目录
一、前言
在项目开发过程中,经常会遇到各种意向不到的业景需要处理,比如统计某网站近期top10的账户访问量,再比如,需根据网站的账户活跃程度送积分刺激消费等,尽管通过数据库和程序的计算可以实现,但这种纯粹编程式的解决是否最高效的呢?是否有更合理的解决方案呢?这就是本文接下来将要介绍的,即合理使用redis的不同的数据结构,可以为问题的解决带来意想不到的效果。
二、Redis常用数据类型
redis提供了丰富的数据结构,这也是为什么这么多年来其热度始终不减的重要原因,不同的数据结构都对应着不同的使用场景,可以根据实际需要灵活的选择。
2.1 常见的数据类型
结合实际经验,redis常用的数据类型总结如下:
-
String
-
Hash
-
List
-
Set
-
SortedSet
接下来将针对每种类型进行深入的探讨。
三、String 类型
3.1 String 类型简介
String类型,也就是字符串类型,是Redis中最简单的存储类型。其value是字符串,不过根据字符串的格式不同,又可以分为3类:
-
string:普通字符串;
-
int:整数类型,可以做自增、自减操作;
-
float:浮点类型,可以做自增、自减操作;
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512m
3.2 String常用操作命令
下面列举String类型常用的操作命令
-
SET:添加或者修改已经存在的一个String类型的键值对;
-
GET:根据key获取String类型的value;
-
MSET:批量添加多个String类型的键值对;
-
MGET:根据多个key获取多个String类型的value;
-
INCR:让一个整型的key自增1;
-
INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2;
-
INCRBYFLOAT:让一个浮点类型的数字自增并指定步长;
-
SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行;
-
SETEX:添加一个String类型的键值对,并且指定有效期;
3.2.1 String 操作命令实践
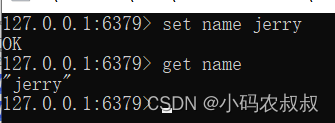
set/get
mset/mget

SETNX

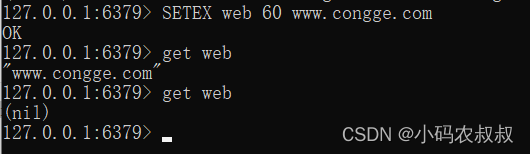
SETEX
3.3 常用业务场景
String类型数据结构简单,使用灵活,基于上述列举的常用命令,结合实际业务经验,下面归纳几种常用的业务使用场景;
3.3.1 session共享
在互联网项目中,登录是必不可少的,如果你的项目是多节点部署,怎么实现用户登录的会话共享呢?一个常见的做法是,将登录产生的关键会话信息,比如token存储在redis中,而token往往就是一个加密的字符串,使用redis的String类型的数据结构就非常合适。
3.3.2 登录失败计数器
可以利用String自增的能力,对用户登录错误次数进行记录,具体来说如下实现思路和步骤如下:
-
登录错误一次,调用incr命令执行一次,key可以为用户的ID,value即为incr的值;
-
当连续登录错误的次数达到特定数字,限制登录;
-
如果未达到一定数量,在下一次登录成功,清理当前的错误记录key;
-
而后再重新开始累计;
下面给出该业务实现的伪代码,具体细节可以结合实际情况继续斟酌;
public String login(User user) {
String userId = user.getId();
if(!user.getUserName().equals("jerry") && !user.getPassWord().equals("123456")){
if (redisTemplate.hasKey(userId)) {
long failCount = (long)redisTemplate.opsForValue().get(userId);
if(failCount < 3){
//如果密码不正确,登录失败,同时记录错误次数的值
redisTemplate.opsForValue().increment(userId,1);
return "登录失败";
}
return "登录失败错误次数超过3次,账户将会被锁定";
}
//首次登录失败
redisTemplate.opsForValue().increment(userId,1);
return "登录失败";
}
//TODO 执行登录业务 ...
//如果登录失败的key值存在,则删除
if(redisTemplate.opsForValue().get(user) != null){
redisTemplate.delete(userId);
}
return "login success";
}3.3.3 限流
在某些场景下,如果系统识别到了某些IP或账户出现异常而频繁刷接口,针对这样的账户或IP可以进行限流,一个比较常见的场景就是发送短信验证码,为了避免用户恶意刷短信,通常的做法是限制1分钟内只允许发一次,大致的思路如下:
-
第一次提交发送短信请求,后台给当前手机号推送一个验证码,同时后台以IP或用户ID为key,在redis中记录一条数据,并设定key的有效期为1分钟;
-
用户输入账户信息以及正确的短信验证码提交请求到后台,验证通过,删除redis中的key;
-
第二步提交请求时,如果验证码输入失败提交到后台,登录失败,此时用户再次点击发送验证码请求,后台检测到redis中存在当前用户ID的key存在,给出异常提示,一般为发送短信过于频繁;
-
一分钟之后,redis中的key过期,用户则可以再次提交发送短信验证码请求;
如下为一段核心伪代码,有兴趣的同学可以对细节进行斟酌完善
public static final String VERIFY_CODE = "login:verify_code:";
public String getSmsVerifyCode(String userId,String phone) {
String smsVerifyCode = getSmsVerifyCode();
String smsCodeKey = VERIFY_CODE + ":" +userId;
Object existedSmsCode = redisTemplate.opsForValue().get(smsCodeKey);
//如果验证码已经存在
if (Objects.nonNull(existedSmsCode)) {
Long expireTime = "从redis中获取当前key的过期时间";
//剩余时间
long lastTime = "总时间" - expireTime;
//三分钟内验证码有效,1分钟到3分钟之间,用户可以继续输入验证码,也可以重新获取验证码,新的验证码将覆盖旧的
if(lastTime > 60 && expireTime >0){
//调用第三方平台发短信,只有短信发送成功了,才能将短信验证码保存到redis
System.out.println("此处调用短信发送逻辑......");
redisTemplate.opsForValue().set(smsCodeKey, smsVerifyCode, "总的过期时间", TimeUnit.SECONDS);
}
//一分钟之内不得多次获取验证码
if(lastTime < 60){
throw new RuntimeException("操作过于频繁,请一分钟之后再次点击发送");
}
}else {
System.out.println("此处调用短信发送逻辑......");
redisTemplate.opsForValue().set(smsCodeKey, smsVerifyCode, "总的过期时间", TimeUnit.SECONDS);
}
return smsVerifyCode;
}
/**
* 随机获取6位短信数字验证码
*
* @return
*/
public static String getSmsVerifyCode() {
Random random = new Random();
String code = "";
for (int i = 0; i < 6; i++) {
int rand = random.nextInt(10);
code += rand;
}
return code;
}3.3.4 多线程安全控制
利用setnx 命令的原子性特点,在多线程并发场景下,作为一种锁进行使用。在redis的相关分布式锁解决方案或SDK中,其底层就利用了setnc的特性实现了锁机制。
四、Hash类型
4.1 hash 数据结构简介
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。通俗来说,hash是一个键值对(key - value)集合,常用于存储对象数据,类似于Java中的Map<String,Object>。
可以采用这样的命名方式(hash格式):对象类别和ID构成键名,使用字段表示对象的属性,而字段值则存储属性值。
如下为hash类型存储数据的示例格式:
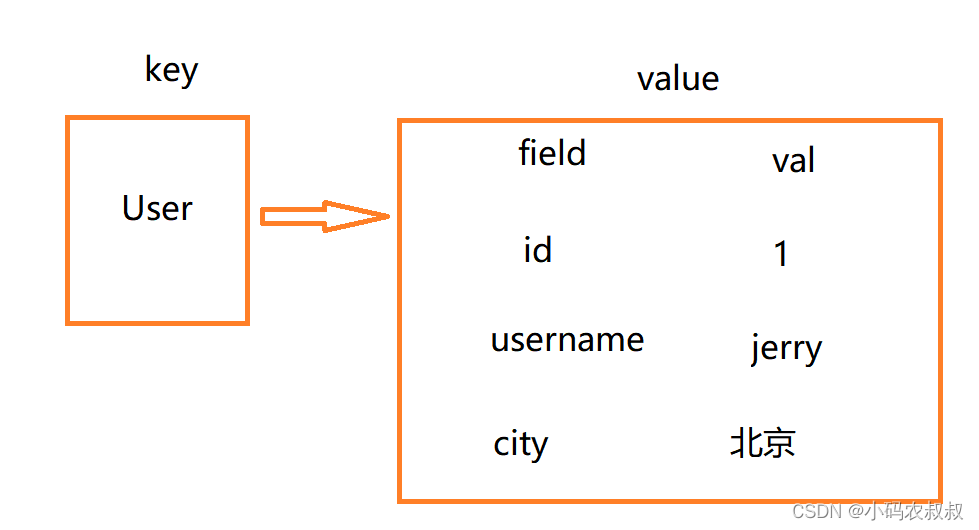
在redis中的存储格式如下:

4.2 为什么使用hash结构
在使用redis做缓存时,使用String类型的结构尽管也能满足多数场景,甚至可以将对象进行json序列化之后以String类型格式存储,但是当程序中涉及到修改对象属性的操作时,使用String类型修改字段属性时就比较麻烦了。总结来说,使用hash可以帮助开发者解决如下问题:
-
可以像Java那样存储对象数据,并能较方便的修改对象中的属性值;
-
hash结构可以针对对象中的每个字段独立存储,即针对单个字段进行增删改查;
-
将具有同一类规则的数据放到redis中的一个数据容器里,便于查找数据;
-
使用hash节省内存。在hash类型中,一个key可以对应多个多个field,一个field对应一个value。相较于每个字段都单独存储成string类型来说,更能节约内存。
4.3 hash 常用操作命令
hash常用的操作命令如下 :
HSET key field value:添加或者修改hash类型key的field的值;
HGET key field:获取一个hash类型key的field的值;
HMSET:批量添加多个hash类型key的field的值;
HMGET:批量获取多个hash类型key的field的值;
HGETALL:获取一个hash类型的key中的所有的field和value;
HKEYS:获取一个hash类型的key中的所有的field;
HVALS:获取一个hash类型的key中的所有的value;
HINCRBY:让一个hash类型key的字段值自增并指定步长;
HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
4.3.1 常用命令操作演示
hset/hget
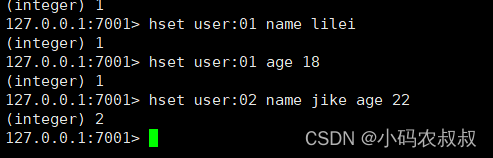
redis中存储的数据格式如下,这个与Java中的对象存储格式是不是很像;

通过命令获取上述添加的对象key;
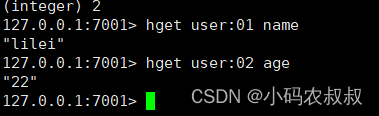
HMSET/HMGET
使用该命令可以批量为一个对象的key存储多个属性值

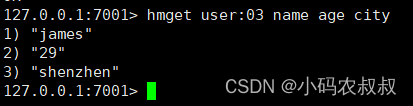
HGETALL
获取一个hash类型的key中的所有的field和value

HKEYS/HVALS
类似于遍历map中的所有key和value

HINCRBY
对hash中的某个字段进行增长,类似于String类型中针对key的字段值自增,可以指定步长

4.4 hash常用业务场景
4.4.1 对象格式存储数据
在程序中对查询的对象数据进行缓存,尽管可以使用String结构对对象进行json序列化再存储,但是后续想要对某个属性进行修改的时候,并不是很方便,所以这种情况下可以考虑使用hash存储,其结构与Java的对象类似,修改属性值很方便。对应的代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = SingleApp.class)
public class RedisHashTest {
@Autowired
private RedisTemplate<String,Object> redisTemplate;
//单个设置
@Test
public void saveSingle(){
redisTemplate.opsForHash().put("user:002","name","jike");
redisTemplate.opsForHash().put("user:002","age",21);
redisTemplate.opsForHash().put("user:002","city","广州");
System.out.println("保存成功");
}
@Test
public void getSingle(){
Object id = redisTemplate.opsForHash().get("user:001", "id");
Object name = redisTemplate.opsForHash().get("user:001", "name");
System.out.println("id:" + id);
System.out.println("name:"+ name);
}
//批量设置多个值
@Test
public void saveHashMulti(){
Map<String,Object> userMap = new HashMap();
userMap.put("id","001");
userMap.put("name","jerry");
userMap.put("age","19");
redisTemplate.opsForHash().putAll("user:001",userMap);
System.out.println("保存成功");
}
//获取多个值
@Test
public void getMultiVal(){
List<Object> objects = redisTemplate.opsForHash().multiGet("user:001", Arrays.asList("id", "name"));
objects.forEach(item ->{
System.out.println(item);
});
}
}对应到redis中的存储格式如下,是不是和对象存储很类似

4.4.2 缓存热点数据
针对下面一些场景,可以有选择的将高频访问并且字段值变动较小的热点数据存储在hash类型的结构中:
-
用户信息:用户基本信息,如用户名、密码、邮箱、手机号码等常用字段;
-
订单数据:订单基本信息,如订单号、下单时间、订单状态、配送地址等,在高并发抢购秒杀中可以考虑使用;
-
商品信息:商品相关信息,如商品名称、价格、库存等;
-
配置信息:应用配置信息,比如中间件的连接配置信息,缓存配置信息,网关配置信息等;
-
统计信息:存储应用程序中计算之后的统计信息,比如网站某用户访问量、用户活跃度、用户购买次数、购买订单数量等;
4.4.3 计数功能
系统中在很多地方可能都会涉及到针对账户的某些行为的统计计数,比如某个账户访问电商网站中的商品详情的次数,下单的次数,购买的次数等等。redis的hash结构中提供了针对计数的功能,因此可以基于这个功能进行实现。伪代码如下:
//1、接口请求;
//2、取出redis中的hash对应的key;
//3、校验key是否存在;
//4、存在key,取出统计值对应的属性字段,执行incr的功能;
//5、返回最新的incr的数值进行展示
4.4.4 数据过滤
比如针对那些恶意刷请求的账户,一旦被系统捕捉到之后,可以将该账户信息存放在hash中,而后系统一旦再次捕捉到相同的账户恶意请求,将会被过滤或给出相关的风险告警。
4.4.5 电商购物车
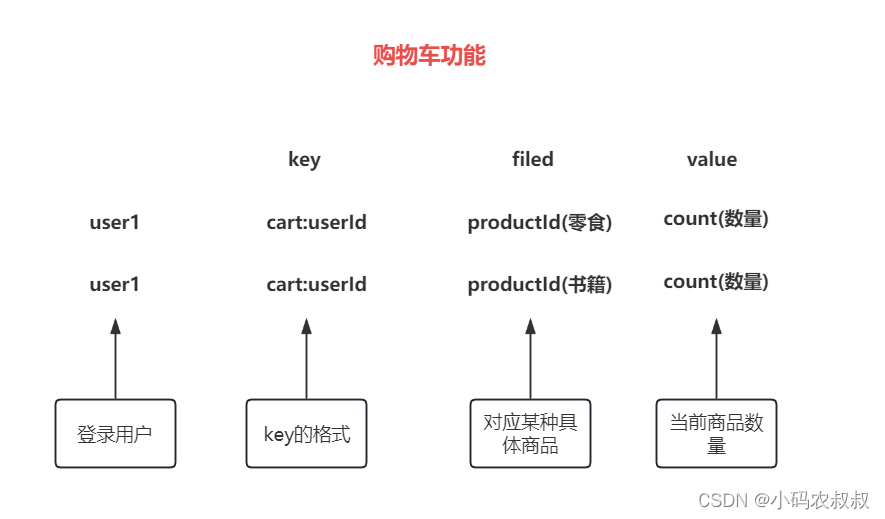
比如在电商购物车中,为了加快页面的性能,可以将账户的购物车信息的关键数据放在hash结构中存储,如下为一个使用hash存储的购物车商品数据的格式和实现思路;
五、List 类型
5.1 list类型简介
List类型与Java中的LinkedList类似,可看做是一个双向链表的结构,既可以支持正向检索和也可以支持反向检索,使用的时候可以类比LinkedList使用。
5.2 list类型特点
-
list类型用来存储多个有序的字符串,列表当中每个字符看做一个元素,内部的数据可以重复;
-
一个列表当中可以存储有一个或者多个元素,redis的list支持存储2^32次方-1个元素;
-
list中的元素有序,redis可以从列表的两端进行插入(pubsh)和弹出(pop)元素,支持读取指定范围的元素集,或者读取指定下标的元素等操作;
-
redis列表是一种比较灵活的链表数据结构,它可以充当队列或者栈的角色;
-
由于其结构与链表类似,插入数据和删除数据较快,数据检索时性能一般;
5.3 list类型常用命令
5.3.1 list命令总结
LPUSH key element ...
向列表左侧插入一个或多个元素;
LPOP key
移除并返回列表左侧的第一个元素,没有则返回nil;
RPUSH key element ...
向列表右侧插入一个或多个元素
RPOP key
移除并返回列表右侧的第一个元素
LRANGE key star end
返回一段角标范围内的所有元素
BLPOP和BRPOP
与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
5.3.2 操作实践
lpush
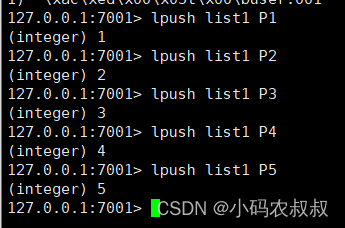
从展示的数据结构效果来看,使用lpush的效果如下:

rpush
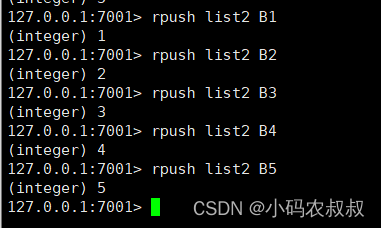
这个正好与lpush相反的效果
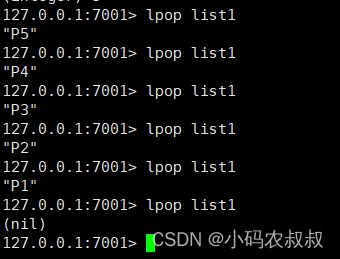
LPOP
从list列表中左边取出元素,以上述list1为例,从左到右的元素依次为:p5,p4,p3,p2,p1,设想到使用该命令时,p5元素将首先被取出,没有元素的时候将会返回 nil,RPOP与之相反;
LRANGE
取出指定下标范围的数据
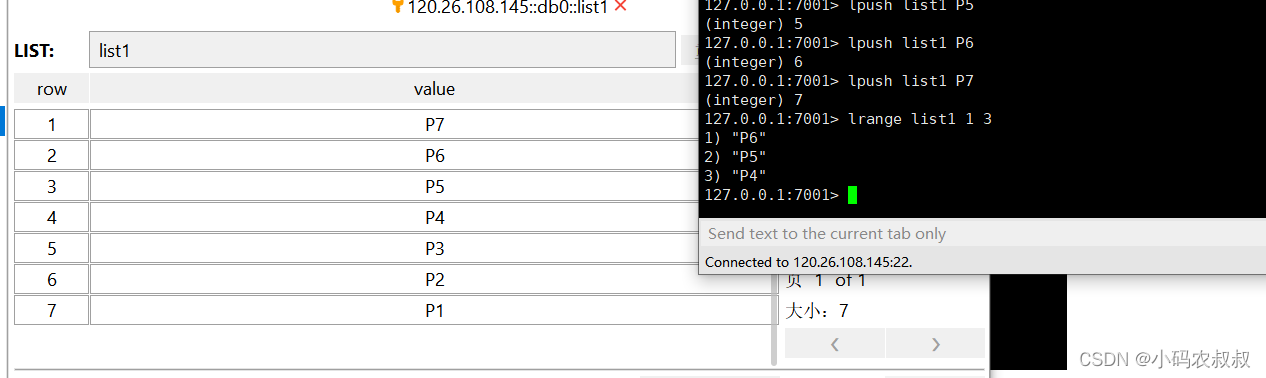
BLPOP
类似于一个阻塞队列的效果,会阻塞等待从list中获取元素,没有元素返回nil,如下,使用BLPOP从list3中等待获取元素,显然list3目前并不存在,也没有元素,所以执行这个命令之后,可以看的阻塞的效果,第三个参数为阻塞等待的时间,即可以不用无限的等待下去;

此时在另一个客户端给list3添加一条元素,看到如下效果
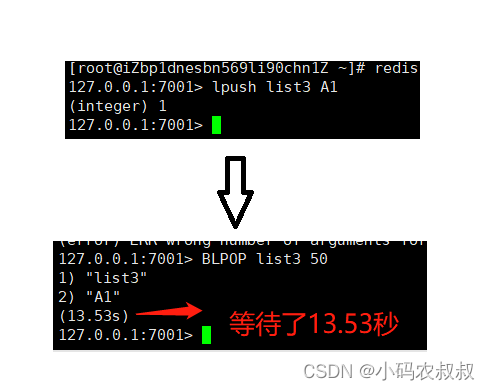
5.4 list使用场景
5.4.1 实现常用的分布式数据结构
结合上述的操作实践,利用list的特点,可以实现如下常用几种数据结构
-
Stack(栈) : LPUSH + LPOP;
-
Queue(队列):LPUSH + RPOP;
-
Blocking MQ(阻塞队列) : LPUSH + BRPOP;
通过下面的代码以及输出结果可以清晰的看到栈的效果
@Test
public void saveList(){
redisTemplate.opsForList().leftPush("user1","jerry");
redisTemplate.opsForList().leftPush("user1","mike");
redisTemplate.opsForList().leftPush("user1","hang");
System.out.println("插入3个元素,分别为:jerry,mike,hang");
System.out.println("============");
List<Object> user1 = redisTemplate.opsForList().range("user1", 0, 3);
user1.forEach(item ->{
System.out.println("依次取出当前的元素:" + item);
});
System.out.println("============");
Object user11 = redisTemplate.opsForList().leftPop("user1");
Object user12 = redisTemplate.opsForList().leftPop("user1");
Object user13 = redisTemplate.opsForList().leftPop("user1");
System.out.println("取出的元素依次为:" + user11 + "," + user12 + "," + user13);
}
5.4.2 抢购秒杀
了解抢购秒杀业务场景的同学应该对此不陌生,在针对某种具体的商品抢购正式开始之前,需要定好本次参与抢购的商品数量,如果抢购时直接操作数据库,这个性能是低效的,所以可以考虑使用redis的list结构,将参与抢购的商品ID列表提前初始化到list中,抢购的时候,商品直接从list中取出即可。主要实现思路如下:
1、参与抢购的商品打散放入list;
2、开始抢购时调用pop命令从list中取出;
3、将抢购成功的用户以及商品ID记录写入到数据库;
4、后续的其他业务处理;
下面是一段核心的关于抢购的代码,可供参考,第一段为将参与抢购的商品预存到list中,第二段为抢购的逻辑
@Resource
private RedisTemplate redisTemplate;
@Scheduled(cron = "0/5 * * * * ?")
public void startSecKill(){
List<PromotionSecKill> list = promotionSecKillMapper.findUnstartSecKill();
for(PromotionSecKill ps : list){
System.out.println(ps.getPsId() + "秒杀活动启动");
//删掉以前重复的活动任务缓存
redisTemplate.delete("seckill:count:" + ps.getPsId());
/**
* 有多少库存商品,则初始化几个list对象
* 实际业务中,可能是拿出部分商品参与秒杀活动,通过后台的界面进行设置
*/
for(int i = 0 ; i < ps.getPsCount() ; i++){
redisTemplate.opsForList().rightPush("seckill:count:" + ps.getPsId() , ps.getGoodsId());
}
ps.setStatus(1);
}
}抢购逻辑
@Resource
private RedisTemplate redisTemplate;
public void processSecKill(Long psId, String userid, Integer num) throws SecKillException {
PromotionSecKill ps = promotionSecKillMapper.findById(psId);
if (ps == null) {
throw new SecKillException("秒杀活动不存在");
}
if (ps.getStatus() == 0) {
throw new SecKillException("秒杀活动未开始");
} else if (ps.getStatus() == 2) {
throw new SecKillException("秒杀活动已结束");
}
Integer goodsId = (Integer) redisTemplate.opsForList().leftPop("seckill:count:" + ps.getPsId());
if (goodsId != null) {
//判断是否已经抢购过
boolean isExisted = redisTemplate.opsForSet().isMember("seckill:users:" + ps.getPsId(), userid);
if (!isExisted) {
System.out.println("抢到商品啦,快去下单吧");
redisTemplate.opsForSet().add("seckill:users:" + ps.getPsId(), userid);
}else{
redisTemplate.opsForList().rightPush("seckill:count:" + ps.getPsId(), ps.getGoodsId());
throw new SecKillException("抱歉,您已经参加过此活动,请勿重复抢购!");
}
} else {
throw new SecKillException("抱歉,该商品已被抢光,下次再来吧!");
}
}5.4.3 消息队列
利用redis的BLPOP的特性,可以实现消息队列,生产者将消息推送到list中,而消费者通过BLOP阻塞式的从;list中获取消息进行消费。
5.4.4 排行榜
利用list的数据有序性以及支持索引访问元素的特性,提前将排好序的元素存放到list中,比如玩家的积分,个人学习时长等,然后取出的数据就可以从高到低排序实现一个排行榜的效果。
5.4.5 分页查询效果
基于list支持索引访问元素,以及可以通过range访问元素的特点,可以实现数据的分页,当然这样的数据通常是高频查询的热点数据的ID或唯一性元素。
5.4.6 流量削峰
在业务高峰期,如果系统的服务器处理请求的能力有限,可以考虑将请求全部放到list中,然后开启多个线程来处理后续请求,以减轻服务器压力,可以用来处理一些高并发场景。
六、Set 类型
6.1 Set简介
redis集合(set)类型和list列表类型类似,都可用来存储多个字符串元素的集合。但是和list不同的是set集合当中不允许重复的元素。而且set集合当中元素是没有顺序的,不存在元素下标。
set类型是使用哈希表构造的,因此复杂度是O(1),它支持集合内的增删改查,并且支持多个集合间的交集、并集、差集操作。与Java中的set可以对比理解使用,可以利用这些集合操作,解决开发过程很多数据集合间的问题。
6.2 Set 类型常用命令
Set常用的操作命令总结如下:
-
SADD key member ... :向set中添加一个或多个元素;
-
SREM key member ... : 移除set中的指定元素;
-
SCARD key: 返回set中元素的个数;
-
SISMEMBER key member:判断一个元素是否存在于set中;
-
SMEMBERS:获取set中的所有元素;
-
SINTER key1 key2 ... :求key1与key2的交集;
-
SDIFF key1 key2 ... :求key1与key2的差集;
-
SUNION key1 key2 ..:求key1和key2的并集;
6.3 Set命令操作使用
6.3.1 常用命令操作演示
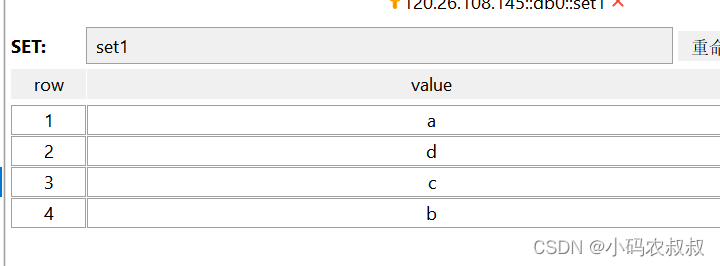
sadd/smembers
添加元素并查看元素
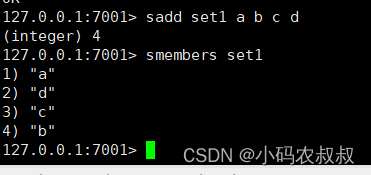
可以看到,set中存储元素是无序的
SREM
删除set中的元素

SCARD
返回元素个数

SISMEMBER
判断某个元素是否在set中
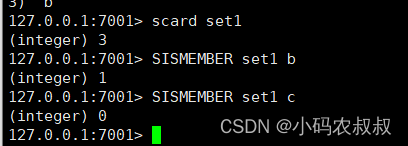
SINTER key1 key2
求两个set的交集

6.3.2 核心API
如下是使用redisTemplate操作set的相关API
@Test
public void opeSet(){
redisTemplate.opsForSet().add("set1","a","b","c","d","e");
redisTemplate.opsForSet().add("set2","d","e","f","j");
Set<Object> set1 = redisTemplate.opsForSet().members("set1");
set1.forEach(item ->{
System.out.println("item :" + item);
});
//是否set的元素
Boolean member = redisTemplate.opsForSet().isMember("set1", "a");
System.out.println(member);
//求交集
Set<Object> difference = redisTemplate.opsForSet().difference("set1", "set2");
difference.forEach(item ->{
System.out.println(item);
});
}6.4 Set使用场景
6.4.1 用户关注、推荐模型
比如在社交类网站中,我的关注、我的粉丝,类似这样的操作使用Set就是不错的选择。
user1 : 我的粉丝:
sadd user1:fans user2 sadd user1:fans user4 sadd user1:fans user5 ...
user2 : 我关注的人:
sadd user2:follow user1 sadd user2:follow user3 sadd user2:follow user5 sadd user2:follow user7 ...
基于上述的数据,可以分别求 user1 和 user2 可能认识的人,这就是粉丝或关注推荐
6.4.2 商品/用户画像标签
在电商或团购类网站中,经常看到某些商品的详情下面,被打上了很多标签,比如某款水果类商品,口感好,新鲜,发货快等等,可以考虑使用set来保存标签信息;
sadd tags:productId "口感好"
sadd tags:productId "新鲜"
sadd tags:productId "发货快
6.4.3 抽奖
利用set中的 SRANDMEMBER 结合 SPOP 的操作,可以实现抽奖的功能,即从set集合中每次随机得到指定数量的元素,实现思路如下:
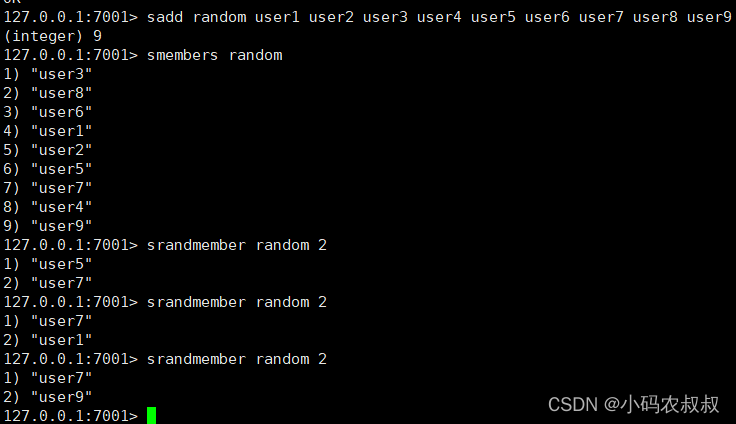
sadd random user1 user2 user3 user4 user5 user6 user7 user8 user9
srandmember random 2 #随机取出指定数量的元素,不删除
spop random 2 #随机取出指定数量的元素,删除元素
抽完一次时,被抽过的人还可以继续参与抽奖,使用srandmember ;
抽完一次时,被抽过的人从set中剔除,不能继续参与抽奖,使用spop ;

6.4.4 点赞、收藏、喜欢数
在某些社交app、微博或短视频类app中,经常看到的那些点赞、收藏或喜欢的功能,可以基于set来实现,实现思路如下:
点赞
sadd like:视频ID {userId}
取消点赞
srem like:视频ID {userId}
用户是否点赞
sismember like:视频ID {userId}
点赞的用户列表
smembers like:视频ID
获取点赞的用户数量
scard like:视频ID
6.4.5 统计网站的独立IP
利用set集合当中元素的唯一性,可以快速实时统计访问网站的独立IP。
七、SortedSet
7.1 SortedSet概述
SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可基于score属性对元素做排序,其底层的实现是一个跳表(SkipList)加 hash表。
有序集合可以利用分数进行从小到大的排序。虽然有序集合的成员是唯一的,但是分数(score)却可以重复。就比如在一个班中,学生的学号是唯一的,但是每科成绩却是可以一样的,redis可以利用有序集合存储学生成绩快速做成绩排名功能。
7.1.1 SortedSet特点
SortedSet具备如下特性:
-
可排序;
-
元素不重复;
-
查询速度快;
7.2 常用操作命令
SortedSet常用操作命令如下:
-
ZADD key score member:添加一个或多个元素到sorted set ,如果已存在则更新其score值;
-
ZREM key member:删除sorted set中的一个指定元素;
-
ZSCORE key member : 获取sorted set中的指定元素的score值;
-
ZRANK key member:获取sorted set 中的指定元素的排名;
-
ZCARD key:获取sorted set中的元素个数;
-
ZCOUNT key min max:统计score值在给定范围内的所有元素的个数;
-
ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值;
-
ZRANGE key min max:按照score排序后,获取指定排名范围内的元素;
-
ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素;
-
ZDIFF、ZINTER、ZUNION:求差集、交集、并集;
注意:默认情况下使用SortedSet时,集合中元素排名都是升序,如要降序则在命令后添加REV;
7.2 .1 操作命令演示
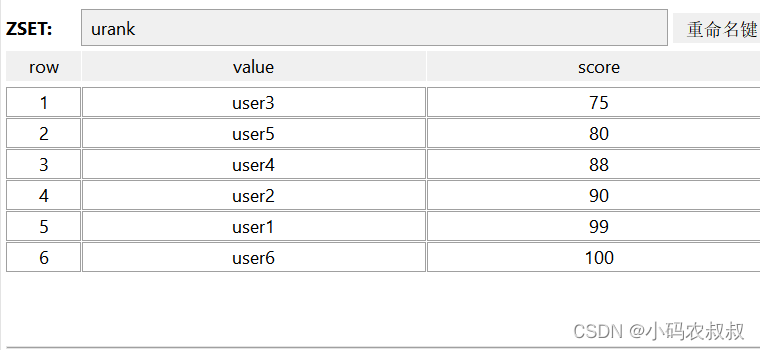
ZADD
添加一个或多个元素到SortedSet

从添加的数据来看,SortedSet中的元素是有序的,即按照分数进行了升序排序
ZSCORE key member
获取指定元素的score值

ZRANK key member
获取指定元素的排名

7.2 .2 核心操作API
如下列举了常用的API操作,当然远不止这些,可以在此基础上继续操作实践
@Test
public void opeZSet(){
//添加元素
redisTemplate.opsForZSet().add("urank","user1",99);
redisTemplate.opsForZSet().add("urank","user2",88);
redisTemplate.opsForZSet().add("urank","user3",95);
redisTemplate.opsForZSet().add("urank","user4",79);
redisTemplate.opsForZSet().add("urank","user5",82);
//获取某个元素的分值
Double score = redisTemplate.opsForZSet().score("urank", "user1");
System.out.println(score);
//统计排名0~3的元素
Set<Object> users = redisTemplate.opsForZSet().range("urank", 0, 3);
users.forEach(item ->{
System.out.println(item);
});
//获取某元素的排名
Long rank = redisTemplate.opsForZSet().rank("urank", "user5");
System.out.println(rank);
}7.3 SortedSet使用场景
7.3.1 排行榜(TOP N)
在很多网站都有排行的功能,比如新闻类网站可以按照阅读数或点赞量最高的排到最前面,游戏网站中根据个人玩家积分进行排名等,类似的场景还有很多,都可以基于SortedSet中的分数来实现。
7.3.2 带权重的消息队列
使用SortedSet可以实现一个带权重的消息队列,具体来说,将不同的消息赋予不同的权重存入SortedSet,消费消息时,可以优先获取权重高的消息进行处理;
7.3.3 滑动窗口限流
将score作为时间戳,可统计最近一段时间内的成员数量,实现滑动窗口限流。
7.3.4 精准设定过期时间的数据
可以把sorted set中score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把 Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。
八、写在文末
关于redis的常用数据类型,可以说在日常的工作中随处可见,系统学习并深入掌握这些不同数据结构的使用,在面对复杂多变的业务场景时可以更好的为开发人员提供高效的解决方案,加快问题的解决效率,同时也是作为一个优秀的开发工程师必备的技能。