按照课程安排,接下来半年,我将会去上一个为期半年的大数据课程。第一课是马士兵老师机构的周老师所讲,这里单纯记录讲课的内容。
问题1:
我有一万个元素(比如数字或单词)需要存储? 如果查找某一个元素,最简单的遍历方式复杂的是多少? 如果我期望复杂度是O(4)呢?
答案:
使用hash查找法,可以定义一个hash算法,将数据宽度变为4,(比如这个hash算法为%2500)那么整个查找的复杂度为O(4)
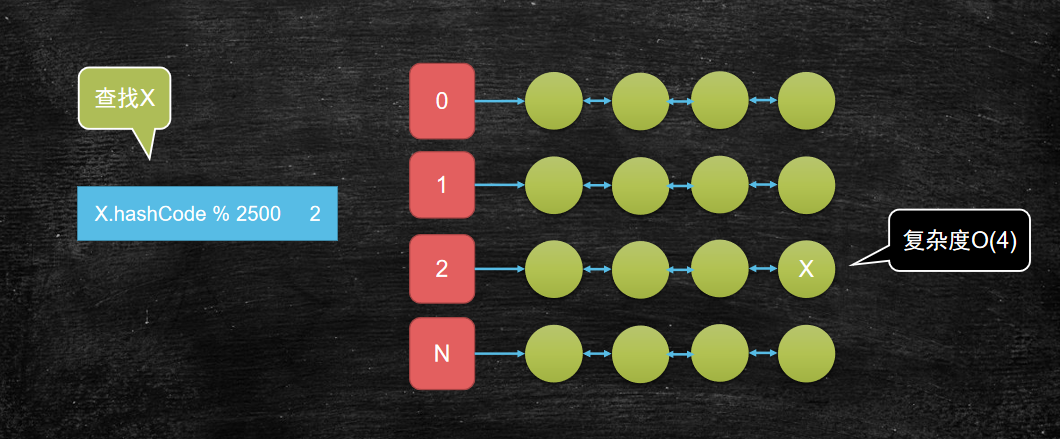
将问题分而治之的思想就是分治思想,常常用于很多地方:
如:
- redis集群
- ElasticSearch
- Hbase
- Hadoop生态
问题2:
有一个非常大的文本文件,里面有很多很多的行,只有两行一样,它们出现在未知的位置,需要查找到它们。 单机,而且可用的内存很少,也就几十兆。
答案:
传统做法是将第一行与其他行比较,第二行与其他行比较,这样的话需要遍历最多N*N次
我们现在花费30min将该文件进行分文件操作,使用hash进行分文件
假设Io速度是500MB每秒 1T文件读取一遍需要约30分钟 循环遍历需要N次Io时间 分治思想可以使时间为2次io
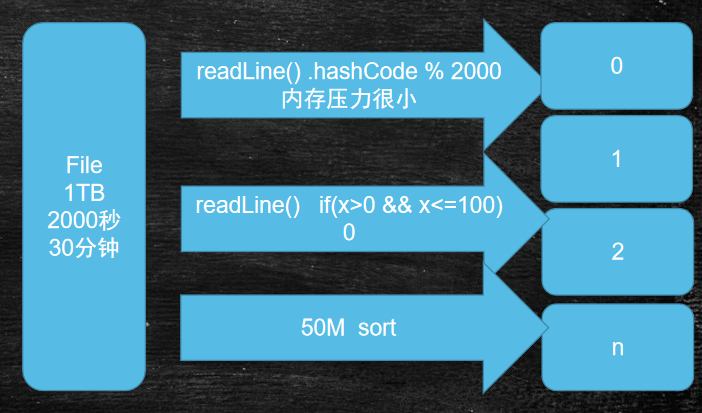
这样,接下来将进行依次将小文件的2行看看是否一样,那么就很快了
方法总结:首先外部排序,然后进行内部比较
问题3:
如果我们存储的都是数值类型的数据呢,那么利用hash可能导致原本的数据失去有效性。
答案:
我们可以将文件先随机定义一个区块大小,将数值类文件进行分区块,那么对每个区块内部排序。
再定义一个指针,指向每个区块的头部,那么依次比较头部区域,然后进行接下来的按顺序写入,则
可以很快解决该问题。
方法总结:首先定义固定区块,然后内部排序,然后再进行定义指针,进行外部排序
分布式的前提背景:
我们目前如果使用超高计算的计算机,那么资金方面将会达到E的级别。所以我们采用分布式进行计算。
当我们拥有2000台机器,并行进行计算,那么将会节省1/2000的时间,相当于几秒钟就可以计算完毕。
但是这陷入一个怪圈:
如果1T的文件,2000台未必比1台快,在我们分发文件的时候,往往进行IO传输,那么将会消耗2000*30min的IO时间,那么这样和1台比较,还是1台处理的速度可能更快。
继续考虑:
如果每天都有1T数据进行产生,那么1台机器的负荷将在1年内大量增加,但是2000台消耗的时间依旧是和第一天处理数据的时间是一样的。增量一年,最后1台机器将难以负荷,但是2000台机器依旧运算完好
大数据运算的结论:
1.分治思想
2.并行计算
3.计算向数据移动(减少传输IO消耗的时间)
4.数据本地化读取
这四个条件将是整个大数据技术需要关心的重点
基本常识:
1.Hadoop之父Doug Cutting
2.3篇著名的Google论文
《Google File System》 2003
《MapReduce:Simplified Data Processing on Large Clusters》 2004
《Bigtable:A Distributed Storage System for Structured Data》2006
3.hadoop的网址:hadoop.apache.org
关于apache基金会,hadoop域名在顶级域名,凡是达到一定高度才会在apache域名前
大数据生态:

图:大数据生态(来源:周老师PPT)
关于hadoop的版本,大部分公司还是使用2.6.0版本,目前3.x版本也要学