在因子投研和生产过程中,往往需要基于大量因子进一步加工有状态的复杂指标,比如计算实时 K 线和 MACD、RSI 等。
假设要计算1000个因子,每个因子实现逻辑各不相同,并有特定的如窗口关闭信号、计算窗口边界等配置,重复搭建流处理框架、多次计算同一中间变量,必然是非常低效的。有没有什么方法可以对大量因子的流式计算规范化、格式化,实现工程化管理呢?
——DolphinDB 推出了一个方便、快捷、扩展性好和兼容性强的流批一体因子计算平台原型,提供基于快照数据计算分钟因子和进一步加工分钟因子为复杂因子的功能,用户可以根据我们给出的脚本和部署教程,快速搭建和调试。
有了这一套流批一体因子计算平台,业务人员无需理解 DolphinDB 流计算框架的底层架构,仅需根据业务因子计算逻辑编写函数表达式,然后调度因子计算平台的计算接口,便可完成因子计算。
同时,开发人员也无需再转写代码,因子投研和生产只需一套系统、一种脚本即可无缝切换,极大降低了开发运维成本,提高了因子投产的全流程效率。
因子计算平台的架构和功能
Level 2 快照数据流批一体因子计算平台的架构如下图所示:
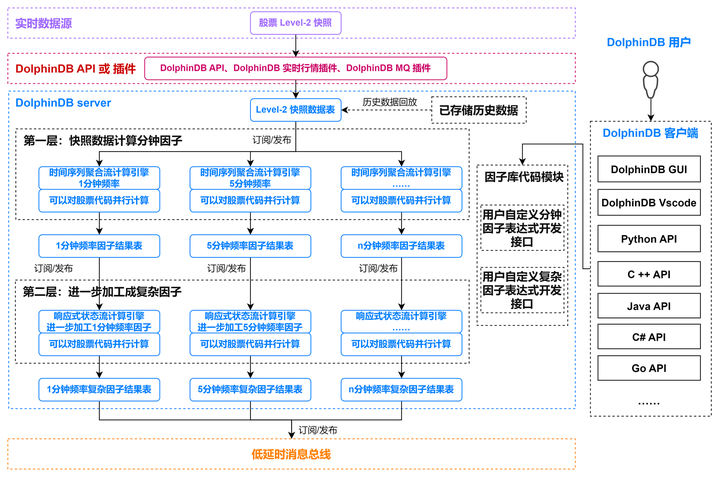
主要包含以下几个功能模块:
-
实时数据低延时接入:API 实时数据写入接口、实时行情接入插件、消息中间件订阅插件;
-
历史数据回放:单表和多表严格按照时间顺序控速回放,将存储在 DolphinDB 数据库中的历史数据回放成流;
-
流计算引擎:对快照数据做滚动窗口的聚合计算使用了时间序列聚合引擎,进一步加工成复杂因子依赖响应式状态引擎;
-
集成开发环境:DolphinDB GUI 和 DolphinDB Vscode 用于因子表达式代码的开发和调试,通过 API 交互进行任务调度和作业执行;
-
低延时消息总线发布:对接各种消息队列中间件,把实时计算结果推送到 Kafka, zmq, RabbitMQ, MQTT 等。
因子计算平台怎么使用?
按照本教程部署完基于 DolphinDB 搭建的因子计算平台后,基于历史数据的因子开发阶段的调试流程如下:
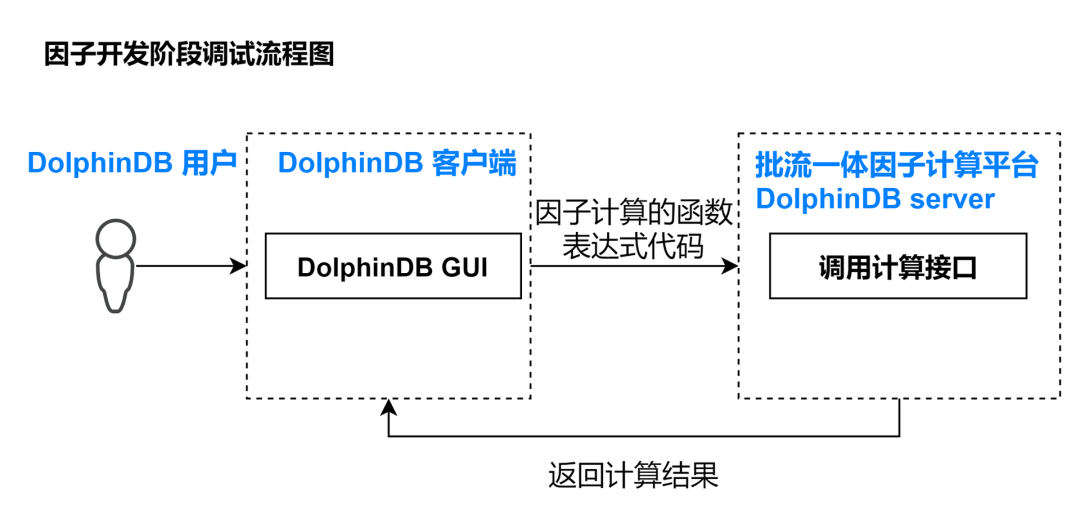
基于历史数据的因子开发
因子业务开发人员只需要在 DolphinDB 提供的集成开发环境中编写因子计算的函数表达式,然后调用因子计算平台的计算接口就可以完成调试。如果编写因子符合 DolphinDB 的语法,就可以成功执行并返回计算结果。如果编写因子不符合 DolphinDB 的语法,就会报错中断。
在已经开发了一定数量的因子后,需要在生产环境部署实时计算业务,部署流程如下:
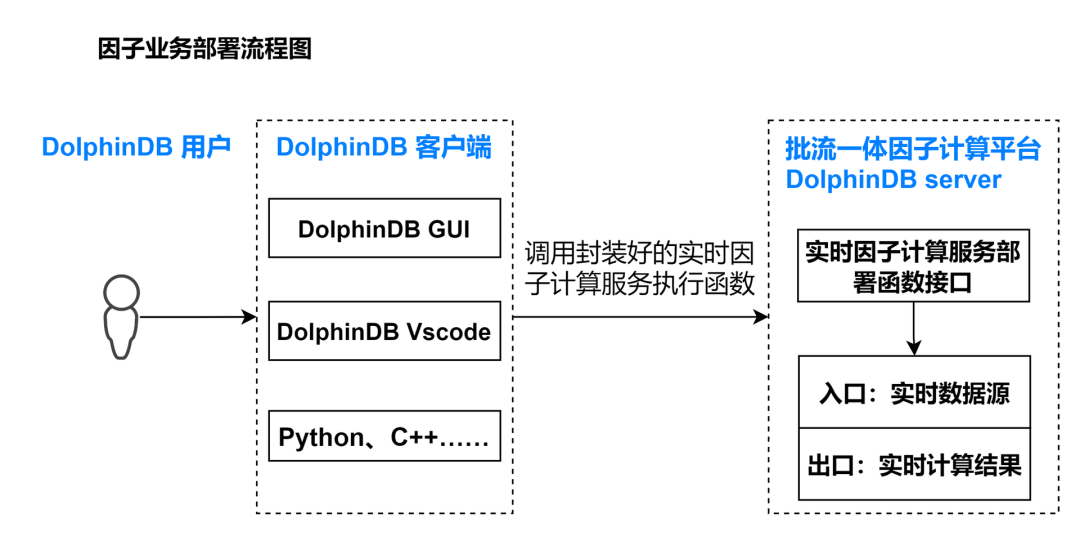
基于实时数据的生产环境部署
因子业务开发人员只需通过客户端调用封装好的实时因子计算服务执行函数,便可以完成部署。执行完以后,DolphinDB server 会出现该流计算服务的入口,是一个表对象,可以通过 DolphinDB 提供的实时数据接入工具来接入数据。同时也会自动创建流计算服务的出口,也是一个表对象,存储计算结果。
总的来说——
写个对应的因子函数,
生成 Json 配置文件,
调度新的 Json 文件,
大功告成!
值得一提的是,本次 DolphinDB 推出的因子计算平台只涉及分钟频的因子计算,但是 DolphinDB 的计算能力不局限于此,接下来还会陆续发布快照频率、1s 频率甚至更高频率的因子计算平台构建最佳实践教程,敬请期待!