基于大数据市场:定价、交易、保护的研究
作者:FAN LIANG, WEI YU , DOU AN, QINGYU YANG, XINWEN FU, AND WEI ZHAO
Abstract
Big data is considered to be the key to unlocking the next great waves of growth in productivity. The amount of collected data in our world has been exploding due to a number of new applications and technologies that permeate our daily lives, including mobile and social networking applications, and Internet of Thing-based smart-world systems (smart grid, smart transportation, smart cities, and so on). With the exponential growth of data, how to efficiently utilize the data becomes a critical issue. This calls for the development of a big data market that enables efficient data trading. Via pushing data as a kind of commodity into a digital market, the data owners and consumers are able to connect with each other, sharing and further increasing the utility of data. Nonetheless, to enable such an effective market for data trading, several challenges need to be addressed, such as determining proper pricing for the data to be sold or purchased, designing a trading platform and schemes to enable the maximization of social welfare of trading participants with efficiency and privacy preservation, and protecting the traded data from being resold to maintain the value of the data. In this paper, we conduct a comprehensive survey on the lifecycle of data and data trading. To be specific, we first study a variety of data pricing models, categorize them into different groups, and conduct a comprehensive comparison of the pros and cons of these models. Then, we focus on the design of data trading platforms and schemes, supporting efficient, secure, and privacy-preserving data trading. Finally, we review digital copyright protection mechanisms, including digital copyright identifier, digital rights management, digital encryption, watermarking, and others, and outline challenges in data protection in the data trading lifecycle.
1.Intro
随着许多新技术融入我们的生活,移动设备社交应用智能系统收集了大量的数据,数据变得更有价值。大数据正在成为下一波生产力增长的动力。但数据的收集存储分析共享更新等仍然是一个挑战。为了最大限度地发挥收集到的数据的效用,一个 可行的解决方案是设计一个有效的大数据交易市场,使数据所有者和消费者(即买家)能够有效和安全地进行数据交易。
数据是一个虚拟物品,其基本特征是可变性、多样性、体量、速度、复杂性。
建立有效的数据交易市场面临的挑战:如何确定所交易的数据的市场价格;如何设计数据交易平台与方案;如何保护数据的版权。
2.大数据的基本概念
2.1.大数据的定义
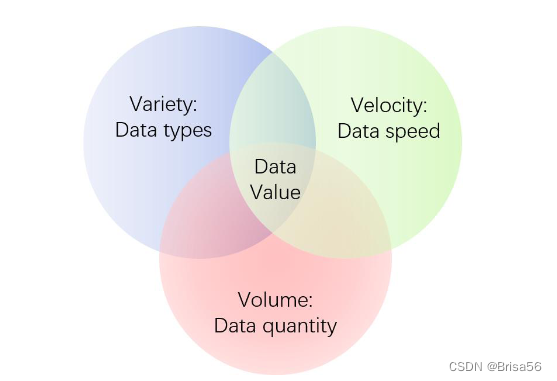
大数据的3V特性:Volume(体积,巨大的数据体量)/ Velocity(速度,高速的数据生成率)/ Variety(种类,多种多样的数据种类、来源)
现在还经常考虑第4V: Value(价值,大量数据中发挥价值的仅是其中非常小的部分)
2.2.大数据的好处和挑战
与传统数据源相比,大数据有如下优缺点:
- 全面性
大数据不仅可以捕获主要活动,还可以捕获相关数据,并提供详细信息用于将来分析。额外的信息可以提供更全面的细节来描述这个人,并帮助大数据应用进行未来的分析和提供定制服务。 - 持续性
大数据不断捕获信息。比如运动手表这类的新发明能够获得高度频繁的数据,用于深入的大数据分析。 - 多重性
有越来越多的半结构化和非结构化数据产生。这些非结构化的数据难以控制管理分析,比如音视频流等等。
2.3.大数据应用
- 大数据应用的目的
世界上各个层面的经济实体都转向使用数据密集型技术。大数据应用行业也快速增长,许多特定领域都需要大数据应用来挖掘自己收集的数据集的价值用于自身业务。必须建立有效的大数据管理和分析应用程序,以便从收集的数据中挖掘商业价值。 - 大数据应用的挑战
1)没有简单直接的方法来量化数据集的价值
2)如何设计开发用于评估价值生成过程的适当模型 (SIMTHESys , AToMe, OsMoSys , and Mobius ) - 大数据与其他技术的融合
机器学习技术,如深度学习,是利用大数据价值的可行方法。机器学习由大数据驱动,适用于快速变化的大型复杂数据集,并且可以通过运河边缘计算基础架构协助进一步改进。
合并大数据和机器学习可以帮助组织改进从自己的数据集中提取出来的业务价值,并扩展其大数据应用分析能力。
2.4.大数据里的价值
“大数据是高容量、高速度和高种类的信息资产,需要经济高效、创新的信息处理形式,以增强洞察力和决策能力。”
数据驱动的决策可以在生产力和盈利能力方面比其他决策方法产生更好的绩效。
大数据主要在如下两个方面可以为组织创造商业价值:首先是大数据用于改进和优化当前业务流程、服务和实践的能力。二是从大数据分析中开发可以开发和创新的新商业模式,产品和实践。
数据挖掘是从数据集中获取价值的常用方法。但大数据的数据挖掘面临几个挑战:数据的访问与压缩(数据挖掘算法需要将必要数据加载到主内存中,从分布式文件系统移动数据代价高昂);多种多样大数据应用(在不通领域的大数据应用有着不同的数据隐私和数据共享的方案);如何设计有效的机器学习和数据挖掘算法(及其虚席和数据挖掘算法必须处理具有大体量、分布式、复杂和动态等特征的数据)
3.大数据的生命周期
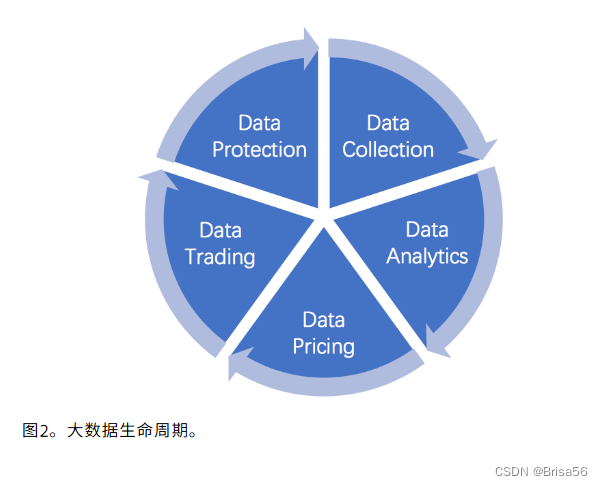
论文定义大数据的声明周期为如下5个部分:数据收集、数据分析、数据定价、数据交易、数据保护。
- 数据收集
数据收集有3个步骤:收集数据;清洁数据(数据预处理,去除噪声,数据分组);验证数据(确保数据的可用性和意义) - 数据分析
由机器学习和数据挖掘技术支持的数据分析是提取商业价值的最重要阶段。数据分析的好处:社会影响力营销、基于客户的营销、销售营销机会 - 数据定价
由于数据集具有明确的商业价值,数据定价模型和方法是在数据分析后选择的。在这个阶段数据所有者,根据数据大小,客户需求等等因素为数据集设置一个合理的价格,并将数据集推向市场。 - 数据交易
数据作为数字产品,不同于传统商品交易,需要适当的市场和交易方式。 - 数据保护
数据交易后,要保护数据的版权和数据所有者的合法权益。
4.数据定价模型
4.1.数字商品定价原则
数据可以被认为是一种在市场上买卖的数字商品。
消费者更喜欢相同价格下质量更高的商品。基于版本的策略是确定数字商品价格的一种常用方法。
数字商品的在成产成本几乎为0。数字商品商业价格衡量的因素是开发成本,搭配或分析成本以及维护成本。为了满足不同的消费者,数字商品的价格也要差异化,例如原始数据集和预处理后的数据集可以通过使用不同的精度、时间频率等打包成多个级别的产品。
4.2.数据市场结构

- 垄断结构
原始数据属于垄断者。
依据相同的原始数据集进行不同质量水平的生产数据商品,再根据数据商品的质量细节设置不同的价格点满足消费者不同层次的需求(这个叫价格歧视策略)
垄断者一般会设定一个价格作为参考,监测消费者的反应,调查消费者的偏好。根据这个参考进行价格的增减,从而能够使垄断者能细分需求模型和价格函数,将利润最大化。 - 寡头垄断结构
原始数据属于少数所有者。
数据所有者有很强的能力来控制机器学习、数据挖掘过程、市场价格。数据所有者能实现利润最大化。
寡头垄断结构严重影响消费者需求和供应商服务,缺乏竞争让市场低迷。 - 竞争结构
销售价格几近于边际成本,增强了市场透明度,为消费者带来了很多好处。
但这种结构会让业主因为竞争,降低销售价格,从而降低所有者的利益。
竞争激烈的降价将导致激烈的竞争,使得市场萎缩。
4.3.数据定价策略
成熟的定价策略将是实现利润的最大化而不是降低成本的主要因素。
-
免费数据策略
在线发布数据或在公共存储中共享数据。
交易不是免费数据的目标。
用于吸引一些犹豫购买完整数据集的潜在客户和刺激消费。 -
基于使用情况的定价策略
对数据流的使用情况和服务时间进行度量计算。
近年来,网络服务提供商会将数据使用和服务时间合并在一起,动态的改变价格。也可能会考虑高峰时间的使用情况。 -
套餐定价策略
一种增强的基于使用情况的定价策略。
一些供应商会提供固定价格的定价策略。为最大限度提高供应商的利润,他们会进行用户使用分析、高峰时间监控、网络流量控制等等。 -
统一定价策略
最简单的定价策略。
时间是唯一参数,供应商只是考虑销售每种数字商品一次。
常用于软件许可证和托管。
有利于供应商预测预期利润,指定未来计划。
对消费者而言缺乏灵活性多样性 -
两部分资费策略
套餐定价策略和统一定价策略的结合。
消费者要支付两部分费用:软件许可证固定费用、持续的服务和数据支持费用。
这种策略被网络服务提供商、移动电话运营商、软件公司等广泛使用。他们起初以固定价格销售其数字商品,对服务费更新费或超出固定套餐的数据进行二次收费。 -
免费增值策略
先免费为消费者提供基本产品或优先服务,同时也为消费者提供额外的优质服务。但完整版本的功能需要额外费用才能解锁。
通常被小公司采用.
4.5.数据定价模型
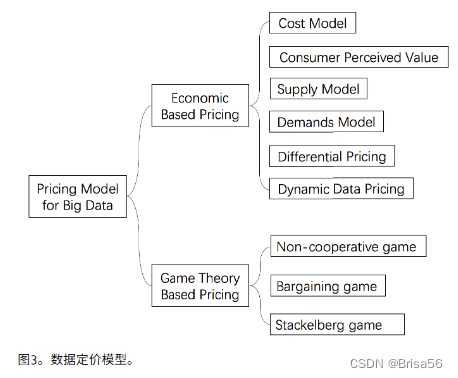
数据定价的主要因素:数据收集成本、数据分析成本、数据管理成本、消费者的需求。在上述市场结构和定价策略之后,图3将定价模型分为2大类:基于经济的定价模型;基于博弈论的定价模型。
4.5.1.数据定价的主要因素和挑战
-
多样化的数据来源
- 不同设备和相关部署成本给评估收集成本带来重大挑战
- 收集到的数据类型多样,难以分类评价
- 如何激励设备所有者的贡献以及共享收集到的数据也是额外的挑战
-
数据管理的复杂性
- 数据的管理(分析,存储,更新等)是一个挑战
- 维护大数据需要很大成本(大多大数据都存在云或边缘存储中,维护数据的可用性以及存储、保护数据都需要很高成本)
- 原始数据在可用前也要星星分析,开发高效的应用程序来分析数据集也是一个因素。
-
数据的多样性
- 供应商会处理原始数据集用于满足各种需求,如何进行不同商品的价格评估也是一个挑战。
为了鼓励传感器上传数据并为传感器所有者带来更好的利润,适当的定价模式变得更加重要。引入定价机制是鼓励与会者贡献自己的数据的一种可行方法。定价机制调整价格和支付计划,以保证参与者的足够规模,并提高数据服务,数据准确性和数据覆盖率。
4.5.2.基于经济的定价模型
它是基于经济原理的。
以下是一些数据定价的经典经济学概念:
- 成本模型
I = C(1+P)
I:期望收入、C:总成本、P:利润百分比
它考虑每个商品的总成本,并设置一个基于总成本的利润百分比。成本通常包括:固定成本(资源、设备、能源消耗等成本)、可变成本(人工、开发等成本)。
优点:简单(只用考虑内部因素)
缺点:不涉及外部因素(竞争、需求等),这对定价模式不利
- 消费者感知模型
Pv = (vp, vc, vm, vs, ve )
Pv:影响数据定价的五个主要因素
vp:基于来自消费者的反馈数据的性能,关键因素是效用(效用是消费者对购买的商品或服务的满意度的测量),
vc:可能影响消费者行为的市场环境因素,
vm:愿意购买数字商品的消费者的动机,
vs:供应商的价值,代表供应商的信用和消费者的主要反馈,
ve:经济价值,取决于消费者的需求和消费者对价格的看法
感知定价模型:消费者感知的价格由所有消费者都愿意支付的价格决定。
- 供需模型
P:商品价格;Q:商品数量
供给函数:P = a-b·Qs
需求函数:P = c-d·Qd
橙色线是供给函数,绿色线是需求函数。供应商和消费者之间的行动是平衡的条件。图上的交叉点就是供应商和消费者平衡的条件。从方程(P-a)/b=(P-c)/d可得P;从方程a-b·Qd=c-d·Qs易得Q
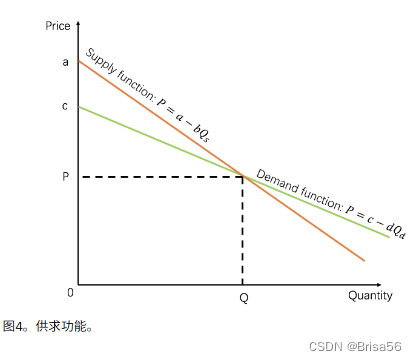
这种模式有两个特征:这是供应商和消费者的一致行动;决策过程由市场决定,消费者供应商不能改变这一过程,很好的保证了市场的公平性
-
差异定价模型
供应商提供具有不同特征的商品,并根据这些差异设置不同的价格。 -
动态数据定价模型(智能数据定价模型)
这是差异定价模型的特例。
它监控市场并评估系统是忙还是闲,根据评估对价格进行动态调整,节省供应商资源和节约消费者金钱。
实现这一目标有两种主要机制:基于时间的定价(价格随时间推移而改变,夜间通常会提供较低价格,以鼓励消费者避免高峰时间使用);基于使用情况的定价(根据使用情况改变价格,往往超过原始平面数据时实施,鼓励消费者在固定或计划窗口中完成需求,阻止消费者超过预定限制)
4.5.3.基于博弈论的的定价模型
- 非合作博弈
非合作游戏中,所有玩家必须发布定价策略且定价策略要透明.
所有参与者都假定彼此不合作
玩家是参与游戏并做出决定的个人;
回报是真正的利润和效用,代表玩家的预期结果;
合理的描述了所有玩家都希望在游戏过程中保持其最大利润的条件;
策略是玩家操作的有限活动,每个玩家的策略可以不同;
回报结果不仅会受一场比赛影响,还会受其他比赛影响
Luong and Yaïche等人,设计了一个用以评估物联网传感数据的定价模型:所有供应商都以竞争的方式出售数据。
定义(V, π)为n个玩家(卖家)游戏,vi是第i个玩家的定价策略。πi是卖方i的回报向量。
V=V1V2…Vn 是每个策略集的笛卡尔积。
v=(v1,v2,…,vn) 是n个玩家的定价策略组成的向量。
^vi=(v1, . . . , vi−1, vi+1, . . . vn)是除vi策略以外的策略组成的向量。
这三个因素的关系是玩家i使用给定的定价策略v来实现回报π
V的纳什均衡代表了一个条件,在这个条件下没有一个玩家,在其他玩家没有改变他们的定价策略的情况下,可以通过改变给定的定价策略来提高自己的利润。∀i, vi ∈ Vi : πi(v∗ i, ̄ v∗ i ) ≥ πi(vi, ̄ v∗ i ). 从等式中可以看到,纳什均衡的参与者没有动力改变他们的定价结构。
实现纳什均衡是解决问题的唯一办法。相关的纳什均衡可能有0或无数个,只有其中一个才是使用非合作博弈对数据定价的必要充分条件。
- Stacklberg博弈
一个典型的Stackelberg游戏模型:移动运营商越晚宣布定价策略,效用越好。
Haddadi and Ghasemi提出了一个定价模型,用于保护宣布了定价策略的玩家。
他们定义了两个位置:领导者、追随者。先宣布策略的玩家成为领导者,其他成为追随者。
这种模型下,可以最大限度提高所有玩家的回报,尤其是领导者的回报。
在频谱交易和资源分配中使用这种模型,可以提高物联网系统中的网络性能和稳健性。
- 讨价还价博弈
供应商和消费者需要进行谈判,达成一个协议。一个简单的数字市场中往往是销售价格的一致。
rv表示为供应商的保留价格,以确保供应商能够接受的回报利润
rc表示为愿意购买的消费者的保留价格
Pv、Pc为供应商和消费者的定价策略
对于卖方,期望利润为πv(Pv, rv),当πv*(Pv*,rv)>=πv(Pv, rv),就可以选择定价策略Pv*。
对于买方,期望利润为πc(Pc, rc),当πc*(Pc*,rc)>=πc(Pc, rc),就可以选择定价策略Pc*。
然后供应商和顾客比较定价策略Pv*、Pc*。如果Pv*>Pc*,谈判将继续。如果Pv*<=Pc*,讨价还价博弈讲义将以策略P=kPc*+(1-k)Pv*,其中0<= k <=1。最后我们得到纳什讨价还价均衡:(Pv*,Pc*)。
由于讨价还价游戏是复杂谈判条件的适当方案,因此通常用于提高数据拍卖过程的性能,网络资源拍卖和共享以及能效管理。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yJkBu4Ja-1665840362754)(images/e441d93a6c61315f6dd7a367a426c331b4b47e3828a990eea03764c1b83ec74c.png)]](https://img-blog.csdnimg.cn/5ade379f71c24041bb4a41ecfcb679b9.png)
5.大数据交易
5.1.大数据交易的主要目的
两大目的(好处):
1)数据交易过程应为数据所有者实现利润最大化
大数据是下一波生产力的基础,数据能够为公司创造巨大价值,并非所有公司都能收集要求苛刻的数据。
在提供服务,提高生产力和最大化数据价值方面,数据所有者非常愿意与他人“交换”自己的数据集。
2)满足消费者对海量数据的需求。
信息是公司发现新商机,价值和客户的关键。
数据消费者有强烈意愿从市面上购买数据,并利用数据改进服务或产品。
没有数据交易,数据保持静态,形成信息孤岛。数据交易将数据作为动态流来推动建立双赢市场,实现数据的商业价值。
5.2.大数据交易的问题
大数据交易涉及通过信息技术实现资源交易与配置。有许多问题仍未解决:如何确保多个供应商的最大利润;如何确保交易真实;如何保护供应商和消费者的隐私;如何建立一个可信赖的贸易平台。
1)多个数据所有者的数据交易
如何定量分析每个数据所有者的所有权。
同一数据的所有者们会出现竞争,很难设计数学模型来描述这些复杂需求
数据商品有维护成本,确定维护成本也很重要。
2)交易的公平性和真实性
公平性和真实性有两个主要方面:供应商和消费者之间;供应商、消费者、交易组织之间。
数字商品是虚拟商品,相关交易都是网络中进行,对于供应商消费者都是“盲目的”
Delgado-Segura等人提出建立一个具有公平协议的公平交易市场。交易过程可以随时完成或终止,确保供应商和消费者都没有损失,但平台不能辨别虚假信息,并且一次只考虑一个交易过程。
3)隐私保护
数据交易过程,要保护消费者隐私,也要保护数据商品的隐私。
版权法只注重数据所有者的合法权益,不能保护数据的隐私;水印只能作为调查的证据,从而阻止滥用;加密计算需要更大的计算资源支出。如最小化设计策略。通过在每个时间段值提供最小量的数据来降低隐私泄露的风险,并进一步提高较大数据包的价格。
基于密码学的技术常用于隐私保护。如一种隐藏设计策略,对原始来源的一部分数据进行加密和隐藏。
加密过程还可以使用不同的高效加密技术。
4)第三方交易平台
数据所有者委托第三方交易平台出售数据商品。
但平台的可信性是一个很大风险。
所有者通过加密,再将数据上传到平台,并将密钥出售给消费者。
5.3.大数据市场
5.3.1.市场平台
一个成功的数据市场,要为消费者和供应商提供最佳的购买和销售体验,也要保护数据商品和个人信息的隐私。以下是一些现有的市场机制:
a:交易查询
顾客购买数据前,需要进行查询操作,但查询操作并非免费。市场应该建立一个有效的查询系统,最大限度降低消费者的成本。
一种优化的基于学习的优化器。该方案包括解析器、优化器、执行引擎。这种方案通过设计有效算法减少中间数据的数量来减少采购过程中的查询数量。
具体来说,解析器在消费者注册数据市场时首先获取本地表信息。然后,优化器通过从本地数据表加载参考数据和数据市场信息的统计信息来优化查询。最后,将结果发送到执行引擎。
b:动态交易
现有数据市场的两个限制:通常只出售整个数据集,并且不支持任意查询;数据市场通常不支持数据的更新和维护。
Liu和Hacigümüs提出了一个动态数据市场框架来解决这个问题。在这个框架中,使用了一个在线共享计划选择算法,确保数据商品视图的维护效率,然后通过维护数据商品的视图来进行商品更新。
另外一种分布式算法,概念来自匹配博弈论,即根据需求出售数据。该方案比较了供应商和消费者制定的偏好,按消费者的需求找到一个数据商品的匹配部分进行销售。这种方案支持所有参与者自组织特性的整合到一个匹配表中,并确保匹配过程和结果动态适应消费者的需求。这种方案使消费者的平均效用增加了25-50%。
c:隐私保护
密码学是用于保护敏感信息的有效方法。
Niu等人提出了数据市场的真实性和隐私保护机制(TPDM,Truthfulness and Privacy preservation in Data Markets) 。特别是TPDM采用了具有签名(身份识别)的同态加密。它保护了隐私和数据机密性,同时改善了批量验证和数据交易过程。基于身份的签名组件在密码文本空间中处理数据。此外,来自数据所有者和消费者的所有签名都是他们的真实身份,它可以防止所有恶意供应商或对手。
5.3.2.数据拍卖
拍卖是一种经济方案,通过买卖双方的投标过程来分配商品设置价格。具有确保公平效率的能力。一些基本概念如下:
投标人:提交投标书并在市场上购买商品的人。数据市场里的数据消费者。
拍卖师:代理人,管理拍卖,制定胜利者决定,进行付款和分配。
卖方:投标和出售商品的所有者。
估价:买卖双方都对要购买或售出的商品进行估价。
结算价格:买卖双方交易的价格。
5.3.2.1.数据拍卖模型
-
单边拍卖
包括正向、反向拍卖。
正向拍卖也叫卖方侧拍卖,其中买方竞争卖方的商品。An等人提出了一个多回合假名证明正向拍卖(MFPA)机制,旨在最大限度地提高数据所有者和消费者的社会福利。为了防御虚假名称竞价攻击,数据量以 MFPA 中的捆绑大小进行交易。投标人当且仅当其投标书和要价如实提交时,才能实现最大效用。
在逆向拍卖的情况下,卖方竞相向买方出售商品。一般来说,在大数据市场中,逆向拍卖机制适合多个数据所有者倾向于将数据出售给一个数据消费者或数据收集者的情况。 -
双边拍卖
现实世界最常用的拍卖之一。
多个买家多个卖家向拍卖师提交出价和要求。收集完资料后,拍卖师根据结算价格以及款项来匹配这些投标和询问。
Cao等人提出了迭代拍卖机制,用于防止自私行为导致的地交易效率。第一步,拍卖师向消费者公布数据商品的分配、定价、拍卖机制;第二步,每个消费者计算投标价格,以实现最大化效用;第三步,拍卖师收到投标价格,并根据规则和价格公布结果;第四步,拍卖师基于先前的拍卖过程,重新调整公布新的起拍价和拍卖规则,开始全新拍卖。前三步也存在于共同的拍卖中,第四步是这种机制的独特点。
在二级移动市场中,Susanto等人,提出了一种基于McAfee的双重拍卖机制,使移动数据交易能够在异构和动态环境中进行。这种方案能实现纳什均衡和真实性。 -
封标拍卖
买主不知道其他买主的投标信息,私下向卖主投标。
封标拍卖是一次性拍卖,导致买家的非公开性竞争。
典型的例子:kth-price/VCG/McAfee拍卖:kth-price拍卖可以分为第一价格拍卖(获胜者为最高投标价格的投标人)和第二价格拍卖(也叫Vickrey拍卖,获胜者为最高投标价格的投标人,但结算价格为第二高的价格,诱导买家如实举报,保证方案的公平性)。VCG拍卖(Vickrey-Clarke-Groves)似乎是Vickrey拍卖的广义形式。McAfee拍卖是Vickrey拍卖的延伸。买方和卖方向拍卖师提交私人出价,其中买方(卖方)的出价大于(小于)阈值价格,获胜者将支付未赢得拍卖的最高价格。
Jiao等人提出了一种基于贝叶斯最右机智的最优价格封标拍卖市场模型。首先,数据源分为三组:众包数据、社交数据和感知数据。然后,定义成本函数、满意率函数和数据效用函数。根据这些函数,确定数据商品的起始价格。在贝叶斯利润最大化拍卖过程中,计算了估值分布函数。基于该函数,确定了最优价格点和次优价格点。同时,确定了从这些收集器中获取的最佳数据大小。不过这项拍拍卖计划只考虑一轮拍卖。 -
组合拍卖
买卖双方都不能通过简单的数据糅合来满足交易。因此提出投标人可以对商品的组合和捆绑进行投标的组合拍卖。
投标人提交的投标包含多种商品的组合和组合的价格。然后,拍卖师根据投标人的出价和要求为投标人做出最佳分配。
5.3.2.2.数据拍卖模型中的隐私保护方案
一般来说,拍卖方案中的隐私保护方法可以分为三个方面:匿名、密码系统和扰动,这些方面有可能在大数据交易市场中为保护隐私而扩展。
- 匿名
匿名提供了一种有效的方法来保护投标人隐私免受公众侵害,例如拍卖结果。这种方法只是匿名化公共信息的敏感部分。
在应用匿名方法时,隐私将通过攻击(链接攻击等)释放。 - 密码系统
能有效方式攻击装入侵拍卖系统。
常见方法,同态加密系统,在拍卖系统中添加一个代理来协助拍卖,并确保系统每个部分不能包含所有投标人的私人信息。 - 扰动
当敌人试图通过比较几个类似出价产生的拍卖结果来推断竞标者的个人资料时,可以应用扰动方法,其中包括差分隐私。
差分隐私方案为拍卖结果增加了随机噪声,并确保相同的竞标者的个人资料不会产生相同的拍卖结果。
5.3.2.3.第三方拍卖平台
基于同态加密隐私保护概念的拍卖平台。系统包括拍卖师(AC)和中间平台(IP)两个独立的实体。
所有敏感的出价都使用Paillier密码系统进行加密,并辅以一次性密码本。在这种结构下,所有投标首先由中间平台以密文的形式接收,并使用Paillier加密。这些出价在发送给拍卖师之前将用一次性密码本伪装。此外,此设计使目标拍卖数据只能由拍卖获胜者访问。最后,应用Paillier密码系统的数字签名功能来确保数据在传输过程中,或被受感染的拍卖师或平台操纵。
该设计解决了与不受信任的第三方拍卖人进行数据拍卖的隐私保护问题。
总体时间复杂度为O(nlogn),允许大规模部署,且能安全抵御参与者关注的不同类型的攻击。
6.数据保护
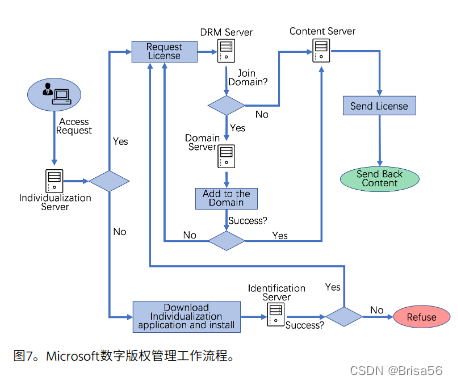
6.1.数字版权管理(DRM)
数字版权管理是为了防止数字内容被故意复制、共享和窃取而建立的,更重要的是作为数字版权保护发展的指导方针。
实现DRM的方法有很多,比如 XrML Rights Expression Language , Microsoft DRM , Apple HLS DRM , Adobe Flash access DRM , RealNetworks Helix DRM , and the OMA DRM Specification。
所有这些方案都包括五个关键因素:安全性(专注于内容加密,以及数字内容的哈希加密,水印和数字签名的创建);访问控制(身份和访问管理);使用控制(监视授权用户的使用情况并记录);许可证管理(发布许可证,控制检查许可证有效期);支付管理,(计算用户需要支付的费用)
6.2.数字版权管理模式
DRM模式基于不同的数字内容大致分为三类:基于软件的DRM;基于多媒体的DRM;基于非结构化数据的DRM
-
基于软件的DRM
最常见。
软件易于复制生产,成本为0。因此软开公司通常会设计版权保护防止盗版入侵的机制。
一个最佳的DRM机制可以记录安装时间和PC识别信息,并支持多个主机的安装。
涉及两种主要方法,联机身份验证和脱机身份验证。
ReavisConner和 Rumelt提出了一个成本函数来衡量解密的复杂性 。如果解密成本大于此函数确定的价格,则软件是安全的。Barapatre等人提出了一种结构来增加解密许可证文件的复杂性。 -
基于多媒体的DRM
一般而言,加密和水印都是用在这个方向。
David和Zaide nberg提出了一种使用选择性的视频解密的方案, 以确保内容的安全性,同时减少加密时间。
一种基于H.264编解码标准的盲水印算法,用于视频水印。
3D 视频内容中基于深度图像的渲染 (DIBR)。该算法基于伪3D离散余弦变换(3D-DCT)和量化指数调制(QIM)将水印嵌入到深度图中,提高了水印的鲁棒性,避免了视频内容的损坏。
对于基于图像的水印系统,通常使用离散小波变换 (DWT)、最低有效位 (LSB) 和离散余弦变换 (DCT) 算法将水印嵌入到安全密钥中。此外,可以将多个水印嵌入到一个图像中。此外,水印方案已被用于跟踪匿名互联网恶意流量,以识别恶意来源以进行取证。 -
基于非结构化数据的DRM
Shi等人提出了基于概率数据结构(BloomFilter)的 保护方案。将状态记录到具有正性或属性表及的Bloom过滤器中。
7.结论
首先,回顾与大数据相关的现有研究,并明确了大数据生命周期。
然后,回顾了与大数据定价的现有工作:关于数据定价,关于数据交易,关于数据保护。