环境:oracle 11g
在sqlplus中开启:
set linesize 500
set autotrace traceonly
set timing on
这里用Substr和 'xxx%'的查询效率做测试
drop table t purge;
create table t as
select * from dba_objects;
--实验1:返回多数据
--预计3313条记录
--加普通索引
create index t_object_type_idn on t(object_type);
select * from t where t.object_type like 'TAB%';
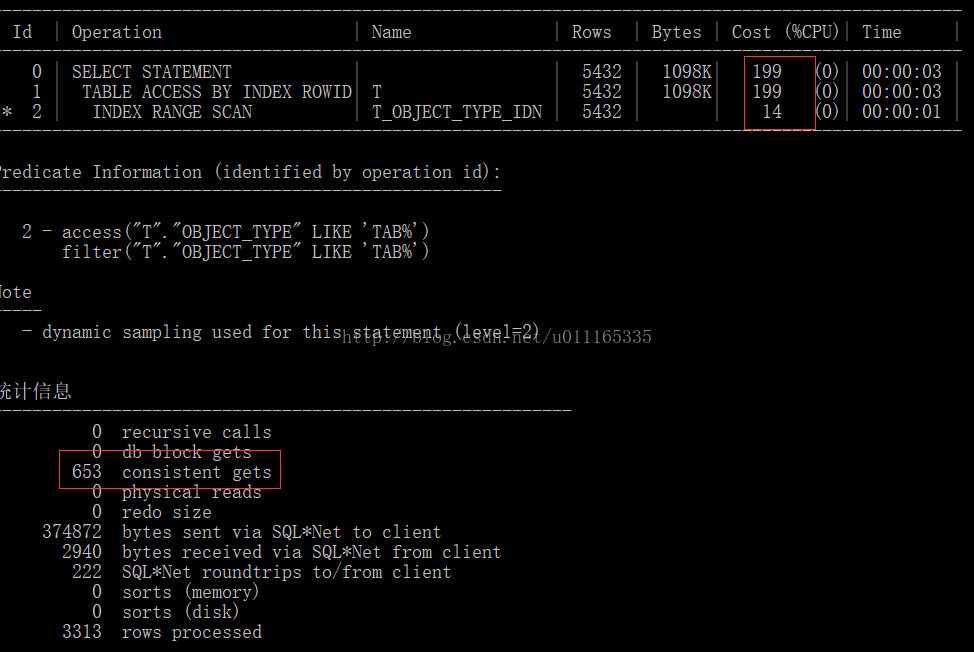
--加函数索引
drop index t_object_type_idn;
create index t_object_type_idn_fun on t(substr(t.object_type,1,3));
select * from t where substr(t.object_type,1,3)='TAB';
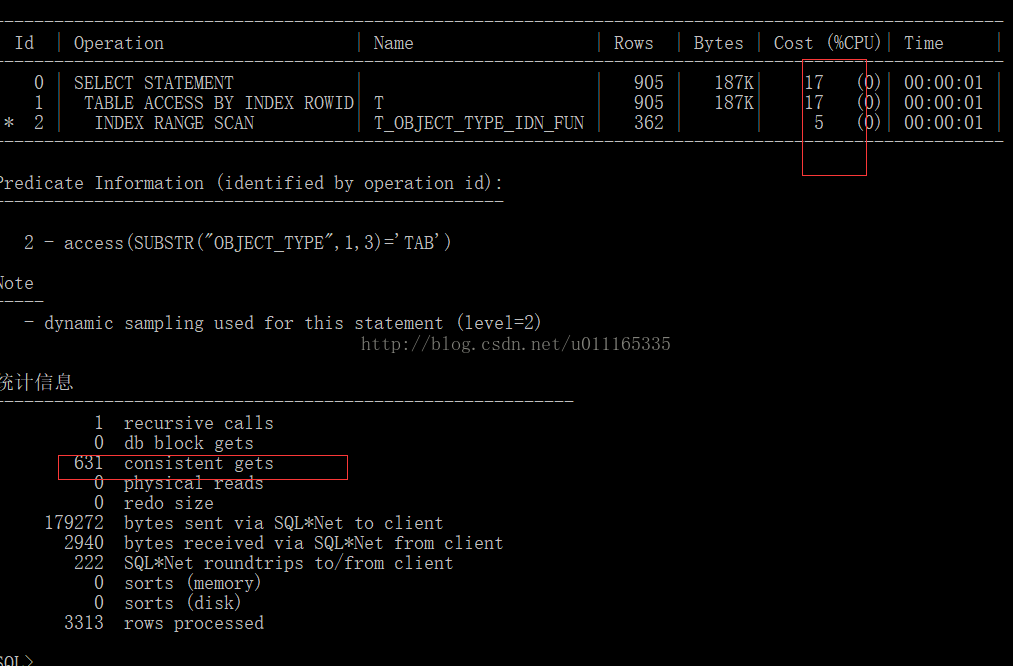
发现:代价:函数索引小于普通索引
实验2:返回少数据100
drop table t purge;
create table t as
select * from dba_objects;
update t set t.object_type='XXXAAA' where rownum<=100;
--加普通索引
create index t_object_type_idn on t(object_type);
select * from t where t.object_type like 'XXX%';
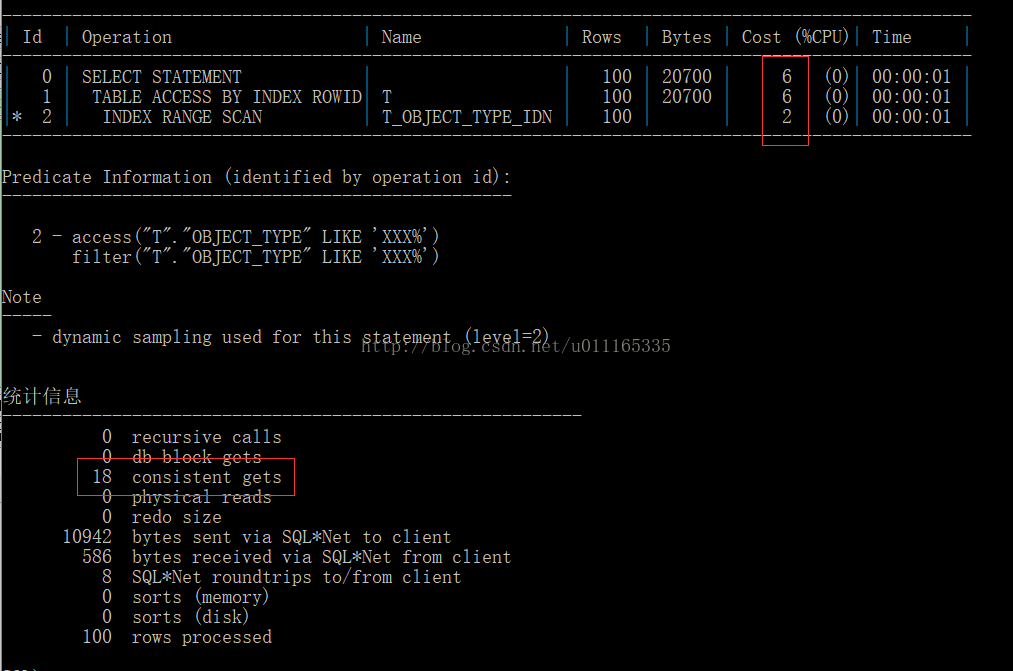
--加函数索引
drop index t_object_type_idn;
create index t_object_type_idn_fun on t(substr(object_type,1,3));
select * from t where substr(t.object_type,1,3)='XXX';
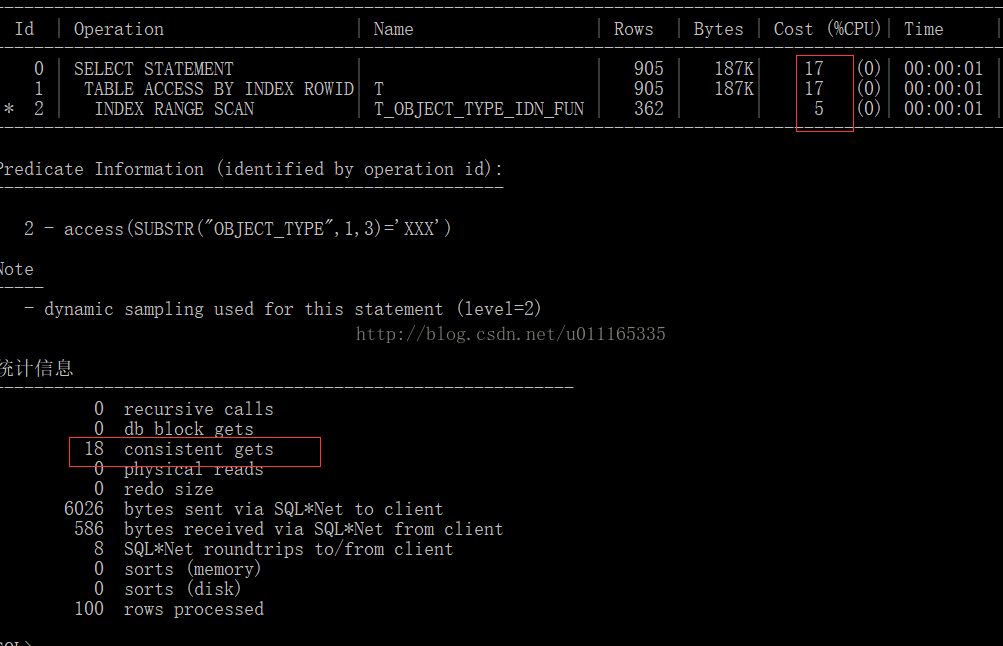
发现:代价:函数索引大于普通索引
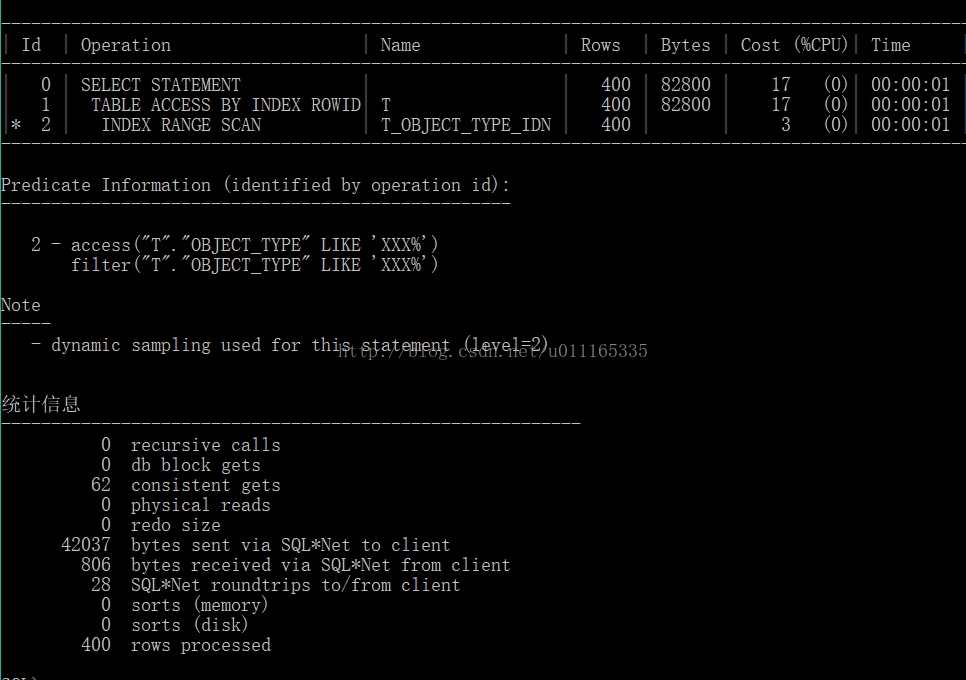
实验3:找到函数索引与普通索引性能差不多时的记录数;400
drop table t purge;
create table t as
select * from dba_objects;
update t set t.object_type='XXXAAA' where rownum<=400;
--加普通索引
create index t_object_type_idn on t(object_type);
select * from t where t.object_type like 'XXX%';
--加函数索引
drop index t_object_type_idn;
create index t_object_type_idn_fun on t(substr(object_type,1,3));
select * from t where substr(t.object_type,1,3)='XXX';
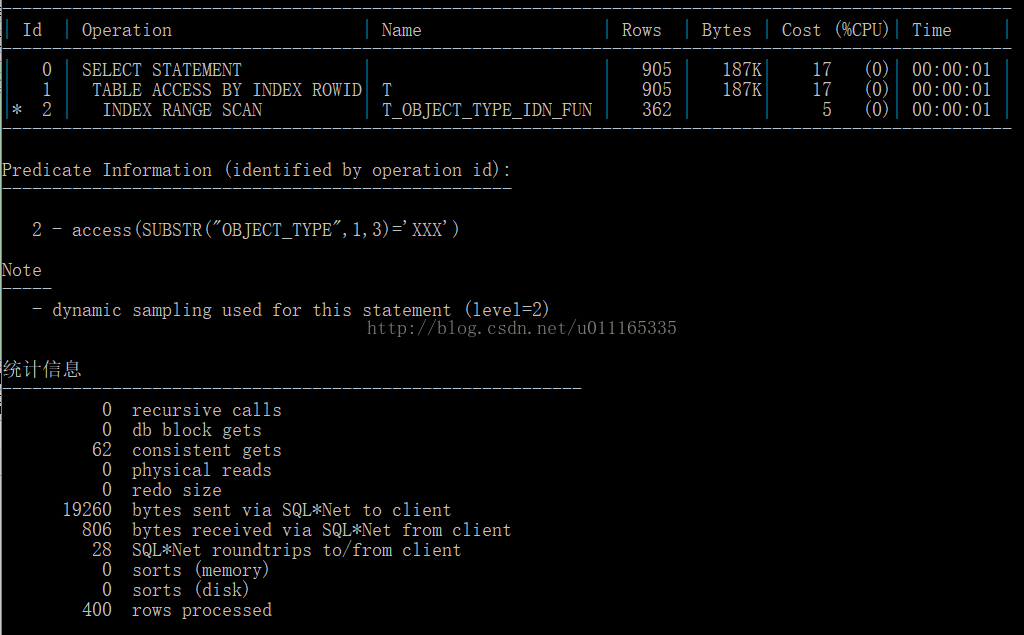
小结:发现平衡点在400左右;
当查询的结果数量小于400时,普通索引的性能高于函数索引;
当查询的结果数量大于400时,函数索引性能高于普通索引;
这里仅使用了dba_objectsz作为测试,实际的不同表临界值可能不一样;