1 发展历程
20世纪50年代:人工智能概念诞生
- 1956年,“人工智能”这个术语由麦卡锡在达特茅斯会议上首次提出
- 主要研究逻辑和推理,以及如何在机器上模拟人类智能
20世纪60年代:知识表达期
- 开始研究知识表达,使用谓词逻辑来表达知识
- 开发可以解题的专家系统,例如Dendral专家系统
20世纪70年代:知识库期
- 研究汇集知识到知识库,并开发程序利用知识库做推理
- 出现视觉、语音、运动控制等领域的专家系统
20世纪80年代:专家系统盛行期
- 专家系统成为人工智能的主流应用,应用于医疗、工程等领域
- 持续完善知识表达与推理系统
20世纪90年代:统计学习和深度学习兴起
- 机器学习成为主流,神经网络和深度学习理论进展显著
- 1997年,深蓝击败国际象棋世界冠军卡斯帕罗夫
21世纪:深度学习和人工智能应用爆发期
- 深度学习技术不断成熟,语音、图像、自然语言处理取得进展
- AlphaGo击败围棋世界冠军,人工智能应用进入爆发期
人工智能发展至今,已经由最初的专注推理转为数据驱动的统计学习与深度学习,并取得了巨大的进步,未来发展潜力巨大。
好的,人工智能主要可以分为以下几个分支:
2 人工智能的主要分支
2.1 机器学习(Machine Learning)
机器学习是人工智能的核心分支之一,它主要是通过算法和统计模型来实现机器对数据特征的自动学习,并对新的输入数据进行预测或决策。常见的机器学习算法有监督学习、无监督学习、半监督学习、强化学习等。
2.2 计算机视觉(Computer Vision)
计算机视觉通过相机、图像传感器和图像处理算法,来模拟人眼对物体进行识别和跟踪的功能。它可以应用于面部识别、医学影像分析、自动驾驶等领域。
2.3 自然语言处理(NLP)
自然语言处理让机器解析、理解人类的语言。它的应用有机器翻译、语音识别、信息检索等,是智能助手、chatbot的关键技术。
2.4 机器人(Robotics)
机器人技术研究如何模拟人类的行为能力,分为运算能力、感知能力、决策能力、执行能力等。它广泛应用于工业、服务、家居、军事等领域。
2.5 知识表示与推理(KR&R)
知识表示与推理关注如何用计算机来表示世界知识,并模拟人类经验进行推理。它可用于专家系统、知识管理、智能助手等应用。
以上是人工智能的主要研究方向,它们相辅相成,共同推动着人工智能技术的发展。不同方向都有自己的独特侧重点和应用领域。
3 机器学习是什么
使机器通过算法和统计模型对数据进行学习,并对新的数据做出预测或决策。
简单来说,机器学习就是让计算机自己通过数据去“学习”,而不需要人工进行明确的编程。机器学习的基本思想是构建一个可以从数据中 generalization(归纳总结)知识的系统。
机器学习主要可以分为以下三类:
-
监督学习(Supervised Learning):给机器提供大量带有正确答案(标签)的数据,使其通过这些样本数据去学习一个预测模型,然后对新数据做出预测。例如分类和回归。
-
无监督学习(Unsupervised Learning):不提供正确答案,让机器自己通过探索数据的内在结构来进行学习。例如聚类和降维。
-
强化学习(Reinforcement Learning):通过让机器与环境进行交互,提供反馈的方式让机器学习最优解。例如机器人。
机器学习算法包括支持向量机、神经网络、贝叶斯算法、集成学习等。它广泛应用于图像识别、自然语言处理、预测分析等领域。随着算法和算力的进步,机器学习正在推动人工智能的发展。
4 机器学习的工作流程
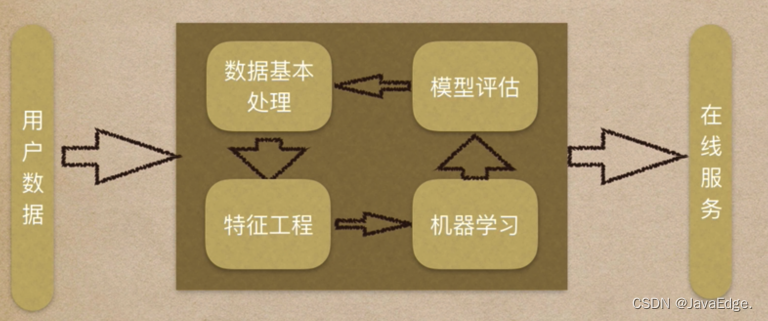
1.获取数据
2.数据基本处理
3.特征工程
4.机器学习(模型训练)
5.模型评估
结果达到要求,上线服务
没有达到要求,重新上面步骤
4.1 获取数据
在数据集中一般:
- 一行数据我们称为一个样本
- 一列数据我们成为一个特征
- 有些数据有目标值 (标签值),有些数据没有目标值(如上表中,电影类型就是这个数据集的目标值
数据类型构成
数据类型一:特征值+目标值 (目标值是连续的和离散的)
数据类型二:只有特征值,没有目标值
数据分割
机器学习一般的数据集会划分为两个部分:
-
训练数据
用于训练,构建模型
-
测试数据
在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集: 70% 80% 75%
- 测试集: 30% 20% 25%
4.2 数据基本处理
即对故据进行缺失值、去除异常值等处理。
4.3 特征工程(Feature Engineering)
使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
意义:会直接影响机器学习的效果。
意义
吴恩达说:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
内容
特征提取:将任意数据 (如文本或图像) 转换为可用于机器学习的数字特征
特征预处理:通过一些转换函数,将特征数据转换成更加适合算法模型的特征数据过程
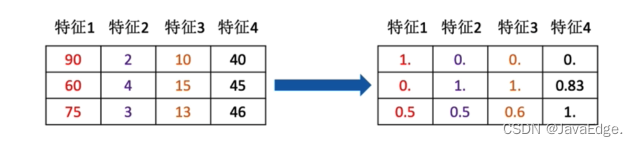
特征降维:在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
