一、感知机
1.感知机是具有输入和输出的算法。给定一个输入后将输出一个既定的值。
图形:
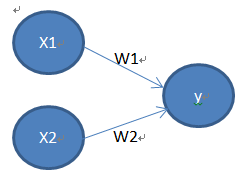
公式:其中w1为权重——控制输入信号的重要性;b为偏置——调整神经元被激活的容易程度。
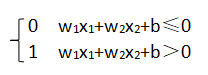
2.“门”的作用:感知机→(门)→应用、计算。
这里的门指:与门、与非门、或门。
它们是具有相同构造的感知机,是线性的,区别只在于权重参数的值。
异或门是非线性的,不能像上述三个门一样通过单层感知机实现,这也是感知机的局限性所在。
感知机的局限性:只能表示线性空间,而不能表示非线性。
要想让非线性能够实现,采用叠加的多层感知机。
二、神经网络
1.输入层→中间层(隐藏层)→输出层
2.非线性问题需要用到激活函数,将输入信号的总和转换为输出信号。
学习过程: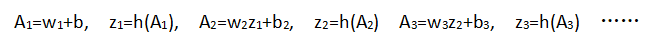
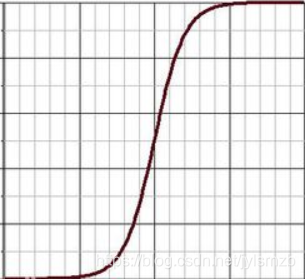
3.激活函数:sigmoid函数、阶跃函数、ReLU函数(常用),图像分别如下:
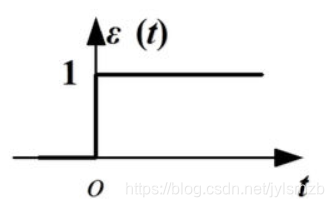
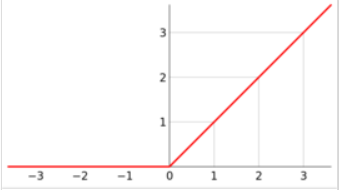
3.关于输出层的激活函数,回归问题中一般用恒等函数,分类问题中一般用softmax函数。
分类问题的输出为"根据实际分类问题得到的类别数"。
softmax函数输出的是0.0到1.0之间的实数,且输出值的总和是1。
4.正规化:把数据限定到某个范围内的处理。
预处理:对神经网络的输入数据进行某种既定的转换。
三、神经网络的学习
1.目标:找到最优参数 (eg: w、b)
最优参数:计算出的值和真实值的差别最小。
2.衡量指标/评估:损失函数。
常用损失函数:均方误差、交叉熵误差。
3.方法:梯度法
梯度:指向各点处的函数值降低的地方
4.学习率:决定在一次学习中应该学习多少,以及在多大程度上更新参数。
学习率是人为设置的,不能过大(会错失最优),不能过小(寻找费时)。
5.解决问题时需要三套数据:一套training,一套test,一套用来计算超参得到最优参数。
四、误差反向传播法:
1.核心词:规则
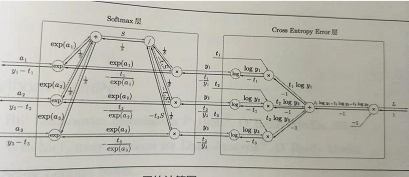
2.通关boss:Softmax-with-Loss层的计算图:
五、与学习相关的技巧
1.找最优参数的方法:SGD方法、Momentum方法、AdaGrad方法、Adam方法。
其中Adam方法是将Momentum和AddaGrad融合在一起。
不存在能在所有问题中都表现良好的方法。(但通过各个方法的图像可看出AdaGrad较为稳定)
2.权重初值的设置十分重要,设置不好会造成:梯度消失、表现力受限。
3.初始值:He初始值、Xavier初始值。
4.“training时好,test时差”——发生了过拟合。
过拟合原因:(1)模型拥有大量参数、表现力强。(2)训练数据少。
5.权值衰减:一种以减小权重参数的值为目的进行学习的方法。通过减小权重参数的值来抑制过拟合的发生。
在学习的过程中对大的权重进行惩罚。
6.Batch Norm:(1)加速学习。(2)不那么依赖初始值。(3)抑制过拟合。
六、卷积神经网络
1.目的:找滤波器。(学习滤波器的参数)
2.全连接层存在的问题:(1)数据的形状被"忽视"。(2)参数过多。
而卷积层可保持形状不变,可局部感知特征。
3.对原图卷积一次得到一个特征。
4.滤波器越多,提取特征图像越多。
5.计算公式:
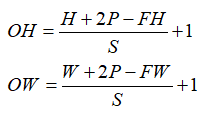
6.输入为多通道,滤波器也必须为多通道。
7.三维的变化:

8.一般从边缘开始,因为边缘的差异性较大,比较容易比对。