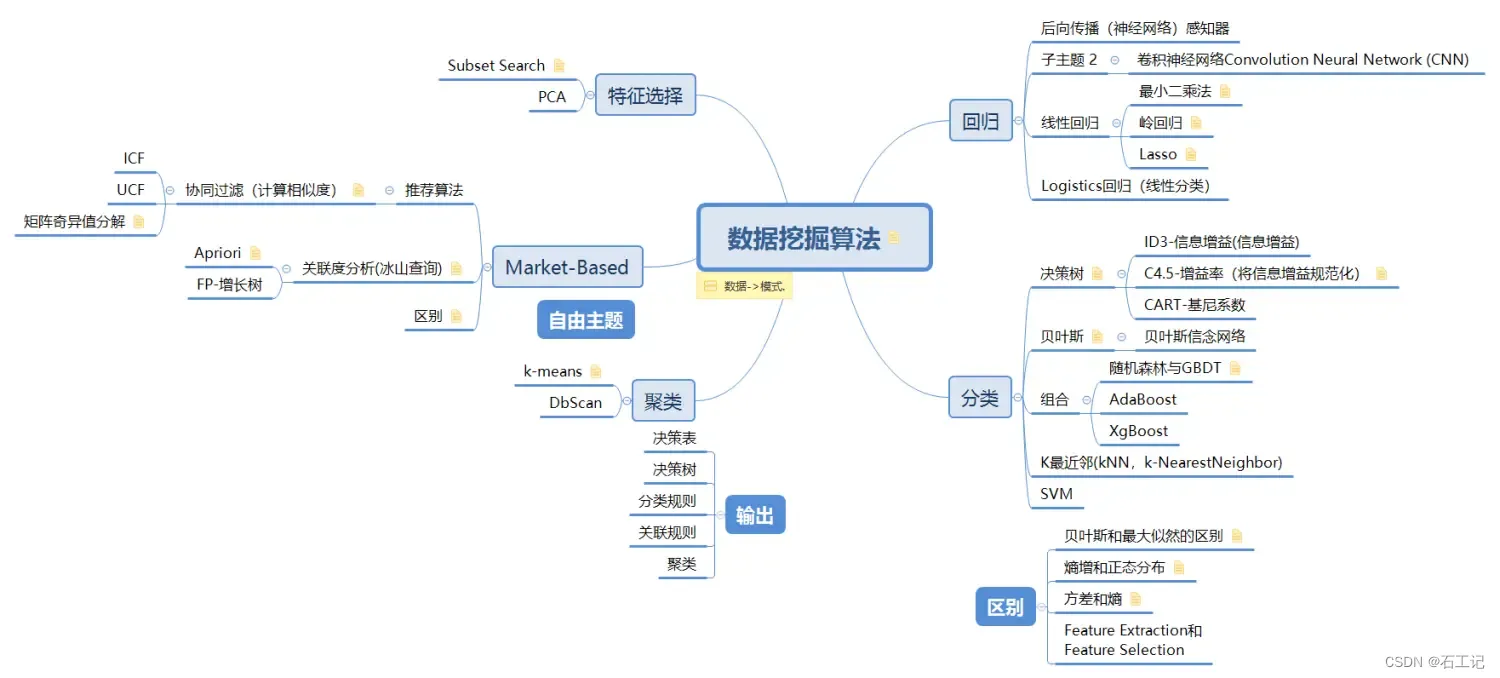
一、常用算法有哪四大类
既然我们知道数据挖掘的算法是为了寻找数据中潜在的知识,那么数据挖掘的算法通常都有哪些类型呢?如果说按照这些算法所解决的问题来进行划分,大致可以分为分类问题、聚类问题、回归问题和关联分析问题。下面我们就来详细看一下。
1.分类
春天来了,我带着儿子在公园里闲逛,看到花圃里形状各异,五颜六色的小草和花朵,儿子撒开我的手蹲在那里仔细研究起来。儿子指着其中一朵黄色的花问,“爸爸,这个是什么花?”我定睛一看,这个简单,“这是郁金香。”“这个是什么花?”我回答,“这个红色的也是郁金香。”连续问了几个之后,他指着旁边的一朵说“这个也是郁金香。”
我们接着往前走,走到一片玉兰前面,儿子又问我“这树上的是什么花呀?”我说“这是玉兰花。”
上面这个人类幼崽的学习过程就是分类算法所处理的过程。分类算法就是对已经确定好结果的数据进行学习,从而对未知的新数据进行分类的算法。在这个例子中,我为部分数据提供确定的结果,儿子通过观察它们的特征和区别来对新的花朵进行判断,从而区分出一朵花是玉兰花还是郁金香花。我们前面说,数据挖掘的算法结果是不确定的,我们怎么知道学得怎么样呢?
再看看我儿子的行为,如果他没有见过其他的花,当我们看到一棵桃树的时候,他可能会指着桃花说“这个长在树上的花是玉兰花。”这就出现了欠拟合,他只通过判断是长在地上还是长在树上就决定了花的类别,这个时候我们需要告诉他更多的特征,比如说玉兰的花瓣更宽,更长之类的。
另外一种情况,他可能会指着一朵粉色的郁金香说“这个是粉色的,这个不是郁金香。”这时候就是出现了过拟合,他把条件限制得太死,这时候我们应该给他找更多郁金香,让他明白,颜色并不是判断郁金香的主要特征。
2.聚类
我们接着往前走,这时候儿子又问我“这个是什么树叶?那个是什么树叶?”我看着这些叶子,虽然它们确实不一样,可是这也超出了我的认知,我也不知道这是什么树呀。我只好跟儿子说,我也不知道这是什么树叶,不如我们把你捡的树叶分一分,然后从每一种里拿一片出来,等我们回家查查这是什么树叶。于是我跟儿子一起蹲在那里,对着之前捡的一兜树叶挑挑拣拣。这些带锯齿边的是一堆,那些小圆片是一堆,还有这种三个尖尖的是一堆,如此种种。
与分类不同,聚类算法只需要有一些数据,但是事先并不知道数据属于什么类别,通过对这些数据的学习,希望能够通过数据的差别寻找到潜在的类别,从而把已有的数据划分成几个类别,至于说这个类别具体是什么并不清楚。
3.回归
从公园回家,还没进门我就已经闻到了饭菜的香味。我跟儿子说:“我们先吃饭吧,吃完再查树叶。”儿子却不同意,说:“我不饿,我不饿,我不想吃饭。”我媳妇这时候冲了出来,“饭都不爱吃,你都已经比别的小朋友矮了,真不知道你能长多高!”这个问题。我们或许可以使用回归算法来分析一下,当然我们首先需要有一些数据,假设孩子的身高可能跟父母身高、孩子的性别,等等有关系,那么我们获取一百组父母的身高和孩子的身高、孩子的性别、孩子吃多少饭、喝多少奶、有多少运动量等等数据,就可以构建一个线性方程,通过已有的数据把系数算出来,然后把我自己的数据输入到这个方程中就可以算出一个数来了。
回归的计算其实跟分类类似,都是预先已经有了特征数据和结果数据,只不过分类的结果是一个确定的标签,而回归的结果是一个连续型数值。很多时候,我们甚至可以在回归方法和分类方法之间进行转化。
4.关联分析
正当我还在思索孩子能长多高的时候,我媳妇又说:“他不吃饭那就冲点奶粉喝吧,奶粉快喝完了,你去某东上买点。”于是我打开了某东的 App,搜索了奶粉,正当我准备下单的时候,下面弹出了一个优惠信息:买了该奶粉的人还买了 xxx 尿不湿,组合购买可省 xx 元,然后是一个组合链接。于是我问媳妇,“尿不湿还够不够,需不需要买了,这个一起买能便宜一点。”接下来,就是我买了一桶奶粉,两包尿不湿,通过关联分析,某东成功把我本次下单的客单价从 1xx 提升到了 2xx。
关联分析是从已知数据中寻找相关关系的一类算法,比如说我们这里的奶粉和尿不湿,只是找到这样的销售搭配关系,并把它推荐给正在购物的人,就可以提升业绩了。在商业分析,推荐系统,以及用户行为分析中,经常会用到关联分析方法。
二、不同算法适合的情况
1.分类算法
分类算法对数据的要求比较高,需要一定的数据量以及事先的标注结果,通常是要根据学习过去已有的数据,对新的数据做出类别预测,比如说给新闻分类。
常见的分类算法有最近邻算法 KNN、决策树算法、朴素贝叶斯、人工神经网络、支持向量机等等。
2.聚类算法
聚类算法也是要去划分类别,但是聚类算法对数据的要求会低一些,并不需要事先标注好的结果,而是通过算法模型来判定。聚类算法通常是针对已经确定的数据集合进行划分,比如说对于用户分群,有一堆用户的基础信息和行为数据,我们不太确定这些用户到底有多少类别,又该如何划分,这时候就可以使用聚类的方式。常见的聚类算法有 k-means 聚类、DBSCAN 聚类、SOM 聚类等等。
3.回归算法
如果你有一些数据,其中要去预测的结果并不是一个标签,而是一个连续数值,可以用一个函数近似地模拟特征与结果的关系,那么就考虑使用回归算法。比如说你知道广告投入和产品销量存在着一定的关系,通常是广告投入越大销量越高,你可以用过去几年的广告费用和产品销量构建起一个函数方程,然后把明年的广告预算放进去,就可以得到一个销量的预测值。常见的回归算法有线性回归、Logistic 回归等。
4.关联分析
关联分析主要用于寻找两个项之间的关系,并给出关联规则,比如我们提到的尿不湿和奶粉的关系,关联分析可能是需要最少人工调整的方法。常见的关联分析算法有 FP-Growth 算法和 Apriori 算法。
三、一个现实问题如何转化
只是了解了不同的算法适合解决什么问题还不足以很好地完成工作。因为在实际的工作场景下,总是存在着这样或者那样的现实问题。举个例子,比如说我们的电商网站中有很多评论信息,产品经理希望能够从评论中识别到那些不好的评价,并进行深入的分析,从而根据评价来优化商品或者服务。
第一步,我们需要找到那些“不好的评价”,这可以认为是一种文本的情感识别,所谓“不好的评价”就是带有负面情绪的评价,他可能会说产品不好,或者服务不好,甚至是破口大骂。面对这样一个问题,自然而然我们想到把这个问题转化为分类问题,把评论分成正面情绪、负面情绪和无情绪三种类别。但是需要注意的是,分类需要有事先标注的结果,那这个标注必须由人来完成,如果没有人来标注怎么办呢?首先考虑自己来标注,这个方法最简单直接,但是耗时很多。如果不想自己标注,那看看在产品形态和数据层面是否有可以利用的信息?比如说有些电商网站除了写评价以外还会让用户进行打分,一般来说不好的评价往往伴随着更低的打分,那么我们可以认为这个分值是一种弱化的标注,虽然没有直接标注来得准确,但是在没有直接标注的情况下也不失为一种方案。
如果没有可以利用的标注信息怎么办呢?那这个时候可能就要考虑用聚类方法,我们是否可以先对评论朝着这三个维度进行聚类,在获得了聚类之后再对新数据进行分类呢?当然,这里可能需要对情感相关的特征进行抽取,不然可能聚类到别的维度上面去了。
在实际的工作中,像这种问题可能会经常遇到,除去优化算法本身,还有很多的事情需要去思考、去解决。我们的目的是解决业务中的问题,提升业务指标,如何更好地利用这些算法,需要因地制宜。
总结
基础的数据挖掘算法介绍,可以说数据挖掘中的算法就是在模拟人的决策过程,从而获取数据中的知识。就像我在文中写的小例子,我观察到刚出生的孩子在观察世界时的一举一动其实与这些算法有着类似的过程,或者说这些算法本身也就是从人类认知世界的过程中抽象出来的。