之前一直很迷茫Java对象中存储的是什么,经过一段时间的学习。今天过来总结一下。希望能对看到的人有所帮助。
一、总体概况
在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。下图是普通对象实例与数组对象实例的数据结构:

对象头
HotSpot虚拟机的对象头包括两部分信息:
- Mark Word
MarkWord用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为32bit和64bit,官方称它为“MarkWord”。 - Klass Word
Klass Word是klass类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例. - 数组长度(只有数组对象有)
如果对象是一个数组, 那在对象头中还必须有一块数据用于记录数组长度.
实例数据
- 实例数据是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。
对齐填充
- 对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说,就是对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或者2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。(其实主要还是为了降低垃圾碎片)
深入了解
了解了对象的总体结构,接下来深入地了解对象头的三个部分。
Mark Word(标记字)
在openjdk的源码中这样描述对象头markword:
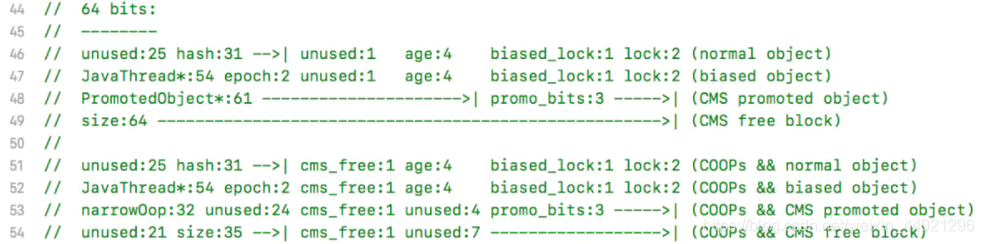
将源码内容进行一下翻译,得到下面的这个图标形式,接下来我们详细说明一下这个表。

这个表格中,每一行都是一个对象的处于某种状态时的样子。
lock: 2位的锁状态标记位,由于希望用尽可能少的二进制位表示尽可能多的信息,所以设置了lock标记。该标记的值不同,整个Mark Word表示的含义不同。biased_lock和lock一起,表达的锁状态含义如下:
biased_lock:对象是否启用偏向锁标记,只占1个二进制位。为1时表示对象启用偏向锁,为0时表示对象没有偏向锁。lock和biased_lock共同表示对象处于什么锁状态。
age:4位的Java对象年龄。在GC中,如果对象在Survivor区复制一次,年龄增加1。当对象达到设定的阈值时,将会晋升到老年代。默认情况下,并行GC的年龄阈值为15,并发GC的年龄阈值为6。由于age只有4位,所以最大值为15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因。
identity_hashcode:31位的对象标识hashCode,采用延迟加载技术。调用方法System.identityHashCode()计算,并会将结果写到该对象头中。当对象加锁后(偏向、轻量级、重量级),MarkWord的字节没有足够的空间保存hashCode,因此该值会移动到管程Monitor中。
thread:持有偏向锁的线程ID。
epoch:偏向锁的时间戳。
ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。
ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。
留一个更加直观的图。
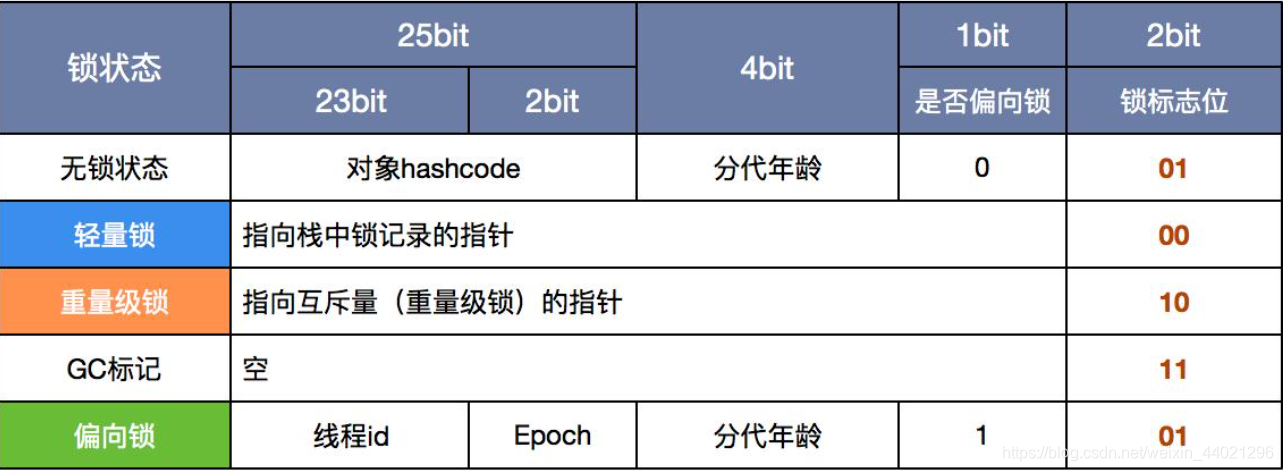
我们通常说的通过synchronized实现的同步锁,真实名称叫做重量级锁。但是重量级锁会造成线程排队(串行执行),且会使CPU在用户态和核心态之间频繁切换,所以代价高、效率低。为了提高效率,不会一开始就使用重量级锁,JVM在内部会根据需要,进行锁的升级。
这里我们先说明一下这几种锁:
锁的分类:
- 无锁
无锁是指没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
无锁的特点是修改操作会在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。 - 偏向锁
初次执行到synchronized代码块的时候,锁对象变成偏向锁(通过CAS修改对象头里的锁标志位),字面意思是“偏向于第一个获得它的线程”的锁。执行完同步代码块后,线程并不会主动释放偏向锁。当第二次到达同步代码块时,线程会判断此时持有锁的线程是否就是自己(持有锁的线程ID也在对象头里),如果是则正常往下执行。由于之前没有释放锁,这里也就不需要重新加锁。如果自始至终使用锁的线程只有一个,很明显偏向锁几乎没有额外开销,性能极高。偏向锁是指当一段同步代码一直被同一个线程所访问时,即不存在多个线程的竞争时,那么该线程在后续访问时便会自动获得锁,从而降低获取锁带来的消耗,即提高性能。当一个线程访问同步代码块并获取锁时,会在 Mark Word 里存储锁偏向的线程 ID。在线程进入和退出同步块时不再通过 CAS 操作来加锁和解锁,而是检测 Mark Word 里是否存储着指向当前线程的偏向锁。轻量级锁的获取及释放依赖多次 CAS 原子指令,而偏向锁只需要在置换 ThreadID 的时候依赖一次 CAS 原子指令即可。偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程是不会主动释放偏向锁的。关于偏向锁的撤销,需要等待全局安全点,即在某个时间点上没有字节码正在执行时,它会先暂停拥有偏向锁的线程,然后判断锁对象是否处于被锁定状态。如果线程不处于活动状态,则将对象头设置成无锁状态,并撤销偏向锁,恢复到无锁(标志位为01)或轻量级锁(标志位为00)的状态。 - ** 轻量级锁(自旋锁)**
 轻量级锁是指当锁是偏向锁的时候,却被另外的线程所访问,此时偏向锁就会升级为轻量级锁,其他线程会通过自旋(关于自旋的介绍见文末)的形式尝试获取锁,线程不会阻塞,从而提高性能。
轻量级锁是指当锁是偏向锁的时候,却被另外的线程所访问,此时偏向锁就会升级为轻量级锁,其他线程会通过自旋(关于自旋的介绍见文末)的形式尝试获取锁,线程不会阻塞,从而提高性能。
轻量级锁的获取主要由两种情况:
① 当关闭偏向锁功能时;
② 由于多个线程竞争偏向锁导致偏向锁升级为轻量级锁。
一旦有第二个线程加入锁竞争,偏向锁就升级为轻量级锁(自旋锁)。这里要明确一下什么是锁竞争:如果多个线程轮流获取一个锁,但是每次获取锁的时候都很顺利,没有发生阻塞,那么就不存在锁竞争。只有当某线程尝试获取锁的时候,发现该锁已经被占用,只能等待其释放,这才发生了锁竞争。
在轻量级锁状态下继续锁竞争,没有抢到锁的线程将自旋,即不停地循环判断锁是否能够被成功获取。获取锁的操作,其实就是通过CAS修改对象头里的锁标志位。先比较当前锁标志位是否为“释放”,如果是则将其设置为“锁定”,比较并设置是原子性发生的。这就算抢到锁了,然后线程将当前锁的持有者信息修改为自己。长时间的自旋操作是非常消耗资源的,一个线程持有锁,其他线程就只能在原地空耗CPU,执行不了任何有效的任务,这种现象叫做忙等(busy-waiting)。如果多个线程用一个锁,但是没有发生锁竞争,或者发生了很轻微的锁竞争,那么synchronized就用轻量级锁,允许短时间的忙等现象。这是一种折衷的想法,短时间的忙等,换取线程在用户态和内核态之间切换的开销。 - 重量级锁
重量级锁显然,此忙等是有限度的(有个计数器记录自旋次数,默认允许循环10次,可以通过虚拟机参数更改)。如果锁竞争情况严重,某个达到最大自旋次数的线程,会将轻量级锁升级为重量级锁(依然是CAS修改锁标志位,但不修改持有锁的线程ID)。当后续线程尝试获取锁时,发现被占用的锁是重量级锁,则直接将自己挂起(而不是忙等),等待将来被唤醒。重量级锁是指当有一个线程获取锁之后,其余所有等待获取该锁的线程都会处于阻塞状态。简言之,就是所有的控制权都交给了操作系统,由操作系统来负责线程间的调度和线程的状态变更。而这样会出现频繁地对线程运行状态的切换,线程的挂起和唤醒,从而消耗大量的系统资源。
说到这里,相信大家对锁升级应该有了一定的了解了!!!
Klass Word(类指针)
这一部分用于存储对象的类型指针,该指针指向它的类元数据,JVM通过这个指针确定对象是哪个类的实例。该指针的位长度为JVM的一个字大小,即32位的JVM为32位,64位的JVM为64位。
如果应用的对象过多,使用64位的指针将浪费大量内存,统计而言,64位的JVM将会比32位的JVM多耗费50%的内存。为了节约内存可以使用选项+UseCompressedOops开启指针压缩,其中,oop即ordinary object pointer普通对象指针。开启该选项后,下列指针将压缩至32位:
每个Class的属性指针(即静态变量)
每个对象的属性指针(即对象变量)
普通对象数组的每个元素指针
当然,也不是所有的指针都会压缩,一些特殊类型的指针JVM不会优化,比如指向PermGen的Class对象指针(JDK8中指向元空间的Class对象指针)、本地变量、堆栈元素、入参、返回值和NULL指针等
数组长度
如果对象是一个数组,那么对象头还需要有额外的空间用于存储数组的长度,这部分数据的长度也随着JVM架构的不同而不同:32位的JVM上,长度为32位;64位JVM则为64位。64位JVM如果开启+UseCompressedOops选项,该区域长度也将由64位压缩至32位
对象大小计算
要点
- 在32位系统下,存放Class指针的空间大小是4字节,MarkWord是4字节,对象头为8字节。
- 在64位系统下,存放Class指针的空间大小是8字节,MarkWord是8字节,对象头为16字节。
- 64位开启指针压缩的情况下,存放Class指针的空间大小是4字节,MarkWord是8字节,对象头为12字节。 数组长度4字节+数组对象头8字节(对象引用4字节(未开启指针压缩的64位为8字节)+数组markword为4字节(64位未开启指针压缩的为8字节))+对齐4=16字节。
- 静态属性不算在对象大小内。