
版本说明:
SeaTunnel:apache-seatunnel-2.3.2-SNAPHOT
引擎说明:
Flink:1.16.2
Zeta:官方自带
前言
近些时间,我们正好接手一个数据集成项目,数据上游方是给我们投递到Kafka,我们一开始的技术选型是SpringBoot+Flink对上游数据进行加工处理(下文简称:方案一),由于测试不到位,后来到线上,发现数据写入效率完全不符合预期。后来将目光转到开源项目SeaTunnel上面,发现Source支持Kafka,于是开始研究测试,开发环境测试了500w+数据,发现效率在10000/s左右。果断放弃方案一,采取SeaTunnel对数据进行集成加工(下文简称:方案二)。在SeaTunnel研究的过程中,总结了两种方法,方法二相较于方法一,可以实现全场景使用,无需担心字段值里面各种意想不到的字符对数据落地造成错位现象的发生。
对比

在方案二的基础上又衍生出两种方法 
所以,在经过长时间的探索和我们线上验证得出结论,建议使用方案二的方法二。
好了,我们进入正文,主篇幅主要介绍方案二中的两种方法,让大家主观的感受SeaTunnel的神奇。
方案一 Springboot+Flink实现Kafka 复杂JSON的解析
网上案例很多,在此不做过多介绍。
方案二 SeaTunnel实现Kafka复杂JSON的解析
在开始介绍之前,我们看一下我们上游方投递Kafka的Json样例数据(对部分数据进行了敏感处理),如下:
"magic": "a***G",
"type": "D***",
"headers": null,
"messageSchemaId": null,
"messageSchema": null,
"message": {
"data": {
"LSH": "187eb13****l0214723",
"NSRSBH": "9134****XERG56",
"QMYC": "01*****135468",
"QMZ": "1Zr*****UYGy%2F5bOWtrh",
"QM_SJ": "2023-05-05 16:42:10.000000",
"YX_BZ": "Y",
"ZGHQ_BZ": "Y",
"ZGHQ_SJ": "2023-06-26 16:57:17.000000",
"SKSSQ": 202304,
"SWJG_DM": "",
"SWRY_DM": "00",
"CZSJ": "2023-05-05 16:42:10.000000",
"YNSRSBH": "9134****XERG56",
"SJTBSJ": "2023-06-26 19:29:59.000",
"SJCZBS": "I"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "12440977",
"timestamp": "2023-06-26T19:29:59.673000",
"streamPosition": "00****3.16",
"transactionId": "000***0006B0002",
"changeMask": "0FFF***FF",
"columnMask": "0F***FFFF",
"transactionEventCounter": 1,
"transactionLastEvent": false
}
}
}
方法一、不通过UDF函数实现
存在问题:字段值存在分隔符,例如‘,’ 则数据在落地的时候会发生错位现象。
该方法主要使用官网 transform-v2的各种转换插件进行实现,主要用到的插件有 Replace、Split以及Sql实现
ST脚本:(ybjc_qrqm.conf)
env {
execution.parallelism = 100
job.mode = "STREAMING"
job.name = "kafka2mysql_ybjc"
execution.checkpoint.interval = 60000
}
source {
Kafka {
result_table_name = "DZFP_***_QRQM1"
topic = "DZFP_***_QRQM"
bootstrap.servers = "centos1:19092,centos2:19092,centos3:19092"
schema = {
fields {
message = {
data = {
LSH = "string",
NSRSBH = "string",
QMYC = "string",
QMZ = "string",
QM_SJ = "string",
YX_BZ = "string",
ZGHQ_BZ = "string",
ZGHQ_SJ = "string",
SKSSQ = "string",
SWJG_DM = "string",
SWRY_DM = "string",
CZSJ = "string",
YNSRSBH = "string",
SJTBSJ = "string",
SJCZBS = "string"
}
}
}
}
start_mode = "earliest"
#start_mode.offsets = {
# 0 = 0
# 1 = 0
# 2 = 0
#}
kafka.config = {
auto.offset.reset = "earliest"
enable.auto.commit = "true"
# max.poll.interval.ms = 30000000
max.partition.fetch.bytes = "5242880"
session.timeout.ms = "30000"
max.poll.records = "100000"
}
}
}
transform {
Replace {
source_table_name = "DZFP_***_QRQM1"
result_table_name = "DZFP_***_QRQM2"
replace_field = "message"
pattern = "[["
replacement = ""
#is_regex = true
#replace_first = true
}
Replace {
source_table_name = "DZFP_***_QRQM2"
result_table_name = "DZFP_***_QRQM3"
replace_field = "message"
pattern = "]]"
replacement = ""
#is_regex = true
#replace_first = true
}
Split {
source_table_name = "DZFP_***_QRQM3"
result_table_name = "DZFP_***_QRQM4"
# 存在问题: 如果字段值存在分隔符 separator,则数据会错位
separator = ","
split_field = "message"
# 你的第一个字段包含在zwf5里面,,前五个占位符是固定的。
output_fields = [zwf1,zwf2,zwf3,zwf4,zwf5,nsrsbh,qmyc,qmz,qm_sj,yx_bz,zghq_bz,zghq_sj,skssq,swjg_dm ,swry_dm ,czsj ,ynsrsbh ,sjtbsj ,sjczbs]
}
sql{
source_table_name = "DZFP_***_QRQM4"
query = "select replace(zwf5 ,'fields=[','') as lsh,nsrsbh,trim(qmyc) as qmyc,qmz,qm_sj,yx_bz, zghq_bz,zghq_sj,skssq,swjg_dm ,swry_dm ,czsj ,ynsrsbh ,sjtbsj ,replace(sjczbs,']}]}','') as sjczbs from DZFP_DZDZ_QRPT_YWRZ_QRQM4 where skssq <> ' null'"
result_table_name = "DZFP_***_QRQM5"
}
}
sink {
Console {
source_table_name = "DZFP_***_QRQM5"
}
jdbc {
source_table_name = "DZFP_***_QRQM5"
url = "jdbc:mysql://localhost:3306/dbname?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
user = "user"
password = "pwd"
batch_size = 200000
database = "dbname"
table = "tablename"
generate_sink_sql = true
primary_keys = ["nsrsbh","skssq"]
}
}
正常写入数据是可以写入了。
写入成功如下:
● kafka源数据: 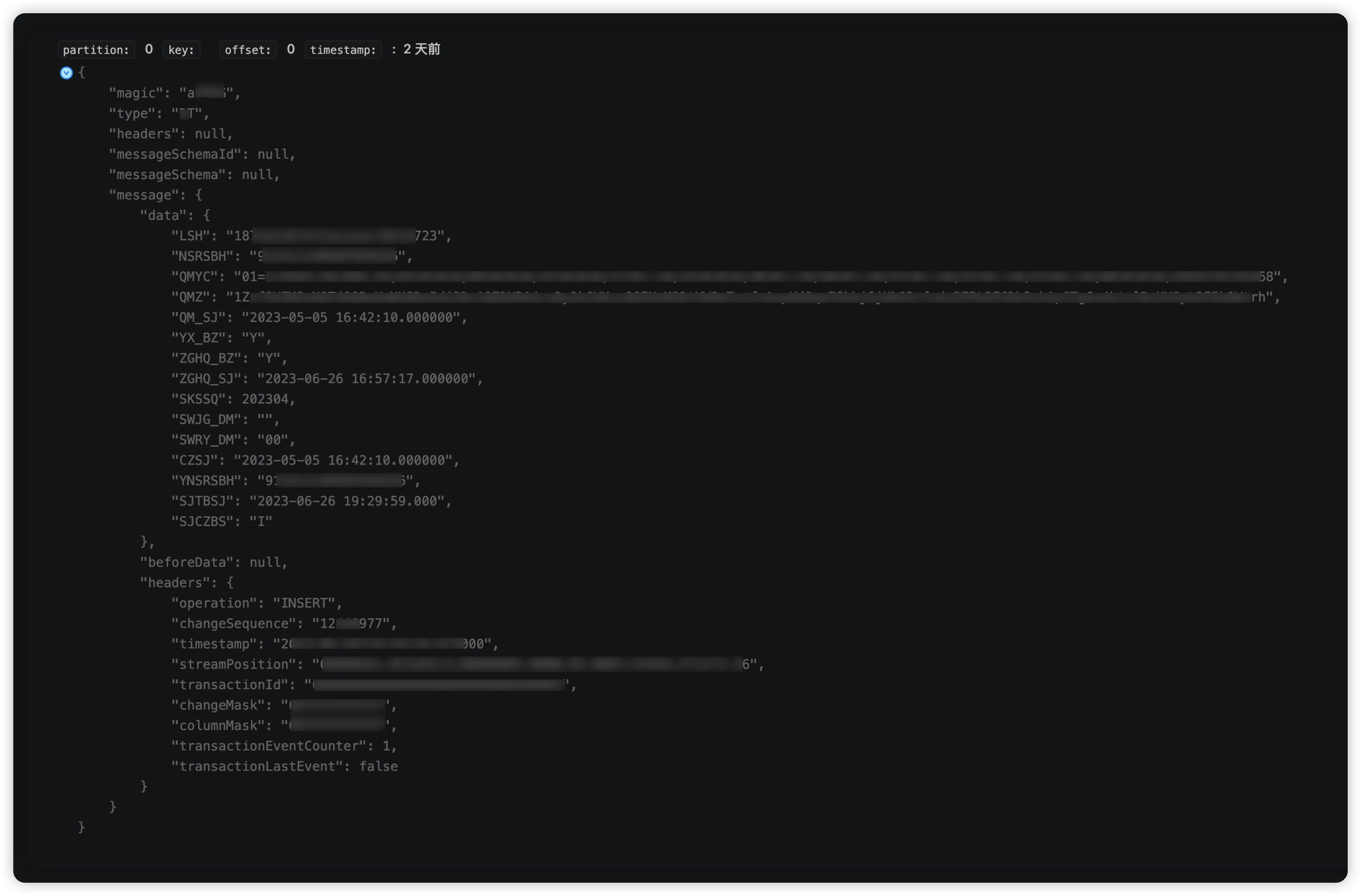 ● tidb目标数据:
● tidb目标数据:  现在我们模拟给kafka发送一条数据,其中,SJTBSJ字段我在中间设置一个, 是逗号。
现在我们模拟给kafka发送一条数据,其中,SJTBSJ字段我在中间设置一个, 是逗号。
原始值:2023-06-26 19:29:59.000 更改之后的值2023-06-26 19:29:59.0,00
往topic生产一条数据命令
kafka-console-producer.sh --topic DZFP_***_QRQM --broker-list centos1:19092,centos2:19092,centos3:19092
发送如下:
"magic": "a***G",
"type": "D***",
"headers": null,
"messageSchemaId": null,
"messageSchema": null,
"message": {
"data": {
"LSH": "187eb13****l0214723",
"NSRSBH": "9134****XERG56",
"QMYC": "01*****135468",
"QMZ": "1Zr*****UYGy%2F5bOWtrh",
"QM_SJ": "2023-05-05 16:42:10.000000",
"YX_BZ": "Y",
"ZGHQ_BZ": "Y",
"ZGHQ_SJ": "2023-06-26 16:57:17.000000",
"SKSSQ": 202304,
"SWJG_DM": "",
"SWRY_DM": "00",
"CZSJ": "2023-05-05 16:42:10.000000",
"YNSRSBH": "9134****XERG56",
"SJTBSJ": "2023-06-26 19:29:59.0,00",
"SJCZBS": "I"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "12440977",
"timestamp": "2023-06-26T19:29:59.673000",
"streamPosition": "00****3.16",
"transactionId": "000***0006B0002",
"changeMask": "0FFF***FF",
"columnMask": "0F***FFFF",
"transactionEventCounter": 1,
"transactionLastEvent": false
}
}
}
写入之后,发现数据错位了。 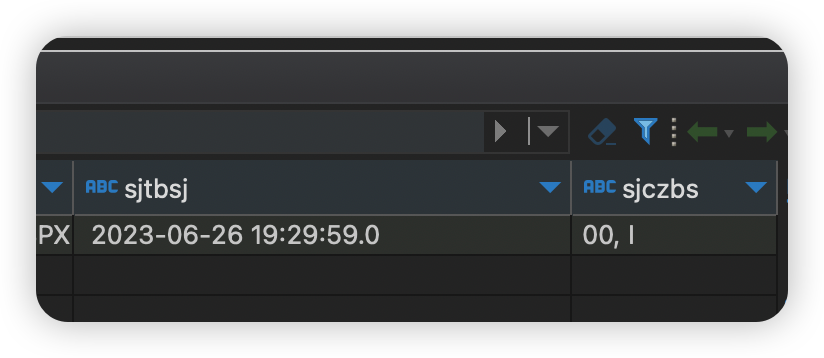
结论:其实这个问题线上还是能遇到的,比如地址字段里面含有逗号,备注信息里面含有逗号等等,这种现象是不可避免的,所以此种方案直接pass。对数据危害性极大!可以处理简单的数据,当做一种思路。
方法二:通过UDF函数实现
该方法通过UDF函数扩展(https://seatunnel.apache.org/docs/2.3.2/transform-v2/sql-udf)的方式,实现嵌套kafka source json源数据的解析。可以大大简化ST脚本的配置
ST脚本:(ybjc_qrqm_yh.conf)
env {
execution.parallelism = 5
job.mode = "STREAMING"
job.name = "kafka2mysql_ybjc_yh"
execution.checkpoint.interval = 60000
}
source {
Kafka {
result_table_name = "DZFP_***_QRQM1"
topic = "DZFP_***_QRQM"
bootstrap.servers = "centos1:19092,centos2:19092,centos3:19092"
schema = {
fields {
message = {
data = "map<string,string>"
}
}
}
start_mode = "earliest"
#start_mode.offsets = {
# 0 = 0
# 1 = 0
# 2 = 0
#}
kafka.config = {
auto.offset.reset = "earliest"
enable.auto.commit = "true"
# max.poll.interval.ms = 30000000
max.partition.fetch.bytes = "5242880"
session.timeout.ms = "30000"
max.poll.records = "100000"
}
}
}
transform {
sql{
source_table_name = "DZFP_***_QRQM1"
result_table_name = "DZFP_***_QRQM2"
# 这里的qdmx就是我自定义的UDF函数,具体实现下文详细讲解。。。
query = "select qdmx(message,'lsh') as lsh,qdmx(message,'nsrsbh') as nsrsbh,qdmx(message,'qmyc') as qmyc,qdmx(message,'qmz') as qmz,qdmx(message,'qm_sj') as qm_sj,qdmx(message,'yx_bz') as yx_bz,qdmx(message,'zghq_bz') as zghq_bz,qdmx(message,'zghq_sj') as zghq_sj,qdmx(message,'skssq') as skssq,qdmx(message,'swjg_dm') as swjg_dm,qdmx(message,'swry_dm') as swry_dm,qdmx(message,'czsj') as czsj,qdmx(message,'ynsrsbh') as ynsrsbh, qdmx(message,'sjtbsj') as sjtbsj,qdmx(message,'sjczbs') as sjczbs from DZFP_DZDZ_QRPT_YWRZ_QRQM1"
}
}
sink {
Console {
source_table_name = "DZFP_***_QRQM2"
}
jdbc {
source_table_name = "DZFP_***_QRQM2"
url = "jdbc:mysql://localhost:3306/dbname?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
user = "user"
password = "pwd"
batch_size = 200000
database = "dbname"
table = "tablename"
generate_sink_sql = true
primary_keys = ["nsrsbh","skssq"]
}
}
执行脚本:查看结果,发现并没有错位,还在原来的字段(sjtbsj)上面。
这种方法,是通过key获取value值。不会出现方法一中的按照逗号分割出现数据错位现象。 
具体UDF函数编写如下。
maven引入如下:
<dependencies>
<dependency>
<groupId>org.apache.seatunnel</groupId>
<artifactId>seatunnel-transforms-v2</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.seatunnel</groupId>
<artifactId>seatunnel-api</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service-annotations</artifactId>
<version>1.1.1</version>
<optional>true</optional>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.1.1</version>
<optional>true</optional>
<scope>compile</scope>
</dependency>
</dependencies>
UDF具体实现java代码如下:
package org.seatunnel.sqlUDF;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.google.auto.service.AutoService;
import org.apache.seatunnel.api.table.type.BasicType;
import org.apache.seatunnel.api.table.type.SeaTunnelDataType;
import org.apache.seatunnel.transform.sql.zeta.ZetaUDF;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@AutoService(ZetaUDF.class)
public class QdmxUDF implements ZetaUDF {
@Override
public String functionName() {
return "QDMX";
}
@Override
public SeaTunnelDataType<?> resultType(List<SeaTunnelDataType<?>> list) {
return BasicType.STRING_TYPE;
}
// list 参数实例:(也就是kafka 解析过来的数据)
//SeaTunnelRow{tableId=, kind=+I, fields=[{key1=value1,key2=value2,.....}]}
@Override
public Object evaluate(List<Object> list) {
String str = list.get(0).toString();
//1 Remove the prefix
str = StrUtil.replace(str, "SeaTunnelRow{tableId=, kind=+I, fields=[{", "");
//2 Remove the suffix
str = StrUtil.sub(str, -3, 0);
// 3 build Map key value
Map<String, String> map = parseToMap(str);
if ("null".equals(map.get(list.get(1).toString())))
return "";
// 4 return the value of the key
return map.get(list.get(1).toString());
}
public static Map<String, String> parseToMap(String input) {
Map<String, String> map = new HashMap<>();
// 去除大括号 在字符串阶段去除
// input = input.replaceAll("[{}]", "");
// 拆分键值对
String[] pairs = input.split(", ");
for (String pair : pairs) {
String[] keyValue = pair.split("=");
if (keyValue.length == 2) {
String key = keyValue[0].trim().toLowerCase();
String value = keyValue[1].trim();
map.put(key, value);
}
}
return map;
}
}
然后打包,打包命令如下:
mvn -T 8 clean install -DskipTests -Dcheckstyle.skip -Dmaven.javadoc.skip=true
查看META-INF/services, 看注解@AutoService 是否生成对应的spi接口:
如下:则打包成功!  如果没有,则打包失败,UDF函数无法使用.
如果没有,则打包失败,UDF函数无法使用.
可以参考我的打包插件:
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-site-plugin</artifactId>
<version>3.7</version>
<dependencies>
<dependency>
<groupId>org.apache.maven.doxia</groupId>
<artifactId>doxia-site-renderer</artifactId>
<version>1.8</version>
</dependency>
</dependencies>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.1.1</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>
</build>
最终打成的jar包放到 ${SEATUNNEL_HOME}/lib目录下,由于我的UDF函数引入了第三方jar包,也需要一并上传。如果是Zeta集群,需要重启Zeta集群才能生效。其他引擎实时生效。 最终上传成功如下: 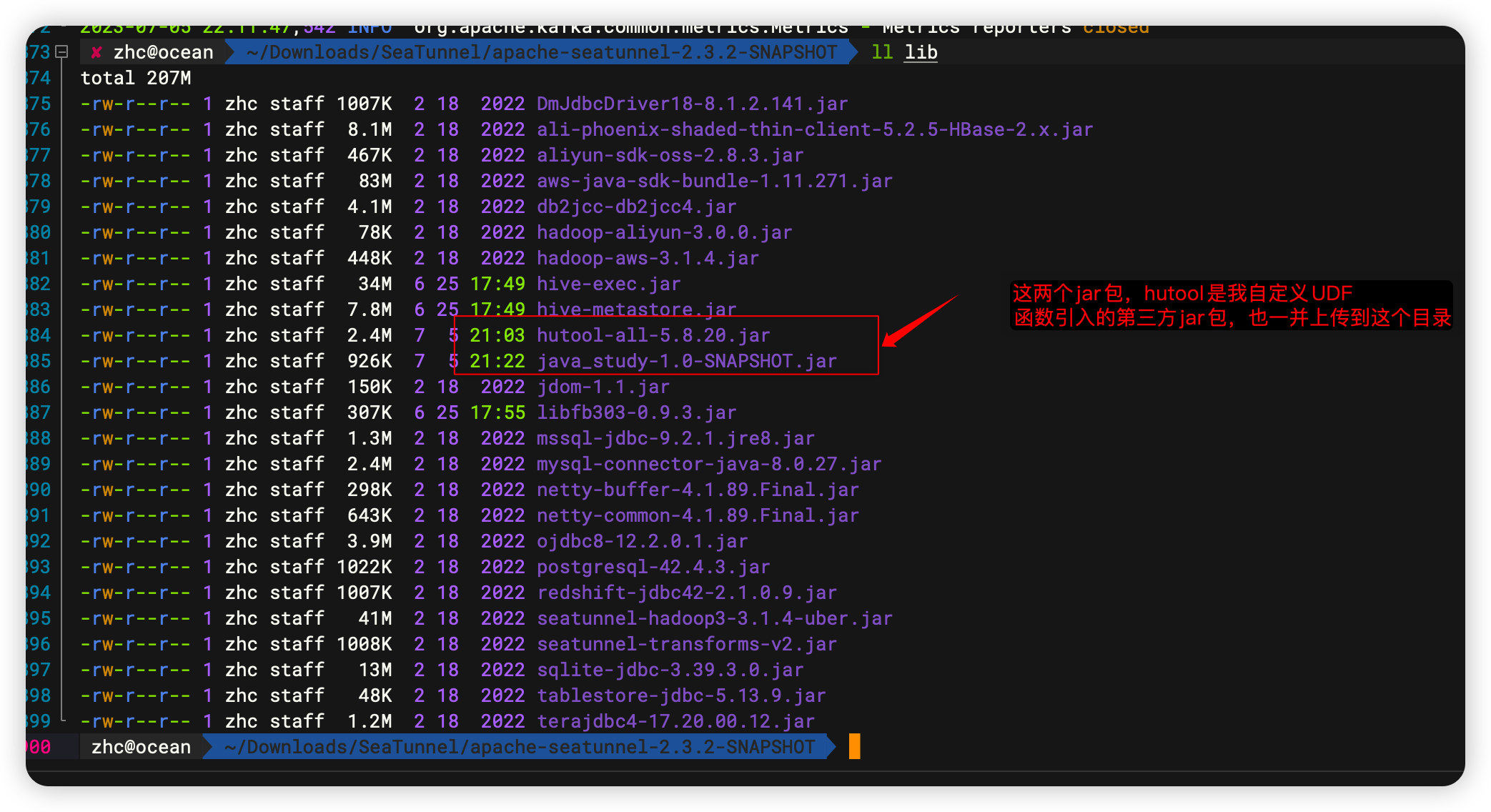 说明:这个hutool-all的jar包可以含在
说明:这个hutool-all的jar包可以含在java_study这个项目里面,我图方便,上传了两个。
综上,推荐使用通过UDF函数扩展的方式,实现嵌套kafka source json源数据的解析。
工信部:不得为未备案 App 提供网络接入服务 Go 1.21 正式发布 阮一峰发布《TypeScript 教程》 Vim 之父 Bram Moolenaar 因病逝世 某国产电商被提名 Pwnie Awards“最差厂商奖” HarmonyOS NEXT:使用全自研内核 Linus 亲自 review 代码,希望平息关于 Bcachefs 文件系统驱动的“内斗” 字节跳动推出公共 DNS 服务 香橙派新产品 Orange Pi 3B 发布,售价 199 元起 谷歌称 TCP 拥塞控制算法 BBRv3 表现出色,本月提交到 Linux 内核主线本文由 白鲸开源科技 提供发布支持!