python爬虫9:实战2
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
申明
本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好影响。
目录结构
文章目录
1. 目标
这次爬虫实战,采用的库为:requests + bs4,这次的案例来自于python爬虫7:实战1这篇文章,本次主要的点在于利用bs4进行解析,因此,建议大家先阅读python爬虫7:实战1,因为里面的代码我会直接拷贝过来用。
再次说明,案例本身并不重要,重要的是如何去使用和分析,另外为了避免侵权之类的问题,我不会放涉及到网站的图片,希望能理解。
2. 详细流程
2.1 前置说明
由于不需要重新写大部分代码,因此本篇主要讲解一下如何用bs4去解析网页。
这里先把之前的代码拷贝过来:
# 导包
import requests
from lxml import etree
# 都要用到的参数
HEADERS = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
# 获取搜索某小说后的页面
def get_search_result():
# 网址
url = 'https://www.iwurexs.net/so.html'
# 请求参数
search = input('请输入想要搜索的小说:')
params = {
'q' : search
}
# 请求
response = requests.get(url,headers=HEADERS,params=params)
# 把获取到的网页保存到本地
with open('search.html', 'w', encoding='utf-8') as f:
f.write(response.content.decode('utf-8'))
# 解析网页
def parse_search_result():
# 打开文件,读取文件
with open('search.html', 'r', encoding='utf-8') as f:
content = f.read()
# 基础url
base_url = 'https://www.iwurexs.net/'
# 初始化lxml
html = etree.HTML(content)
# 获取目标节点
href_list = html.xpath('//div[@class="show"]//table[@class="grid"]//td//a/@href')
text_list = html.xpath('//div[@class="show"]//table[@class="grid"]//td//a/text()')
# 处理内容值
url_list = [base_url+href for href in href_list]
# 选择要爬取的小说
for i,text in enumerate(text_list):
print('当前小说名为:',text)
decision = input('是否爬取它(只能选择一本),Y/N:')
if decision == 'Y':
return url_list[i],text
# 请求目标小说网站
def get_target_book(url):
# 请求
response = requests.get(url,headers=HEADERS)
# 保存源码
with open('book.html', 'w', encoding='utf-8') as f:
f.write(response.content.decode('utf-8'))
# 解析章节网页
def parse_chapter(base_url):
# 打开文件,读取内容
with open('book.html', 'r', encoding='utf-8') as f:
content = f.read()
# 初始化
html = etree.HTML(content)
# 解析
href_list = html.xpath('//div[@class="show"]//div[contains(@class,"showBox") and position()=3]//ul//a/@href')
text_list = html.xpath('//div[@class="show"]//div[contains(@class,"showBox") and position()=3]//ul//a/text()')
# 处理:拼凑出完整网页
url_list = [base_url+url for url in href_list]
# 返回结果
return url_list,text_list
# 请求小说页面
def get_content(url,title):
# 请求
response = requests.get(url,headers=HEADERS)
# 获取源码
content = response.content.decode('utf-8')
# 初始化
html = etree.HTML(content)
# 解析
text_list = html.xpath('//div[contains(@class,"book")]//div[@id="content"]//text()')
# 后处理
# 首先,把第一个和最后一个的广告信息去掉
text_list = text_list[1:-1]
# 其次,把里面的空白字符和\xa0去掉
text_list = [text.strip().replace('\xa0','') for text in text_list]
# 最后,写入文件即可
with open(title+'.txt','w',encoding='utf-8') as g:
for text in text_list:
g.write(text+'\n')
if __name__ == '__main__':
# 第一步,获取到搜索页面的源码
# get_search_result()
# 第二步,进行解析
target_url,name = parse_search_result()
# 第三步,请求目标小说页面
get_target_book(target_url)
# 第四步,解析章节网页
url_list,text_list = parse_chapter(target_url)
for url,title in zip(url_list,text_list):
# 第五步,请求小说具体的某个章节并直接解析
get_content(url,title)
break
其中需要修改的部分有:三个解析函数。
2.2 修改1:目标小说获取解析函数修改
本次要修改的函数名为parse_search_result。
那么,看下图:

那么,我们可以这么去寻找a标签:
1. 找到table标签,其class="grid"
2. 找到table下的a标签即可
那么,代码修改如下:
# 解析网页
def parse_search_result():
# 打开文件,读取文件
with open('search.html', 'r', encoding='utf-8') as f:
content = f.read()
# 基础url
base_url = 'https://www.iwurexs.net/'
# 初始化lxml
soup = BeautifulSoup(content,'lxml')
# 获取目标节点
a_list = soup.find_all('table',attrs={
'class':'grid'})[0].find_all('a')
url_list = [base_url + a['href'] for a in a_list]
text_list = [a.string for a in a_list]
# 选择要爬取的小说
for i,text in enumerate(text_list):
print('当前小说名为:',text)
decision = input('是否爬取它(只能选择一本),Y/N:')
if decision == 'Y':
return url_list[i],text
运行结果如下:

2.3 修改2:章节目录获取解析函数修改
本次要修改的函数名为parse_chapter。
首先,还是看下图:

那么,可以这么进行解析:
1. 首先,获取所有含有class="showBox"的div标签,共三个,但是我们只要第三个
2. 其次,获取该div下的所有a标签即可
那么,代码修改如下:
# 解析章节网页
def parse_chapter(base_url):
# 打开文件,读取内容
with open('book.html', 'r', encoding='utf-8') as f:
content = f.read()
# 初始化
soup = BeautifulSoup(content,'lxml')
# 解析
# 获取最后一个div标签
div_label = soup.find_all('div',attrs={
'class':'showBox'})[-1]
# 获取所有a标签
a_list = div_label.find_all('a')
# 获取内容
url_list = [base_url+a['href'] for a in a_list]
text_list = [a.string for a in a_list]
# 返回结果
return url_list,text_list
运行结果如下:

2.4 修改3:获取小说内容解析函数修改
本次要修改的函数名为get_content。
首先,还是看下图:

那么,可以这么进行解析:
1. 直接获取id=“content”的div标签
2. 在获取其下的所有内容
那么,修改代码如下:
# 请求小说页面
def get_content(url,title):
# 请求
response = requests.get(url,headers=HEADERS)
# 获取源码
content = response.content.decode('utf-8')
# 初始化
soup = BeautifulSoup(content,'lxml')
# 解析
text_list = list(soup.find_all('div',attrs={
'id':'content'})[0].stripped_strings)
# 后处理
# 首先,把第一个和最后一个的广告信息去掉
text_list = text_list[1:-1]
# 其次,把里面的空白字符和\xa0去掉
text_list = [text.strip().replace('\xa0','') for text in text_list]
# 最后,写入文件即可
with open(title+'.txt','w',encoding='utf-8') as g:
for text in text_list:
g.write(text+'\n')
最终运行结果如下:
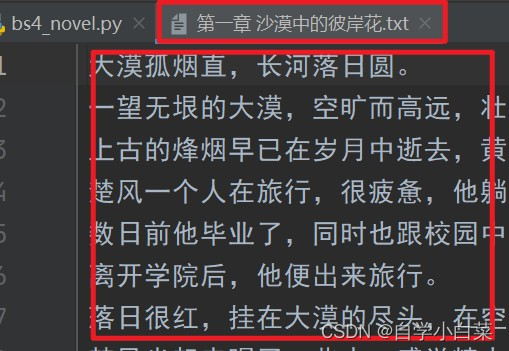
2.5 完整代码:
# 导包
import requests
from bs4 import BeautifulSoup
# 都要用到的参数
HEADERS = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
# 获取搜索某小说后的页面
def get_search_result():
# 网址
url = 'https://www.iwurexs.net/so.html'
# 请求参数
search = input('请输入想要搜索的小说:')
params = {
'q' : search
}
# 请求
response = requests.get(url,headers=HEADERS,params=params)
# 把获取到的网页保存到本地
with open('search.html', 'w', encoding='utf-8') as f:
f.write(response.content.decode('utf-8'))
# 解析网页
def parse_search_result():
# 打开文件,读取文件
with open('search.html', 'r', encoding='utf-8') as f:
content = f.read()
# 基础url
base_url = 'https://www.iwurexs.net/'
# 初始化lxml
soup = BeautifulSoup(content,'lxml')
# 获取目标节点
a_list = soup.find_all('table',attrs={
'class':'grid'})[0].find_all('a')
url_list = [base_url + a['href'] for a in a_list]
text_list = [a.string for a in a_list]
# 选择要爬取的小说
for i,text in enumerate(text_list):
print('当前小说名为:',text)
decision = input('是否爬取它(只能选择一本),Y/N:')
if decision == 'Y':
return url_list[i],text
# 请求目标小说网站
def get_target_book(url):
# 请求
response = requests.get(url,headers=HEADERS)
# 保存源码
with open('book.html', 'w', encoding='utf-8') as f:
f.write(response.content.decode('utf-8'))
# 解析章节网页
def parse_chapter(base_url):
# 打开文件,读取内容
with open('book.html', 'r', encoding='utf-8') as f:
content = f.read()
# 初始化
soup = BeautifulSoup(content,'lxml')
# 解析
# 获取最后一个div标签
div_label = soup.find_all('div',attrs={
'class':'showBox'})[-1]
# 获取所有a标签
a_list = div_label.find_all('a')
# 获取内容
url_list = [base_url+a['href'] for a in a_list]
text_list = [a.string for a in a_list]
# 返回结果
return url_list,text_list
# 请求小说页面
def get_content(url,title):
# 请求
response = requests.get(url,headers=HEADERS)
# 获取源码
content = response.content.decode('utf-8')
# 初始化
soup = BeautifulSoup(content,'lxml')
# 解析
text_list = list(soup.find_all('div',attrs={
'id':'content'})[0].stripped_strings)
# 后处理
# 首先,把第一个和最后一个的广告信息去掉
text_list = text_list[1:-1]
# 其次,把里面的空白字符和\xa0去掉
text_list = [text.strip().replace('\xa0','') for text in text_list]
# 最后,写入文件即可
with open(title+'.txt','w',encoding='utf-8') as g:
for text in text_list:
g.write(text+'\n')
if __name__ == '__main__':
# 第一步,获取到搜索页面的源码
# get_search_result()
# 第二步,进行解析
target_url,name = parse_search_result()
# 第三步,请求目标小说页面
get_target_book(target_url)
# # 第四步,解析章节网页
url_list,text_list = parse_chapter(target_url)
for url,title in zip(url_list,text_list):
# 第五步,请求小说具体的某个章节并直接解析
get_content(url,title)
break
3. 总结
本次实战主要目的还是帮助大家熟悉bs4这个库的使用技巧,实战只是顺带的,懂得如何运行这个工具比懂得如何爬取一个网站更加重要。
除此之外,不难看出,lxml库更像一个从上到下的定位模式,你想要获取某一个标签,首先需要考虑其上某个更加具体的标签;而bs4则更直接,如果你要获取的标签比较特别,可以直接定位它,而无需通过其他关系来确定。
下一篇,开始讲解如何解决动态网页,即selenium库。