序
3、租期里面有一些缺失数据
解决方法
1、合并地址
2、处理面积数据
3、干掉缺少数据
# 合并地址
UPDATE `lj`.`data` SET `addres2` = CONCAT(`addres1`,`addres2`)
# 面积处理
UPDATE `lj`.`data` set `area`=substring(`area`,4)
UPDATE `lj`.`data` set `area`=REPLACE(`area`,'㎡','');
# 处理缺失值
DELETE FROM `lj`.`data` where rz='入住:暂无数据'
最终效果
最后就是数据可视化了,空了再完善,最近有点忙,顺便还在考虑是用falsk还是django