简介:
Prometheus是一个开源的系统监控和告警系统,由Google的BorgMon监控系统发展而来。它主要用于监控和度量各种时间序列数据,比如系统性能、网络延迟、应用程序错误等。Prometheus通过采集监控数据并存储在时间序列数据库中,然后使用PromQL查询语言进行数据分析和可视化。
以下是Prometheus基本使用的一些技术:
- 安装和配置:了解如何安装和配置Prometheus,包括Prometheus Server、Exporters和Pushgateway等组件。
- 数据采集:学习如何使用Prometheus采集各种监控数据,包括系统性能、网络延迟、应用程序错误等。
- 数据存储:了解Prometheus如何将采集的监控数据存储在时间序列数据库中,以及如何使用本地磁盘、远程存储等不同的存储后端。
- 数据查询和分析:学习如何使用PromQL查询语言对监控数据进行查询和分析,以及如何通过可视化工具进行数据展示。
- 告警规则:学习如何创建和管理告警规则,以及如何将告警发送给不同的接收器,比如电子邮件、Slack、PagerDuty等。
- 数据可视化:了解如何使用Prometheus提供的仪表盘界面展示监控数据和告警状态,以及如何通过拖放和自定义配置来创建自己的仪表盘。
- 服务发现:学习如何使用各种服务发现机制,比如Kubernetes、EC2、GCE等,以自动发现和监控服务的运行状态。
- 安全和权限控制:了解Prometheus如何提供安全和权限控制的机制,如身份验证、授权等,以确保数据的访问安全。
基本使用以及认识配置:
安装和配置:了解如何安装和配置Prometheus,包括Prometheus Server、Exporters和Pushgateway等组件。
Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取、存储以及查询。
首先,Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。这意味着Prometheus Server可以根据预设的规则发现并监控各种服务和目标,无论是静态配置的目标还是动态发现的目标。
其次,Prometheus Server需要对采集到的数据进行存储。Prometheus Server本身就是一个时序数据库,它将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。这种存储方式使得Prometheus Server可以有效地保存大量的时间序列数据,并且可以在后续进行快速的数据查询和分析。
最后,Prometheus Server提供了自定义的PromQL语言,用户可以使用PromQL实现对数据的查询以及分析。同时,Prometheus Server还提供了HTTP API,用户可以使用这些API通过编程方式查询数据。另外,Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,从而实现监控数据的共享和统一管理。
总之,Prometheus Server是Prometheus生态圈中的核心组件,它负责采集、存储和查询监控数据,为用户提供了一个全面和实时的监控解决方案
Exporters
Exporters是Prometheus中的一个组件,负责将特定应用程序或服务的监控数据暴露给Prometheus。Exporters可以将应用程序的监控数据转换为Prometheus能够识别的格式,并通过HTTP或其他方式将数据发送给Prometheus。
Exporters的主要作用是扩展Prometheus的监控能力,使其能够监控到更多类型的应用程序和服务。由于不同类型的应用程序和服务的监控数据格式可能不同,因此需要不同的Exporters来实现对它们的监控。
Prometheus的生态系统提供了许多常见的Exporters,比如Node Exporter用于监控系统性能,Redis Exporter用于监控Redis数据库,MySQL Exporter用于监控MySQL数据库等。用户可以根据需要选择合适的Exporters来扩展Prometheus的监控能力。
除了使用现有的Exporters,用户还可以根据需要自定义自己的Exporters。自定义的Exporters可以根据应用程序的特定需求来实现对监控数据的采集和转换。
总之,Exporters是Prometheus中非常重要的组件,它们扩展了Prometheus的监控能力,使其能够监控更多类型的应用程序和服务。用户可以根据需要选择使用现有的Exporters,或者自定义自己的Exporters来实现对特定应用程序的监控。
本专栏中会更新部署Exporters的方式方法。
Pushgateway
Pushgateway是Prometheus的一种组件,用于接收来自短期作业的指标数据。
由于Prometheus主要通过pull模式获取监控数据,但是某些短时作业可能不支持轮询,或者因为网络原因无法被Prometheus直接拉取数据,这时就可以使用Pushgateway。用户可以通过编写自定义的脚本将需要监控的数据发送给Pushgateway,然后Pushgateway再将数据推送给对应的Prometheus服务。
Pushgateway可以单独运行在任何节点上,不需要运行在被监控的客户端。它可以将接收到的监控数据存储在本地磁盘中,并且支持自定义的时间序列存储方式。同时,Pushgateway还提供了HTTP API,用户可以使用这些API通过编程方式将数据推送到Pushgateway中。
总之,Pushgateway是Prometheus中一个重要的组件,它主要用于接收来自短期作业的指标数据,解决了Prometheus无法直接获取这些数据的问题。
了解配置文件书写:
要根据我们现实的配置文件来进行定制化的书写
要注意的是在docker中使用这些配置的时候,最好还是挂载数据卷的形式来挂载出来。
Prometheus的配置文件通常包含以下几种类型:
rule_files:规则文件,用于配置告警规则和数据聚合配置。scrape_configs:采集配置,用于指定要采集的目标列表和采集规则。static_configs:静态配置,用于指定要采集的目标列表。global:全局配置,包含全局默认配置,如抓取监控数据的间隔、抓取业务数据接口的超时时间、告警规则执行周期等。alerting:告警配置,用于配置告警发送到的Alertmanager的地址。remote_write和remote_read:远程写入和读取配置,用于将数据投递到远程地址或者从远程地址读取数据。
上述的配置文件都是在prometheus.yml中去进行书写的。
下面分别介绍一下这些配置文件的作用:
rule_files:该配置文件用于指定告警规则文件的位置。告警规则文件包含用于触发告警的条件和操作。这些规则文件可以基于聚合的数据进行定义,以便进行更复杂的告警逻辑。scrape_configs:该配置文件用于指定要采集的目标列表和采集规则。它包含每个目标的服务地址、端口、请求超时等信息,以及如何从目标中抓取数据和数据处理规则等。static_configs:该配置文件是静态配置,用于手动指定要采集的目标列表。与scrape_configs不同,这里的配置不能动态添加或删除目标,因此适用于稳定的环境。global:该配置文件包含全局默认配置,如抓取监控数据的间隔、抓取业务数据接口的超时时间、告警规则执行周期等。这些配置会影响整个Prometheus系统的运行方式。alerting:该配置文件用于指定告警发送到的Alertmanager的地址。Alertmanager是一个独立的组件,用于处理和发送告警信息。通过配置该文件,Prometheus可以将告警信息发送给Alertmanager进行处理。remote_write和remote_read:这两个配置文件用于将数据投递到远程地址或者从远程地址读取数据。这使得Prometheus可以与其他系统进行集成,实现更强大的数据分析和处理能力。例如,可以将采集到的监控数据远程写入到其他的存储系统,或者从远程地址读取数据进行进一步的分析和处理。
需要注意的是,Prometheus的配置文件通常需要在使用前进行适当的修改和调整,以满足特定环境和需求的要求。
配置文件基本案例
rule_files:
rule_files用于指定告警规则文件的位置。这些规则文件包含用于触发告警的条件和操作。例如,可以基于聚合的数据进行定义,以便进行更复杂的告警逻辑。
rule_files:
- "first_rules.yml"
- "second_rules.yml"
上述配置指定了两个规则文件,分别是"first_rules.yml"和"second_rules.yml"。Prometheus会加载这些规则文件并应用其中的告警规则。
具体案例:
当提到 rule_files 时,是指在使用某个特定系统或应用程序时,用于定义告警规则的文件。这些文件通常使用特定的格式和语法,以便根据条件触发告警。
以下是一个示例 first_rules.yml 文件的内容,其中包含一个告警规则的示例:
# first_rules.yml
rules:
- name: "Example Rule"
conditions:
- metric: "CPU Usage"
operator: "<"
threshold: 80
actions:
- email: "[email protected]"
subject: "High CPU Usage Alert"
message: "The CPU usage has exceeded the threshold of 80%."
在上述示例中,规则文件包含一个名为 "Example Rule" 的规则。该规则定义了一个条件,该条件监视 "CPU Usage" 指标,并使用 "<" 运算符检查是否小于阈值 80。如果条件满足,则执行相应的操作。在此示例中,操作包括发送电子邮件给指定的电子邮件地址,主题为 "High CPU Usage Alert",消息包含有关告警的详细信息。
请注意,具体的规则文件格式和语法可能因使用的系统或应用程序而有所不同。上述示例仅用于说明目的,并可能需要根据所使用的特定工具进行调整。
scrape_configs:
方式1使用配置书写配置文件的方式来发现服务等:
scrape_configs用于指定要采集的目标列表和采集规则。它包含每个目标的服务地址、端口、请求超时等信息,以及如何从目标中抓取数据和数据处理规则等。
scrape_configs:
- job_name: 'example_app'
scrape_interval: 5s
static_configs:
- targets: ['app1.example.com:8080', 'app2.example.com:8080']
上述配置定义了一个名为"example_app"的采集任务,使用静态配置指定了两个目标服务地址,分别为"app1.example.com:8080"和"app2.example.com:8080"。同时,设置了抓取间隔为5秒。
方式2使用额外的配置文件来发现服务:
scrape_configs:
- job_name: "服务发现"
file_sd_configs:
- files:
- /prometheus/ClientAll/*.json # 用json格式文件方式发现服务,下面的是用yaml格式文件方式,都可以
refresh_interval: 10m
- files:
- /prometheus/ClientAll/*.yaml # 用yaml格式文件方式发现服务
refresh_interval: 10m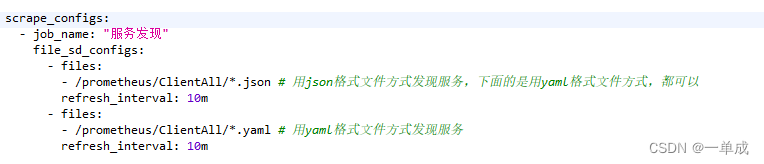
配置文件解读:
这个配置文件是一个Prometheus的配置文件片段,用于配置服务发现(Service Discovery)。服务发现是一种自动检测和跟踪系统中的服务及其关系的方法,这样Prometheus就可以自动发现并监控这些服务。
在配置文件中,scrape_configs是一个数组,其中包含一个或多个配置项。每个配置项都是一个字典,包含了一些键值对来定义一个特定的服务发现配置。
在这个例子中,有两个配置项:
job_name: "服务发现"- 这个配置项定义了监控任务的名称为"服务发现"。file_sd_configs- 这个键对应的值是一个数组,其中包含两个字典,每个字典都定义了一种不同的服务发现方式。
a. 第一个字典:
* `files` - 这个键对应的值是一个列表,其中包含一个文件路径`/prometheus/ClientAll/*.json`。这表示Prometheus将从该路径下查找所有满足正则表达式`*.json`的JSON文件。这些文件通常包含了关于服务的元数据和配置信息。
* `refresh_interval` - 这个键对应的值是一个字符串`10m`,表示每隔10分钟刷新一次服务发现配置。
* 总的来说,这个配置告诉Prometheus从指定的路径下读取JSON文件,然后根据这些文件的内容来自动发现并监控服务,并且每隔10分钟刷新一次服务发现配置。
b. 第二个字典:
* `files` - 这个键对应的值是一个列表,其中包含一个文件路径`/prometheus/ClientAll/*.yaml`。这表示Prometheus将从该路径下查找所有满足正则表达式`*.yaml`的YAML文件。这些文件通常也包含了关于服务的元数据和配置信息。
* `refresh_interval` - 这个键对应的值也是`10m`,表示每隔10分钟刷新一次服务发现配置。
* 总的来说,这个配置告诉Prometheus从指定的路径下读取YAML文件,然后根据这些文件的内容来自动发现并监控服务,并且每隔10分钟刷新一次服务发现配置。
通过这样的配置,Prometheus可以根据不同的文件格式(JSON或YAML)和服务描述信息自动发现并监控服务。这对于动态环境或需要自动扩展的服务非常有用,因为当服务发生变化时,Prometheus可以自动更新其监控配置并开始监控新的服务
static_configs:
static_configs是静态配置,用于手动指定要采集的目标列表。与scrape_configs不同,这里的配置不能动态添加或删除目标,因此适用于稳定的环境。
static_configs:
- targets: ['target1.example.com:8080']
上述配置手动指定了一个目标服务地址为"target1.example.com:8080",不能动态添加或删除目标。
global:
global包含全局默认配置,如抓取监控数据的间隔、抓取业务数据接口的超时时间、告警规则执行周期等。这些配置会影响整个Prometheus系统的运行方式。
global:
scrape_interval: 10s
evaluation_interval: 10s
上述配置设置了全局的抓取间隔为10秒,告警规则执行周期也为10秒。
alerting:
在使用这个的时候要提前准备好并安装好 alertmanager这个组件
假装有连接
alerting用于指定告警发送到的Alertmanager的地址。Alertmanager是一个独立的组件,用于处理和发送告警信息。通过配置该文件,Prometheus可以将告警信息发送给Alertmanager进行处理。
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager1.example.com:9093']
上述配置指定了告警发送到的Alertmanager地址为"alertmanager1.example.com:9093"。
看到这里有同志会出现疑惑了?
我使用的是Prometheus+Grafana那么到底我使用谁来给我发送告警呢?
我解读一下子
在这两个组合中的Grafana是一个可视化平台,是没有发送预警的能力的所以,发送告警的只能是Prometheus。
Alertmanager是一个独立的组件,用于处理和发送告警信息。在Prometheus中,Alertmanager被用于接收Prometheus发送的告警信息,然后对这些信息进行处理,例如将告警信息路由到不同的接收者、对告警进行静默或抑制等操作,最后将告警信息发送给接收者。
在配置文件中,alerting部分用于指定告警发送到的Alertmanager的地址。上述配置中的alerting: alertmanagers: - static_configs: - targets: ['alertmanager1.example.com:9093']指定了告警发送到的Alertmanager地址为"alertmanager1.example.com:9093"。
在这个配置中,alertmanagers是一个列表,其中每个元素都包含了一个static_configs部分。static_configs是一个字典,其中的targets键对应的值是一个列表,包含了Alertmanager的地址。在这个例子中,只有一个地址'alertmanager1.example.com:9093'。
通过这样的配置,Prometheus可以将告警信息发送给指定的Alertmanager进行处理。
一个使用Alertmanager这个独立组件进行发送邮件和钉钉的告警案例
Alertmanager提供了一种方式来配置接收告警信息的通知接收器(receiver)。通知接收器定义了一组与告警相关的操作,例如发送电子邮件、发送短信、将告警信息存储到某个系统等。通过配置通知接收器,您可以指定在Prometheus触发告警时应该执行的操作。
以下是一个示例Alertmanager配置文件的一部分,用于配置一个发送电子邮件的通知接收器:
global:
smtp_smarthost: 'smtp.example.com:587'
smtp_from: '[email protected]'
smtp_auth_username: 'alertmanager'
smtp_auth_password: 'password'
smtp_require_tls: false
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
from: '[email protected]'
subject: '[Alertmanager] Alerts for {
{ .接收器的名字 }}'
smtp_auth:
username: 'alertmanager'
password: 'password'
smtp_smarthost: 'smtp.example.com:587'
require_tls: false
在这个配置中,我们定义了一个名为"email"的通知接收器,并指定了一个发送电子邮件的配置。您可以根据您的需求修改这个配置,例如修改邮件的接收者、发件人、主题等。
然后,您需要在Alertmanager的配置文件中指定这个通知接收器。以下是一个示例Alertmanager配置文件的一部分:
route:
receiver: 'email'
在这个配置中,我们指定了当Alertmanager接收到告警信息时,应该将它们发送到名为"email"的通知接收器。
最后,您需要将Alertmanager的配置文件部署到Alertmanager所在的服务器上,并确保Alertmanager可以读取和加载这个配置文件。然后,当Prometheus触发告警时,Alertmanager将根据配置发送相应的邮件通知。
Alertmanager和rule_files之间存在关联
Alertmanager是一个用于管理和发送告警信息的组件,而rule_files是配置告警规则的文件。
在Prometheus中,告警规则是基于Prometheus表达式语言的表达式进行定义的,用于检测特定情况并触发告警。这些规则被存储在rule_files中。Alertmanager通过读取rule_files中的规则,对Prometheus发送的告警信息进行匹配和后续处理。
Alertmanager的配置文件可以指定多个rule_files,每个文件包含一组告警规则。通过将这些规则文件与Alertmanager的配置文件进行关联,可以实现对告警信息的处理和通知。
以下是一个示例Alertmanager配置文件中的相关部分,用于指定rule_files的路径:
global:
# rule_files字段指定了告警规则文件的路径
rule_files:
- 'rules/basic_rules.yml'
- 'rules/complex_rules.yml'
在这个配置中,我们指定了两个规则文件:basic_rules.yml和complex_rules.yml。Alertmanager将读取这两个文件中的告警规则,并根据这些规则对接收到的告警信息进行匹配和后续处理。
通过配置rule_files,可以根据您的需求定义和管理告警规则,并将这些规则与Alertmanager的配置文件进行关联,以便在Prometheus触发告警时执行相应的操作。
在这些告警中怎么去指定我要使用哪一个 rule_files
在Alertmanager的配置文件中,可以通过指定rule_files字段来选择要使用的告警规则文件。rule_files字段接受一个字符串列表,每个字符串表示一个规则文件的路径。可以在配置文件中添加或修改rule_files字段来指定要使用的规则文件。
以下是一个示例Alertmanager配置文件的部分内容,展示了如何指定要使用的规则文件:
global:
# rule_files字段指定了告警规则文件的路径
rule_files:
- 'path/to/rule_file_1.yml'
- 'path/to/rule_file_2.yml'
route:
# route字段指定了告警处理和通知的路由规则
receiver: 'ReceiverName'
在这个示例中,我们指定了两个规则文件:'path/to/rule_file_1.yml'和'path/to/rule_file_2.yml'。Alertmanager将按照在rule_files中定义的顺序读取这些规则文件。可以根据需要修改或添加更多的规则文件,只需将它们的路径添加到rule_files列表中即可。
请确保在修改Alertmanager的配置文件后,将其部署到Alertmanager所在的服务器上,并确保Alertmanager可以读取和加载这个配置文件。这样,当Prometheus触发告警时,Alertmanager将根据指定的规则文件进行匹配和处理。
告警的使用Alertmanager的案例
当使用Alertmanager发送告警时,可以通过配置rule_files来实现针对特定情况的告警规则。下面是一个示例,展示了如何使用Alertmanager和rule_files来发送告警,包括将告警信息发送到钉钉和邮件中。
首先,确保已经安装并配置了Alertmanager和Prometheus,并已经创建了用于发送钉钉和邮件的接收者。
创建规则文件:
创建一个名为rules/alerting_rules.yml的规则文件,其中包含以下内容:
groups:
- name: alerting_rules
interval: 1m
rules:
- alert: AlertName
expr: some_metric > 100
for: 1m
labels:
severity: high
annotations:
summary: High value detected
description: An alert has been triggered for the 'some_metric' metric exceeding 100.
在这个规则文件中,我们定义了一个名为AlertName的告警规则,使用了表达式some_metric > 100来检测超过100的值。告警会在指标超过100持续1分钟的情况下触发。我们为告警设置了标签severity: high和注释信息summary和description。
配置Alertmanager的接收者:
根据您的需求,配置Alertmanager的接收者以接收并处理告警信息。例如,如果您使用了钉钉作为接收者,请按照钉钉接收者的配置进行设置。如果您使用了电子邮件作为接收者,请按照电子邮件接收者的配置进行设置。确保接收者的配置正确并已启用。
以下是一个示例Alertmanager配置文件(alertmanager.yml)中的相关部分,用于指定钉钉接收者:
global:
# 其他配置项...
receivers:
- name: 'DingTalkReceiver'
dingtalk_config:
webhook_url: 'https://oapi.dingtalk.com/robot/send?access_token=your_access_token'
send_resolved: true
route:
receiver: 'DingTalkReceiver'
在这个示例中,我们创建了一个名为DingTalkReceiver的接收者,并配置了钉钉的相关信息,包括webhook URL和发送已解决的告警。我们还将该接收者指定为默认的接收者(receiver: 'DingTalkReceiver')。
配置Prometheus的告警规则:
在Prometheus中,您需要将规则文件中的告警规则导入到Prometheus中。使用以下命令将规则文件导入到Prometheus:
kubectl apply -f rules/alerting_rules.yml
-
启动Alertmanager和Prometheus:
启动Alertmanager和Prometheus服务,确保它们正在运行。您可以使用以下命令启动Alertmanager:
kubectl apply -f alertmanager.yml
-
触发告警:
为了触发告警,您可以手动触发满足告警规则的条件。在Prometheus中,您可以使用pushgateway来模拟数据并触发告警规则。例如,使用以下命令将模拟数据推送到pushgateway:
curl -X POST -H "Content-Type: application/json" --data '{"some_metric": 200}' http://<pushgateway_address>:<pushgateway_port>/metrics/job/alerting_rules/instance/prometheus-k8s-01/prometheus-k8s-01/default/alerting_rules/DingTalkReceiver/alertname/AlertName/severity/high/summary/High value detected/description/An alert has been triggered for the 'some_metric' metric exceeding 100. --header "Content-Type: application/json"
-
查看告警信息:
一旦满足告警规则的条件,P·1·1·1·1·1rometheus将发送告警信息给Alertmanager。Alertmanager将根据配置的接收者发送告警信息。在本例中,我们将通过钉钉接收告警信息。您可以在钉钉中查看收到的告警信息。
以上是一个简单的示例,展示了如何使用Alertmanager和rule_files发送告警信息到钉钉和邮件中。您可以根据实际需求进行相应的调整和配置。
本专栏中会专门出关于组件Alertmanager的讲解文章。
remote_write 和 remote_read:
remote_write和remote_read用于将数据投递到远程地址或者从远程地址读取数据。这使得Prometheus可以与其他系统进行集成,实现更强大的数据分析和处理能力。例如,可以将采集到的监控数据远程写入到其他的存储系统,或者从远程地址读取数据进行进一步的分析和处理。
remote_write:
- url: "http://remote-write-url"
write_relabel_configs:
- source_labels: ['__address__']
regex: '^localhost:(.*)$'
target_label: '__address__'
replacement: '${1}'
- url: "https://another-remote-write-url"
...
remote_read:
- url: "http://remote-read-url"
params: {'match[]': 'some_metric'}
- url: "https://another-remote-read-url"
...
上述配置使用remote_write将采集到的监控数据远程写入到两个不同的地址,使用write_relabel_configs对目标地址进行重写。同时,使用remote_read从两个不同的远程地址读取数据,并指定了匹配的指标名。
个人案例:
案例总结:
在使用的时候需要指定配置文件的路径
global:
scrape_interval: 15s # 设置抓取间隔为每15秒。
evaluation_interval: 15s # 每隔15秒评估规则。
rule_files:
- /prometheus/rules/*.yml # 这里匹配指定目录下所有的.rules文件
scrape_configs:
- job_name: "阿丹服务器" #使用配置来发现服务
static_configs:
- targets: ['ip:9090']
labels:
instance: prometheus
- job_name: "服务发现"
file_sd_configs:
- files:
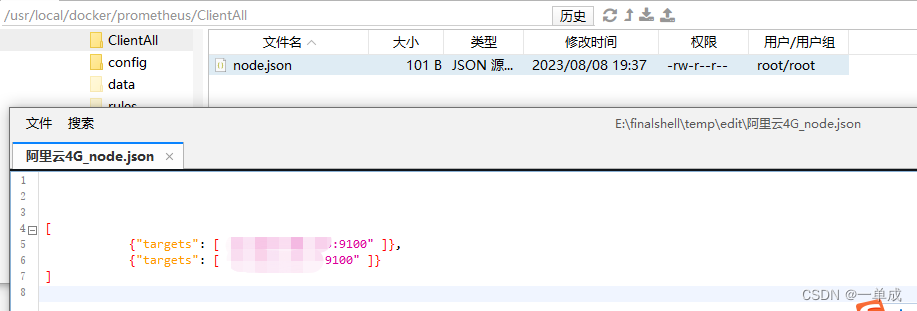
- /prometheus/ClientAll/*.json # 用json格式文件方式发现服务,下面的是用yaml格式文件方式,都可以
refresh_interval: 10m
- files:
- /prometheus/ClientAll/*.yaml # 用yaml格式文件方式发现服务
refresh_interval: 10m