集合相关的模块都在这里了……提起Python应该没有不知道这个模块的吧,它为开发者提供了一系列敏捷、实用的类和方法——有的是为了对集合进行相关操作,有的本身就是集合
概述:collections模块有哪些东西
使用__file__属性用来看看source code的位置
>>> import collections
>>> collections.__file__
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/collections/__init__.py'打开idle并导入collections模块,看看都有哪些有趣的东西

一看还不少……其中collections.abc(没错,是collections的一个子模块)模块是在py3中被新引进的(我们将在本文最后对其做简单介绍),然后比较常用的有namedtuple、deque、defaultdict、OrderedDict、Counter
namedtuple(具名元组)
看名字就知道首先namedtuple是一个tuple,其次它……有名字 :-)
namedtuple是一个函数,作用是创建命名元组(废话!)——也就是创建一个只有类名和属性却不包括方法的简单类(按照官方的说法,是一个tuple-like的对象
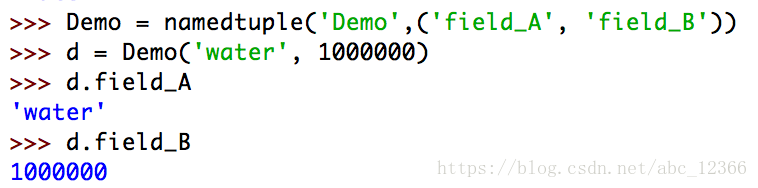
collections.namedtuple(typename, field_names, *, verbose=False, rename=False, module=None)通常我们关注前两个参数,第一个是具名元组的类名,第二个参数是它的属性名;在实际书写时既可以把多个属性放在一个字符串中,属性之间用空格或逗号分开,也可以把第二个参数写成一个序列(如tuple、list)形式并把多个属性分别包裹在单引号中它们之间用逗号分开;如图
>>> from collections import namedtuple
>>> Point = namedtuple('Point', 'x y')
>>> x = Point(1,2)
>>> x
Point(x=1, y=2)
>>> Person = namedtuple('Person', 'name, age')
>>> p = Person('Xiaoming', 18)
>>> p
Person(name='Xiaoming', age=18)
>>> Item = namedtuple('Item', ['name', 'price'])
>>> iphone = Item('cellphone', '4999')
>>> iphone
Item(name='cellphone', price='4999')另外,namedtuple对象是只读(read-only)的
deque(双向队列)
光看名字不知为何物,其实deque全称应该是double-ended queue,也就是双向队列的意思(学过数据结构基础的朋友应该比较熟悉
deque弥补了list插入、删除的效率问题(list类似数组结构,擅长查找
deque是一个类(虽然类名小写。。),以下是它的构造
class collections.deque([iterable[, maxlen]])接受一个可迭代对象(内置的就是str、tuple、list咯),第二个参数指定最大队列长度(maxlen)
让我们看看deque类都有那些方法
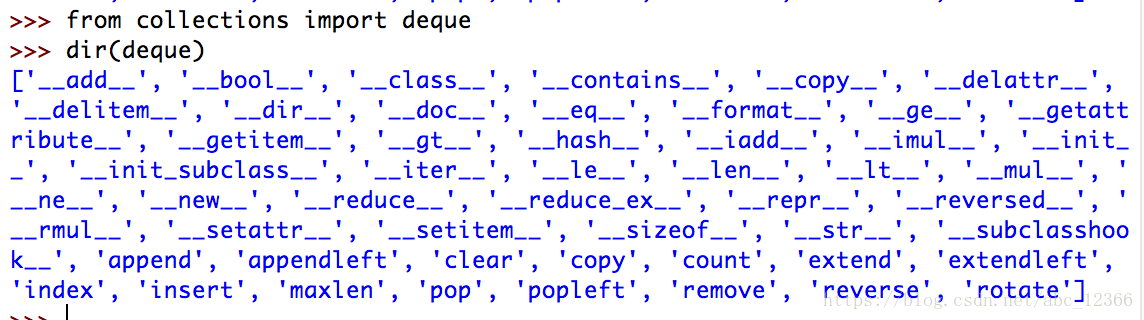
有append()、appendleft()、clear()、copy()……这些方法完全不需要死记,只需要明白一点:deque是双向队列,是list的完善,所以列表支持的操作它都支持而且还可以从两端的任意端插入新元素(对xxxleft()方法留个心眼即可)
defaultdict(默认字典)
又是一个小写的类名(我猜也许是因为考虑到init函数就把该类当函数用了
class collections.defaultdict([default_factory[, ...]])collections.defaultdict是__builins__.dict的子类,在其父类的基础上补充了魔法方法__missing__(key)
If the default_factory attribute is None, this raises a KeyError exception with the key as argument.
If default_factory is not None, it is called without arguments to provide a default value for the given key, this value is inserted in the dictionary for the key, and returned.
If calling default_factory raises an exception this exception is propagated unchanged.
This method is called by the __getitem__() method of the dict class when the requested key is not found; whatever it returns or raises is then returned or raised by __getitem__().
Note that __missing__() is not called for any operations besides __getitem__(). This means that get() will, like normal dictionaries, return None as a default rather than using default_factory.也就是说,如果访问的key不存在或访问抛出异常时(比如下面的例子,是一个KeyError)会返回指定内容(__missing__函数的作用)——defaultdict改变的是value的状态,触发条件是KeyError
下面的例子来自Python官方例程(略有改动


上面的例子中,使用defaultdict打破了key-value一一对应的固有模式,虽然还是一一对应,但是后来对应的value变成了list,属于容器类型,出发的原因是KeyError,具体事因为dict不支持append操作——于是转而调用list的append操作,效果比较明显
该技巧类似于dict_obj.setdefault(k, []).append(v)
defaultdict的另一个应用是让字典具有计数的功能(背包属性),代码见下图
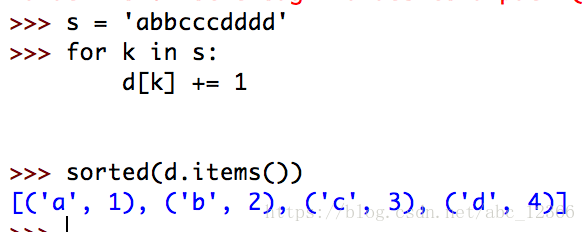
如果是使用普通版本的字典{},会在第一个item的方法就raise一个KeyError,因为key是不可变的(总之,KeyError的导致是多方面的
上面两个例子只是defaultdict的广泛应用中的小小一瞥,可见defaultdict也是一个较为强大的工具;使用的关键是第一个参数的传递,即所谓的『默认工厂函数』(default_factory)
OrderedDict(有序字典)
正如其名,有序字典是有序的;它也是内置dict的子类(所以也支持一切dict拥有的操作集)
class collections.OrderedDict([items])我们知道,普通的字典dict(..)返回的对象是无序的(和插入顺序无关,这一点很容易验证

但是OrderedDict就没有这个问题,它会按照用户插入的顺序排序而不是key的排序

鉴于这样的特性,OrderedDict可以做成一个FIFO的队列(当元素超过上限时删除最先进入的元素
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print('remove:', last)
if containsKey:
del self[key]
print('set:', (key, value))
else:
print('add:', (key, value))
OrderedDict.__setitem__(self, key, value)Counter类
collections.Counter类用来计数,类似于MultiSet或Bag
class collections.Counter([iterable-or-mapping])和defaultdict、OrderedDict类一样,都是dict类的子类
源码可以在本文的超链接处点开找到
下面是一个出自《改善Python代码的91个建议》这本书的一个例子
>>> some_data = ['a', '2', 2, 4, 5, '2', 'b', 4, 7, 'a', 5, 'd', 'a', 'z']
>>> from collections import Counter
>>> print(Counter(some_data))
Counter({'a': 3, '2': 2, 4: 2, 5: 2, 2: 1, 'b': 1, 7: 1, 'd': 1, 'z': 1})你可以像上面把一个序列作为参数来构造一个Counter对象,默认下Counter对象(记住,是dict的子类)的key是待计数元素,value是对应的计数;也可以动态的使用循环对序列进行计数
下面是另一个用Counter计数的例子
>>> from collections import Counter
>>> c = Counter()
>>> for ch in 'hello world':
c[ch] += 1
>>> print(c)
Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})先是创建一个空的Counter对象,接着对其进行填充