本文从模型架构上介绍三大类神经网络算法:CNN(卷积神经网络)、RNN(循环神经网络)、Transformer(注意力机制)。除此之外还有MLP(多层感知机、全连接神经网络),因为在这三个模型架构上都会使用MLP层,所以就不把MLP单独分为一类了。
1、CNN(卷积神经网络)
卷积神经网络是LeCun于1989年提出,用Lenet卷积网络来识别信封或邮件上的手写数字。卷积神经网络是一种专门用来处理具有类似网格结构的数据的 神经网络。例如时间序列数据(可以认为是在时间轴上有规律地采样形成的一维网格)和图像数据(可以看作是二维的像素网格)。卷积网络在诸多应用领域都表现优异。“卷积神经网络” 一词表明该网络使用了 卷积(convolution)这种数学运算。卷积是一种特殊的线性运算。卷积网络是指那些至少在网络的一层中使用卷积运算来替代一般的矩阵乘法运算的神经网络。
如下是卷积运算的示意图(来自花书),步幅为一,填充为0,无偏置。
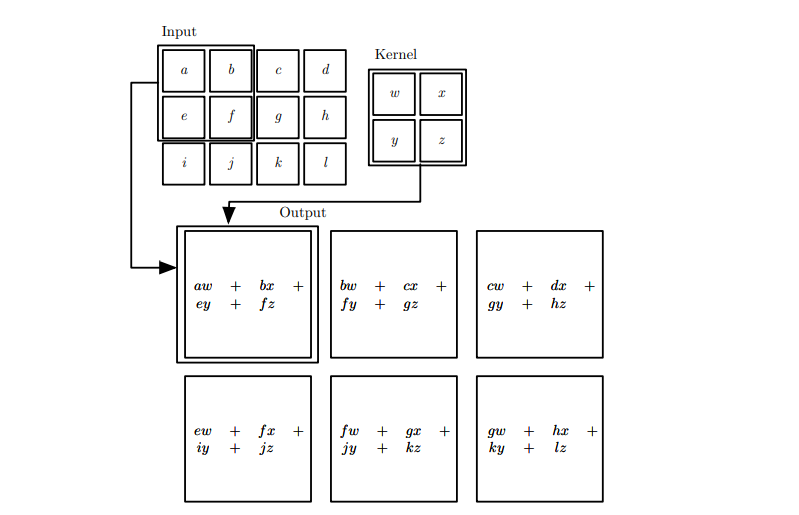
卷积运算通过三个重要的思想来帮助改进机器学习系统:
(1)稀疏交互(sparse interactions):举个例子, 当处理一张图像时,输入的图像可能包含成千上万个像素点,但是我们可以通过只占用几十到上百个像素点的核来检测一些小的有意义的特征,例如图像的边缘。
(2)参数共享(parameter sharing:在卷积神经网络中,核的每一个元素都作用在输入的每一位置上(是否考虑边界像素取决于对边界决策的设计)。卷积运算中的参数共享保证了我们只需要学习一个参数集合,而不是对于每一位置都需要学习一个单独的参数集合。
(3)等变表示(equivariant representations)。对于卷积,参数共享的特殊形式使得神经网络层具有对平移等变(equivariance)的性质。如果一个函数满足输入改变,输出也以同样的方式改变这一性质,我们就说它是等变(equivariance)的。例如在卷积操作中我们先移动图像上的物体再进行卷积得到的结果与我们先卷积在移动卷积图上的输出,这两个操作的结果是一致的。
2、RNN(循环神经网络)
循环神经网络(recurrent neural network)或 RNN (Rumelhart et al., 1986c)是一类用于处理序列数据的神经网络。就像卷积网络是专门用于处理网格化数据 X(如一个图像)的神经网络,循环神经网络是专门用于处理序列 x (1), . . . , x(τ) 的神经网络。正如卷积网络可以很容易地扩展到具有很大宽度和高度的图像,以及处理大小可变的图像,循环网络可以扩展到更长的序列(比不基于序列的特化网络长得多)。大多数循环网络也能处理可变长度的序列。
一般情况下,卷积网络用于处理图像,循环网络用于处理自然语言。如下是循环神经网络的前向传播过程,后续每个神经元都要取前一个神经元的输出作为输入的一部分。这种网络结构,可以让我们的模型对序列关系进行建模。
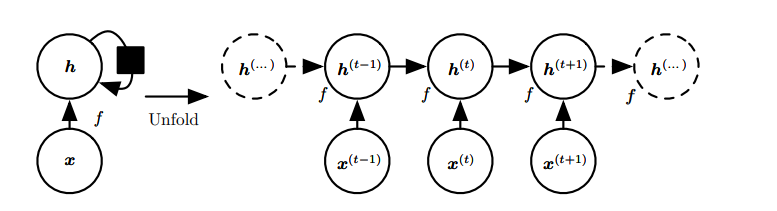
因为这种依赖关系,循环神经网络表现出两个大的问题:
(1)训练不稳定,梯度的累积容易产生梯度爆炸与梯度消失,不利于神经网络的训练。
(2)因为模型是一种串行的结构,下一个神经元的输入必须依赖于前一个的输出,所以导致了循环神经网络的处理速度慢。
3、Tansformer(注意力机制)
卷积只能通过叠加很深的层才能获得全局感受野,循环神经网络不好训练且慢。2017年《Attention is all you need》诞生了一种全新的网络架构,self-attention。使用self-attention的BERT巨大的提升了自然语言处理的精度和速度,近些年来BERT,GPT2,GPT3,基本都是基于Transformer的架构了。另外从2020年的vit开始,Transformer也开始进入图像处理领域大放异彩,如swin transformer。
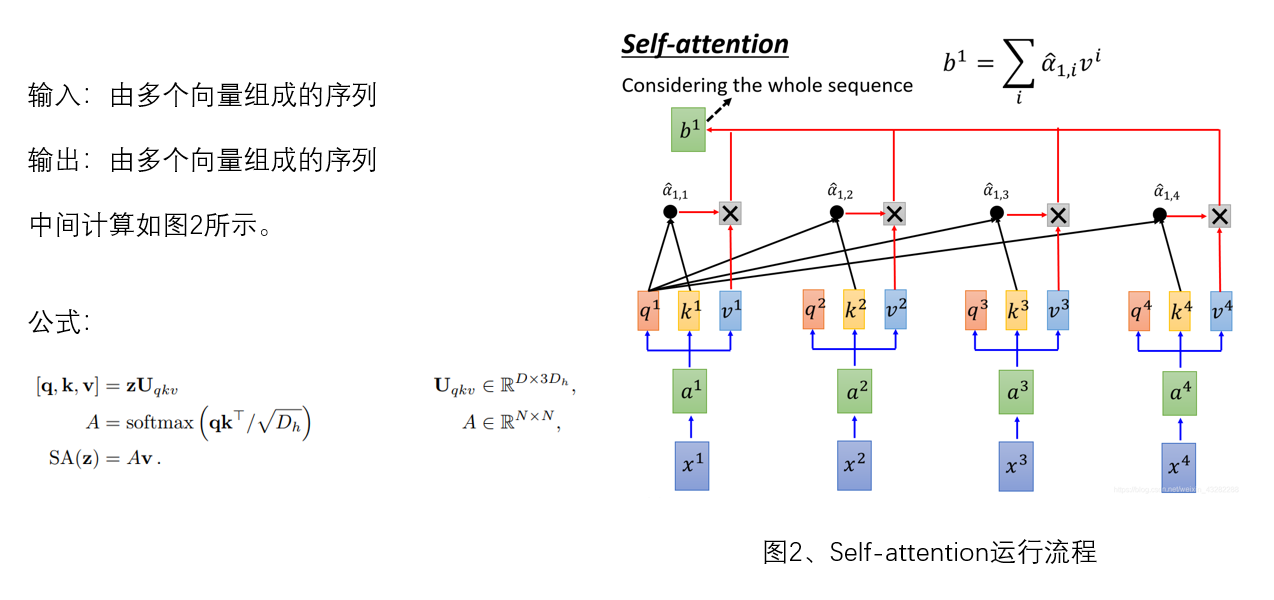
下图为self-attention的运算过程。我们可以看到这是一个可并行运算的过程,而且从一开始就在捕捉全局关系。