python collections模块提供很多高性能数据结构,在很大程度上提高了代码的性能和可读性
其中包括

还有很多抽象基类的数据结构在collections.abc中
1.tuple与namedtuple
tuple即为元组,是一种不可变数据类型,可迭代对象,除了作为不可变的列表,它还可以用于没有字段名的记录。
元组其实是对数据的记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。正是这个位置信息给数据赋予了意义。我们就可以根据元组的这个性质来进行元组的拆包。
元组拆包的几个例子:



元组拆包可以应用到任何可迭代对象上,唯一的硬性要求是被可迭代对象中的元素数量必须跟这些元素的空档数一致。
元组并非绝对不可变,如其中的元素为列表或字典等可变对象,则可以修改,但元组对列表或字典等的引用是不可变的!
namedtuple为具名元组,是tuple的一个子类,它可以构建一个带字段名的元组。
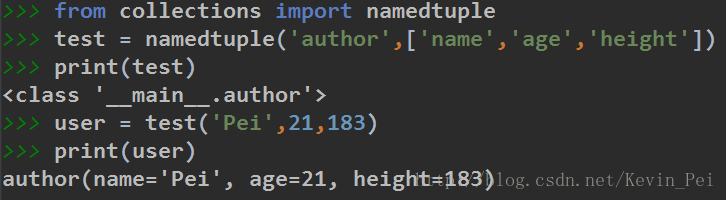
可以看出,namedtuple可以看作一个类对象来进行操作,它的好处就是它消耗的内存和元组是一样的,可以使我们的代码更美观高效。
2.defaultdict
它是一个dict子类,通过调用工厂函数来为dict的values的缺失提供值。
具体的来说就是,在实例化一个defaultdict的时候,需要给构造方法提供一个可调用对象,这个可调用对象会在__getitem__找不到的键的时候被调用,让__getitem__返回某个我们设置的默认值。
在这里我们新建这样一个字典:test_dd = defaultdict(list),如果键’newkey‘在test_dd中不存在的话,表达式test_dd[newkey]会按照以下的步骤来操作:
(1)调用list()来建立一个新列表。
(2)把这个新列表作为值,’newkey‘作为它的键,放入test_dd中。
(3)返回这个列表的引用
from collections import defaultdict
test_dd = defaultdict(list)
test_dd["Pei"]
print(test_dd)
defaultdict(<class 'list'>, {'Pei': []})
3.deque双端队列
deque就是我们数据结构中学到的双端队列,性质和用法完全相同。deque接受一个可迭代对象,具体的函数操作可在官方文档或deque的源码中看到。
>>>from collections import deque >>>L = ['Pei',21,'stu'] >>>test_deque = deque(L) >>>test_deque deque(['Pei', 21, 'stu']) >>>test_deque.pop() 'stu' >>>test_deque.popleft() 'Pei' >>>test_deque deque([21])
4.Counter
一个dict子类,用于计算可哈希对象的个数。counter接受一个可迭代对象,统计数量后按降序排列在一个dict中。
>>>from collections import Counter
>>>user_list = ['Pei','Kevin','Test','Pei','Pei','Kevin']
>>>test_Counter = Counter(user_list)
>>>test_Counter
Counter({'Pei': 3, 'Kevin': 2, 'Test': 1})
#将一个可迭代对象更新至test_Counter中
>>>test_Counter.update(['Kevin','Test'])
test_Counter
Counter({'Pei': 3, 'Kevin': 3, 'Test': 2})
#返回出现次数做多的n个元素
>>>test_Counter.most_common(2)
[('Pei', 3), ('Kevin', 3)]
5.OrderedDict
同样是dict子类,有序字典与常规字典类似,但它们记住项目插入的顺序。当对有序字典进行迭代时,项目按它们的键首次添加的顺序返回。一个OrderedDict对象可以对它进行很多顺序移位操作。
在python3中,dict创建时是默认按照插入顺序插入的,而在python2中,dict是按升序插入创建的。
6.ChainMap
该数据结构可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。
>>>from collections import ChainMap
>>>dict1 = {"a":'Pei',"b":'Kevin'}
>>>dict2 = {"b":'Test',"d":'chainmap'}
>>>test_chainmap = ChainMap(dict1,dict2)
>>>print(test_chainmap)
>>>for key,value in test_chainmap.items():
print(key,value)
ChainMap({'a': 'Pei', 'b': 'Kevin'}, {'b': 'Test', 'd': 'chainmap'})
b Kevin
d chainmap
a Pei
在这里要注意,OrderedDict只会返回第一个找到的键,在这里有两个“b”,但是只返回第一个的value
以上是python collections模块最主要的几个数据结构,熟练使用这些数据结构可以使我们的代码更简洁高效易于理解,当然还有很多其他的数据结构,可以在官方文档中自行学习。