文章目录
前言
链表也是线性表的一种,前面我们已经学习顺序表,今天就来看看线性表的另一种——链表。
概念及结构
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。形象图大概就是:
功能的解析及实现
1.链表的创建
大家从上面的图可以看到,每一个结点包含两个元素,一个当前结点的值,另一个是下一个元素的地址,这里我们称它为一个是数据域data,另一个是指针域next。
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
2.开辟新结点
链表一开始是为空的,所以在正式使用之前要先开辟新的结点来存放我们的数据。
SLTNode* BuySListNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
printf("开辟失败\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
3.打印链表
既然创建完成了,那我们就可以打印出来看是否存储数据成功。
void SListPrint(SLTNode* phead)
{
while (phead != NULL)
{
printf("%d ", phead->data);
phead = phead->next;
}
printf("\n");
}
打印也很简单,只要当前地址所指向的空间不为空,也就意味着存放了数据,那么直接进行打印就可以了。
4.尾插
在最后一个结点后面新加入一个元素。
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySListNode(x);
if (*pphead == NULL)//如果链表为空,直接将新结点赋给第一个位置
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;
while (tail->next != NULL) //找到尾结点
{
tail = tail->next;
}
tail->next = newnode;
}
}
尾插我们只需要找到next域为NULL的结点,然后直接将新结点的地址赋给原来最后一个元素的next域就可以连接上了,形象的表示就是将原最后一个元素的next域也就是NULL改为了新结点的地址。
但是还有一种情况就是如果链表一开始为空的话,我们进行查找的时候,就会访问空指针的next域,既然都是空指针了,还怎么访问它的next域呢?(这里其实就是野指针问题,不懂的也没关系)因此这种情况就需要单独拿出来讨论,也很简单,只需要判断一下传进来的地址是不是NULL,是的话直接赋新结点的地址就好了,不是的话就找尾结点就好了。
5.头插
在链表开头插入一个元素。
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySListNode(x); //当链表为空的时候,一样可以完美解决问题,不需要分开讨论
newnode->next = *pphead;
*pphead = newnode;
}
加入一个新结点的方法都一样,都是将后一个结点的地址给了新结点的next域,再将新结点的地址给了前一个结点的next域,大概就是这样:
6.尾删
删除最后一个结点。
void SListPopBack(SLTNode** pphead)
{
if (*pphead == NULL)//为空
{
return;
}
if ((*pphead)->next == NULL)//仅剩一个结点
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* tail = *pphead;
SLTNode* prenode = *pphead;
while (tail->next != NULL)
{
prenode = tail;
tail = tail->next;
}
free(tail);
tail = NULL; //当仅剩一个结点的时候,tail和prenode指向同一个地方,一旦free(tail),prenode就指向了一块被释放的空间,造成野指针的使用问题
prenode->next = NULL;//因此要把仅剩一个结点的情况单独写出来
}
}
看过前面的顺序表我们应该知道,在删除一个元素的时候应该判断一下链表内是否为空,如果是的话直接返回就好了,不进行删除操作。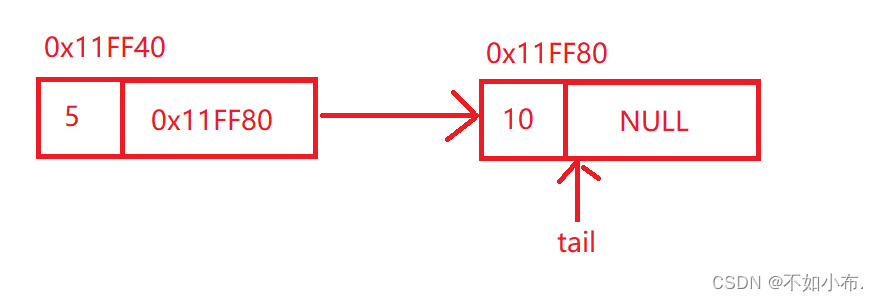 但是看图,我们会发现在找到尾结点的同时,我们失去了前一个结点的地址,这样就没有办法将前一个结点的next域置为NULL了,因此我们在找尾结点的同时,还需要再定义一个prenode指针来保存尾结点的前一个结点。在每次tail->next不等于空的时候,就将prenode指向tail,tail指向下一个结点,如此反复,那么tail最终指向的就是尾结点,而prenode指向的就是尾结点的前一个结点。
但是看图,我们会发现在找到尾结点的同时,我们失去了前一个结点的地址,这样就没有办法将前一个结点的next域置为NULL了,因此我们在找尾结点的同时,还需要再定义一个prenode指针来保存尾结点的前一个结点。在每次tail->next不等于空的时候,就将prenode指向tail,tail指向下一个结点,如此反复,那么tail最终指向的就是尾结点,而prenode指向的就是尾结点的前一个结点。
但是我们运行程序的时候发现如果链表中只有一个结点的时候程序会报错,这又是为什么呢?经过调试程序我们就会发现问题,这里我们直接看代码:
SLTNode* tail = *pphead;
SLTNode* prenode = *pphead;
free(tail);
tail = NULL;
prenode->next = NULL;
当仅剩一个结点,tail和prenode指向的是同一个结点,当free(tail)后,意味着这一块空间已经被释放不能再使用了,但是此时prenode还是指向这块已经被释放的空间,并且还对已释放空间进行了操作(prenode->next = NULL),这就又会造成野指针的使用问题,造成非法访问,所以在仅剩一个结点时,要单独拿出来讨论。
7.头删
删除第一个结点。
void SListPopFront(SLTNode** pphead)
{
if (*pphead == NULL)//链表为空的时候直接结束
{
return;
}
SLTNode* prenode = *pphead;
*pphead = (*pphead)->next;//仅剩一个结点的时候与正常情况相同,无需讨论
free(prenode);
prenode = NULL;
}
如果链表为空,直接返回。如果不为空先将第一个结点的地址保存下来,再将第二个结点的地址赋给头节点,再释放空间就可以了。
8.查找
查找元素的位置,存在就返回它的地址,不存在返回NULL。
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
while (phead)
{
if (phead->data == x)
{
return phead;
}
else
{
phead = phead->next;
}
return NULL;
}
从头节点依次遍历就可以了,一直到查到所需元素或者尾结点结束。
9.在pos位置插入
9.1在pos位置后插入
一般都是先进性查找,通过返回的地址进行插入,分为pos前插入和pos后插入,这里先说pos后插入。
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
SLTNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
和头插差不多,一个是在开头插入,一个是在pos位置插入,这个图可以形象的解释:
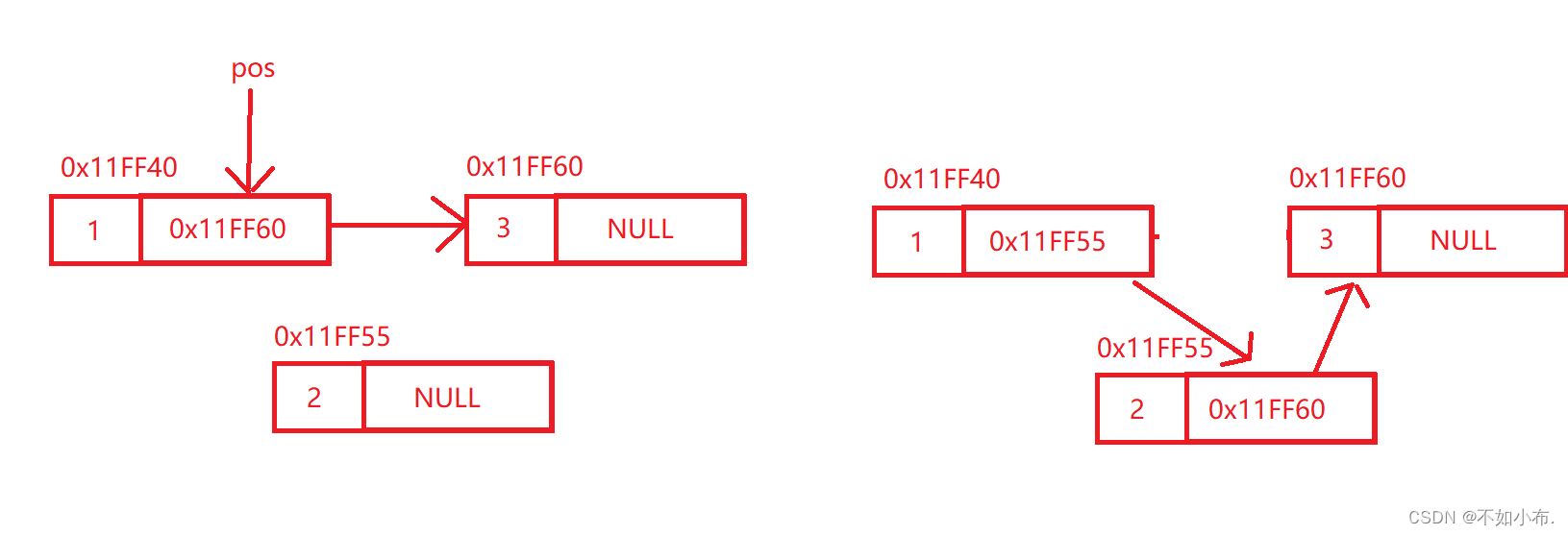
9.2在pos位置前插入
在pos前面的位置插入元素。
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
SLTNode* newnode = BuySListNode(x);
if (pos == *pphead)
{
*pphead = newnode;
}
else
{
SLTNode* pospre = *pphead;
while (pospre->next != pos) //找到pos的前一个结点
{
pospre = pospre->next;
}
newnode->next = pospre->next; //pospre->next也可以换成pos
pospre->next = newnode;
}
}
因为是在前面插入,所以我们在找到pos结点的同时还需要找到pos位置前一个的结点,==可以直接判断一个结点的next域是不是pos位置的指针就可以了。==而如果链表为空,pospre->next就会造成非法访问(野指针问题),所以要单独列出来讨论。
9.3在pos前插入和在pos后插入的区别
其实从代码量上就可以看出来,在pos后插入更方便一些,真实原因是可以直接在pos位置后插入,而pos位置前插入还需要先遍历找到pos位置前的结点,时间复杂度更高,因此在平常使用时一般用前者。
10.删除pos位置的值
10.1删除pos位置之后的值
删除pos位置后面的结点。
void SListEraseAfter(SLTNode* pos)
{
assert(pos->next != NULL);
SLTNode* next = pos->next; //保存pos下一个结点的地址
pos->next = pos->next->next;
free(next);
next = NULL;
}
首先需要判断pos位置的next域是否为空,因为删除的是pos位置的下一个结点,如果为空的话就不进行删除。然后就是常规操作,如图:
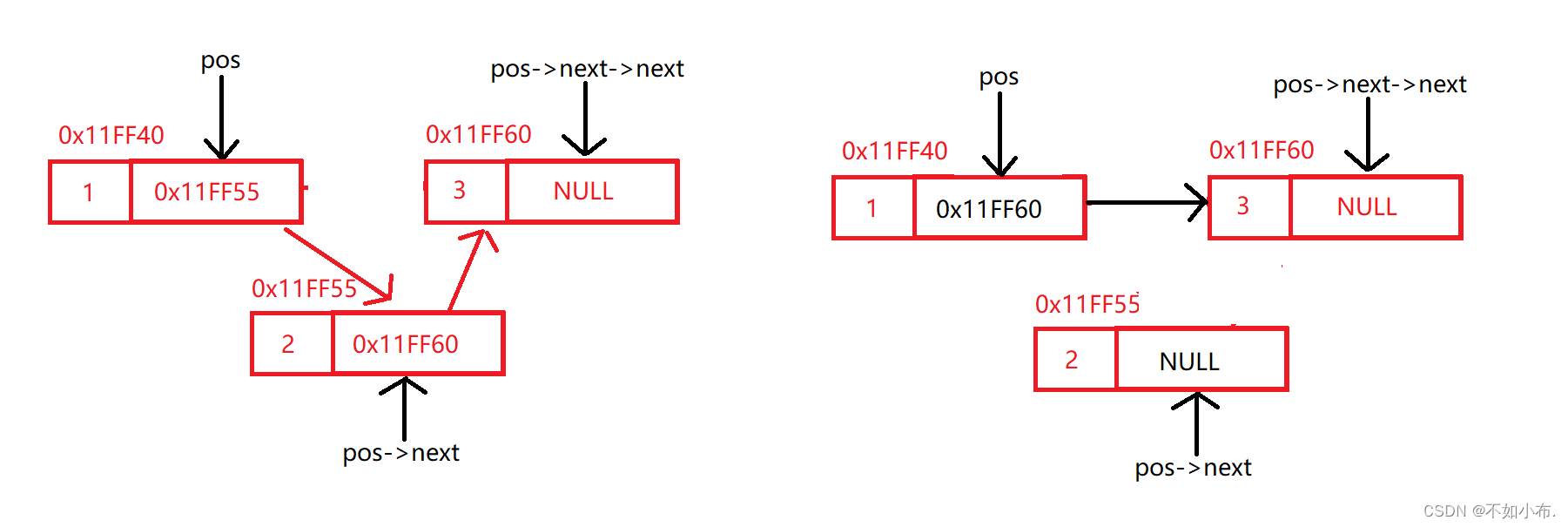
10.2删除pos位置的值
删除pos位置的结点。
void SListErase(SLTNode** pphead, SLTNode* pos)
{
if (pos == *pphead)
{
SListPopFront(pphead);//如果删除位置是第一个结点,直接调用头删就可以了
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)//找到pos前一个位置的结点
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
如果需要删除pos位置的结点的话,那么我们必须知道pos前一个位置的结点地址,以便于与pos位置后一个结点相连接。与上面的10.2一样,只不过换成了prev,pos,pos->next,上面的是pos,pos->next,pos->next->next。
11.销毁
动态开辟的空间在不使用时都需要进行销毁,以防出现内存泄漏。
SListDestory(SLTNode** pphead)
{
SLTNode* cur = *pphead;
while (cur != NULL)
{
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
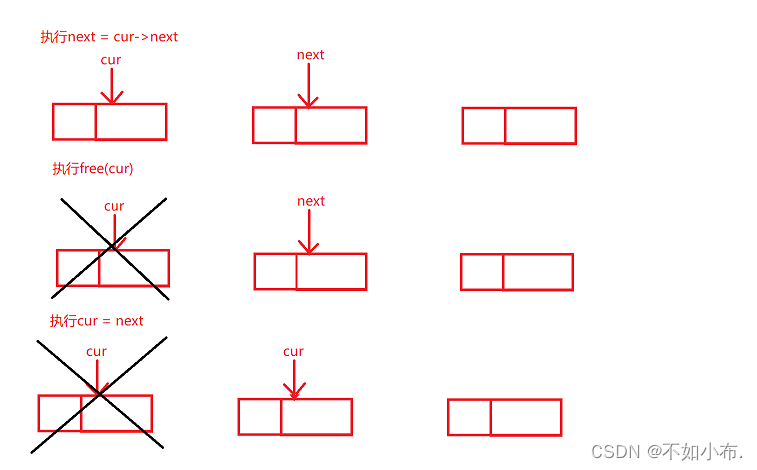
因为每一个结点都保存着下一个结点的地址,如果销毁了就找不到后面的结点了,所以在每次销毁一个结点之前我们都需要保存下一个结点的地址。如图一直反复操作即可:
总结
链表就先告一段落力,自我感觉写的还不错,嘿嘿,如果发现文章哪里有问题可以在评论区提出来或者私信我嗷。接下来我会继续学习双向链表,它可以很好的解决单链表很难向前查找的问题,更详细的内容就放在下一篇啦,那么本期就到此结束,让我们下期再见啦!!
之前看到几句话感觉很好,就想记录下来,大家也可以看一看嗷:心如花木,向阳而生,愿先生心境——四季如春。希望大家在遇到困难时可以砥砺前行,少些抱怨,多些努力,一起进步呀!!!