人脸识别的第一步,就是要找到一个模型可以用简洁又具有差异性的方式准确反映出每个人脸的特征。识别人脸时,先将当前人脸采用与前述同样的方式提取特征,再从已有特征集中找出当前特征的最邻近样本,从而得到当前人脸的标签。
OpenCV 提供了三种人脸识别方法,分别是 LBPH 方法、EigenFishfaces 方法、Fisherfaces方法。本节主要对 LBPH 方法进行简单介绍。
LBPH(Local Binary Patterns Histogram,局部二值模式直方图)所使用的模型基于 LBP(Local
Binary Pattern,局部二值模式)算法。LBP
最早是被作为一种有效的纹理描述算子提出的,由于在表述图像局部纹理特征上效果出众而得到广泛应用。
基本原理
LBP 算法的基本原理是,将像素点 A 的值与其最邻近的 8 个像素点的值逐一比较:
- 如果 A 的像素值大于其临近点的像素值,则得到 0。
- 如果 A 的像素值小于其临近点的像素值,则得到 1。
最后,将像素点 A 与其周围 8 个像素点比较所得到的 0、1 值连起来,得到一个 8 位的二进制序列,将该二进制序列转换为十进制数作为点 A 的 LBP 值。
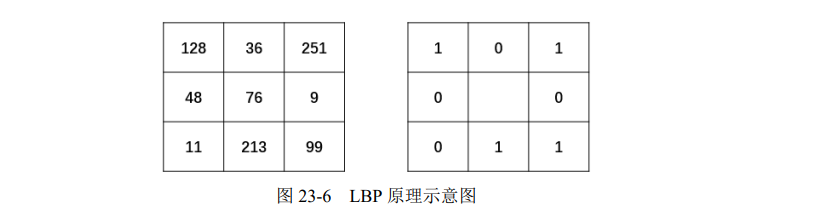
下面以图 23-6 中左侧 3×3 区域的中心点(像素值为 76 的点)为例,说明如何计算该点的LBP 值。计算时,以其像素值 76 作为阈值,对其 8 邻域像素进行二值化处理,
- 将像素值大于 76 的像素点处理为 1。例如,其邻域中像素值为 128、251、99、213 的点,都被处理为 1,填入对应的像素点位置上。
- 将像素值小于 76 的像素点处理为 0。例如,其邻域中像素值为 36、9、11、48 的点,都被处理为 0,填入对应的像素点位置上。
根据上述计算,可以得到图 23-6 中右图所示的二值结果。
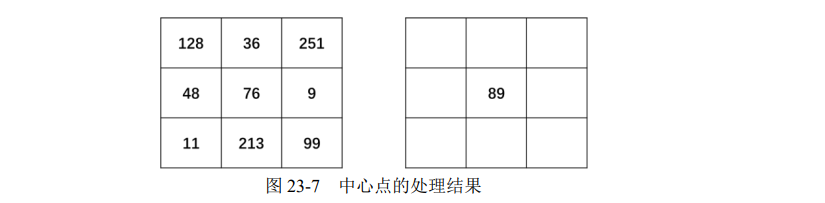
完成二值化以后,任意指定一个开始位置,将得到的二值结果进行序列化,组成一个 8 位的二进制数。
例如,从当前像素点的正上方开始,以顺时针为序得到二进制序列“01011001”。最后,将二进制序列“01011001”转换为所对应的十进制数“89”,作为当前中心点的像素值,如图 23-7 所示。
对图像逐像素用以上方式进行处理,就得到 LBP 特征图像,这个特征图像的直方图被称为 LBPH,或称为 LBP 直方图。
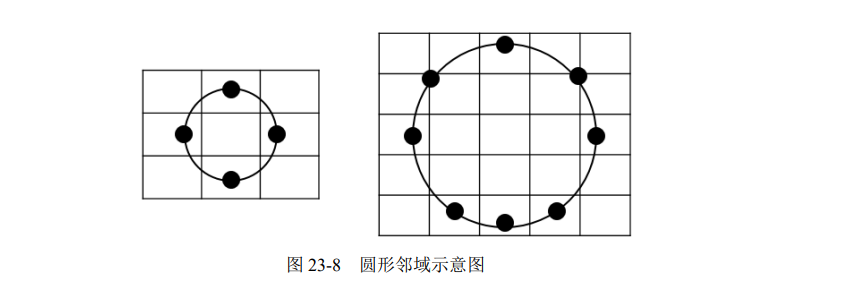
为了得到不同尺度下的纹理结构,还可以使用圆形邻域,将计算扩大到任意大小的邻域内。圆形邻域可以用(P, R)表示,其中 P 表示圆形邻域内参与运算的像素点个数,R 表示邻域的半径。
例如,在图 23-8 中就分别采用了不同的圆形邻域。
-
左侧使用的是(4, 1)邻域,比较当前像素与邻域内 4 个像素点的像素值大小,使用的半径是 1。
-
右侧使用的是(8, 2)邻域,比较当前像素与邻域内 8 个像素点的像素值大小,使用的半径是 2。在参与比较的 8 个邻域像素点中,部分邻域可能不会直接取实际存在的某个位置上的像素点,而是通过计算构造一个“虚拟”像素值来与当前像素点进行比较。
人脸的整体灰度由于受到光线的影响,经常会发生变化,但是人脸各部分之间的相对灰度会基本保持一致。LBP 的主要思想是以当前点与其邻域像素的相对关系作为处理结果,正是因为这一点,在图像灰度整体发生变化(单调变化)时,从 LBP 算法中提取的特征能保持不变。
因此,LBP 在人脸识别中得到了广泛的应用。
从上面的介绍可以看到,LBP 特征与 Haar 特征很相似,都是图像的灰度变化特征。
函数介绍
在 OpenCV 中,可以用函数 cv2.face.LBPHFaceRecognizer_create()生成 LBPH 识别器实例模型,然后应用 cv2.face_FaceRecognizer.train() 函数完成训练,最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
下面分别介绍上述三个函数。
- 函数cv2.face.LBPHFaceRecognizer_create()
函数 cv2.face.LBPHFaceRecognizer_create()的语法格式为:
retval = cv2.face.LBPHFaceRecognizer_create( [, radius[, neighbors[,
grid_x[, grid_y[, threshold]]]]])
其中全部的参数都是可选的,含义如下:
- radius:半径值,默认值为 1。
- neighbors:邻域点的个数,默认采用 8 邻域,根据需要可以计算更多的邻域点。
- grid_x:将 LBP 特征图像划分为一个个单元格时,每个单元格在水平方向上的像素个数。
该参数值默认为 8,即将 LBP 特征图像在行方向上以 8 个像素为单位分组。 - grid_y:将 LBP 特征图像划分为一个个单元格时,每个单元格在垂直方向上的像素个数。
该参数值默认为 8,即将 LBP 特征图像在列方向上以 8 个像素为单位分组。 - threshold:在预测时所使用的阈值。如果大于该阈值,就认为没有识别到任何目标对象。
- 函数cv2.face_FaceRecognizer.train()
函数 cv2.face_FaceRecognizer.train()对每个参考图像计算 LBPH,得到一个向量。每个人脸
都是整个向量集中的一个点。该函数的语法格式为:
None = cv2.face_FaceRecognizer.train( src, labels )
式中各个参数的含义为:
- src:训练图像,用来学习的人脸图像。
- labels:标签,人脸图像所对应的标签。
该函数没有返回值。
- 函数cv2.face_FaceRecognizer.predict()
函数 cv2.face_FaceRecognizer.predict()对一个待测人脸图像进行判断,寻找与当前图像距离最近的人脸图像。与哪个人脸图像最近,就将当前待测图像标注为其对应的标签。当然,如果待测图像与所有人脸图像的距离都大于函数 cv2.face.LBPHFaceRecognizer_create()中参数
threshold 所指定的距离值,则认为没有找到对应的结果,即无法识别当前人脸。
函数 cv2.face_FaceRecognizer.predict()的语法格式为:
label, confidence = cv2.face_FaceRecognizer.predict( src )
式中参数与返回值的含义为:
- src:需要识别的人脸图像。
- label:返回的识别结果标签。
- confidence:返回的置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。
0 表示完全匹配。通常情况下,认为小于 50 的值是可以接受的,如果该值大于 80 则认为差别较大。
示例:完成一个简单的人脸识别程序
import cv2
import numpy as np
images=[]
images.append(cv2.imread("face\\face2.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face3.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face4.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face5.png",cv2.IMREAD_GRAYSCALE))
labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.LBPHFaceRecognizer.create()
recognizer.train(images, np.array(labels))
predict_image=cv2.imread("face\\face4.png",cv2.IMREAD_GRAYSCALE)
label,confidence= recognizer.predict(predict_image)
print("label=",label)
print("confidence=",confidence)
其中的图片是我随便到网上下载的明星的图片。总体识别度不高,而且如果识别不到会直接返回0.这个在深度的时候也会有这个问题。需要调整判断逻辑。
返回结果:
label= 1
confidence= 0.0
先熟悉了解下,后续在集中对比下几个人脸识别的算法的区别及更合适的应用场景。