
在 4 月中旬的 SeaTunnel&TDengine 联合 Meetup 上,来自 北京沃东天骏信息技ason术有限公司的架构师 李宏宇,为大家带来了《使用SeaTunnel搞定TDengine数据同步》,通过 TDengine-Connector 解析与使用示例介绍了 SeaTunnel 与实时数据库 TDengine 同步集成的过程。演讲内容整理如下:
大家好,我叫李宏宇,目前主要关注的方向是数据仓库,包括构建、集成、开发,以及应用端,目前主要聚焦的一个更细分实时数仓领域。今天跟大家分享的一个主题是我们怎么样使用 SeaTunnel 这样一个数据集成和同步引擎,完成实时数据库 TDengine 数据的导入导出,以及同步集成的过程。
本次分享大概分为以下几个部分:
● SeaTunnel 基本概念介绍
● TDengine Connector 功能特性
● TDengine Connector 读取解析
● TDengine Connector 写入解析
● TDengine Connector 使用示例
● 如何参与贡献
SeaTunnel 基本概念介绍
1 SeaTunnel 示例
讲解SeaTunnel 的基本概念,我觉得最好的方式方法就是把 SeaTunnel 使用的示例给大家直接展示出来,很多关于 SeaTunnel 的基本概念和重要概念都可以通过示例都可以引出来。
SeaTunnel 是一个什么样的引擎?它是一个国产的数据同步集成框架和引擎。目前,是SeaTunnel 在ASF 孵化器中处于孵化阶段。我个人认为 SeaTunnel 引擎最大的亮点和方便之处体现在它把整个数据集成这个领域中的过程和逻辑的定义全部压缩到了 DSL 配置文件里,通过简单、清晰明了的配置文件,可以把整个数据集成的过程描述得很清楚,并且把整个集成过程中可能会遇到的各种细节问题都做了封装,有了它,可以大幅度地简化数据集成的难度。
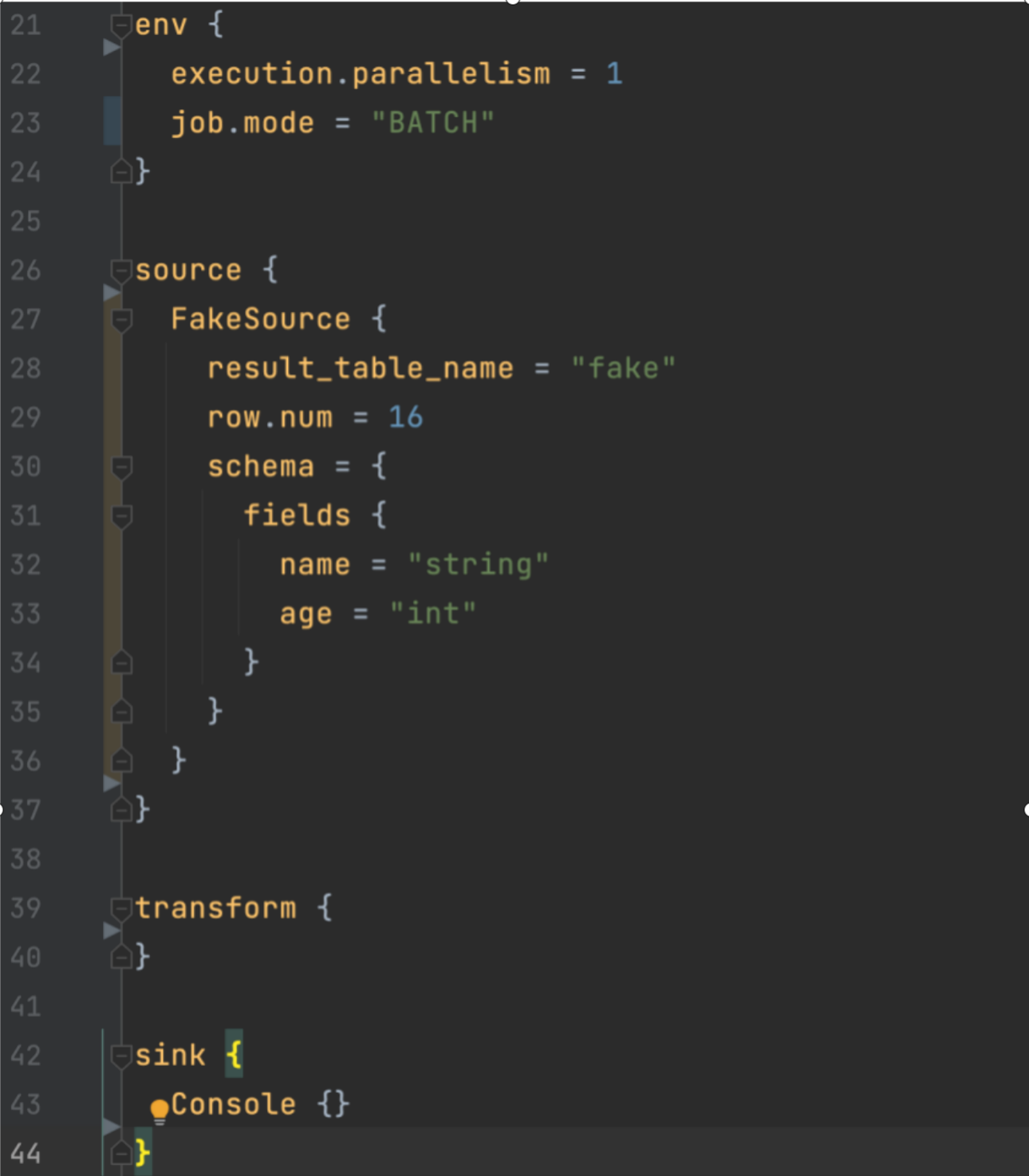 上图展示了一个最基本的简单的数据集成,在 SeaTunnel 配置 1 个示例大概分成 4 个部分,env 主要是用于配置数据集成任务的环境信息,比如并行度、任务的执行模式等。其他三个包括 Source、Transform 和 Sink,分别对应数据从一个目标,经过一个转换过程,输出到另一个目标,所以,这 4 个部分就把整个数据集成的过程描述得很清晰。
上图展示了一个最基本的简单的数据集成,在 SeaTunnel 配置 1 个示例大概分成 4 个部分,env 主要是用于配置数据集成任务的环境信息,比如并行度、任务的执行模式等。其他三个包括 Source、Transform 和 Sink,分别对应数据从一个目标,经过一个转换过程,输出到另一个目标,所以,这 4 个部分就把整个数据集成的过程描述得很清晰。  上图表示把配置文件保存好之后,丢到 SeaTunnel 引擎上去执行,就可以得到对应的执行结果。
上图表示把配置文件保存好之后,丢到 SeaTunnel 引擎上去执行,就可以得到对应的执行结果。
当我们对 SeaTunnel 有了一个整体的认识之后,来看一下它到底是怎么来实现的数据同步的过程。
2 SeaTunnel整体架构
在此之前我们需要了解一下 SeaTunnel 的整体架构,它总体上大概分成三个层次,分别对应的是上面的 API connectors 的 API 层,中间的 Translation 翻译层,以及最下面的引擎层,即实际中跑数据的这一层。  Connector API 这一层的主要任务,是把不同的数据终端,包括 Hadoop,TDengine 等各种不同的数据源的接入的逻辑全部做一个公共的抽象,以便于适配不同的数据源。
Connector API 这一层的主要任务,是把不同的数据终端,包括 Hadoop,TDengine 等各种不同的数据源的接入的逻辑全部做一个公共的抽象,以便于适配不同的数据源。
其中包括 4 个小的组成构件,分别是Source、Sink,分别对应数据源输入和数据输出的行为模式。Data type,即具体到数据类型,不同的数据终端和不同的数据类型,怎么和引擎做桥接的构建。以及任务容错机制,对应了 state 状态存储。所以,这 4 个部分加在一起就定义好了 1 个 connector 的基本行为模式。
定义好了这些组件的行为之后,我们会经过中间 Translation 这一层把它翻译为下面的引擎层里具体可以执行的代码和逻辑,这样就完成了不同的 connector 到不同引擎的适配过程,所以 Translation 层主要是完成了适配,是一个 adapter。
具体到引擎层,目前我们支持 Spark、Flink 和 SeaTunnel Zeta 引擎。SeaTunnel Zeta 是社区自己研发的一款轻量级的,专门应对数据同步场景的数据同步引擎,是可以屏蔽掉 Spark 和 Fink 的。
关于 SeaTunnel Zeta 更详细的信息,可参考文章了解:https://www.bilibili.com/read/cv20989971
3 SeaTunnel Connector 简介
接下来介绍 SeaTunnel connector 的开发模式和开发特点。
Connector 主要由两个部分,Source 和 Sink 组成,分别对应了数据的读取过程和数据的写出过程。这两个组件中间,有一个数据的抽象层,把数据抽象成 SeaTunnelRow 抽象类,用于承载实际数据传输过程中的载体。
在此需要特别提到,除了数据本身以外,我们目前有一些元数据的传输过程也是在 SeaTunnelRow 上的,所以数据本身和元数据都是通过这样的抽象层完成传输。
所以有了 Zeta,Source、抽象层和 Sink,我们就可以在不同的数据源和数据终端之间做数据的迁移和搬运。这就是 connector 的基本情况。
4 SeaTunnel Connector 生态
SeaTunnel Connect 目前已经接入比较常用的 100 多个数据终端,待接入和进行中的大概有 300 多个。
目前 SeaTunnel Connector 接入详情见链接: https://seatunnel.incubator.apache.org/docs/2.3.1/Connector-v2-release-state https://github.com/apache/incubator-seatunnel/issues/3018
如果有直接在线上做部署的想法,大家可以参考链接详细信息,踊跃贡献社区。
TDengine Connector 功能特性
接下来来看 TDengine Connector 的具体情况。
1TDengine 重要概念说明
以 TDengine 为例,这里需要先说明两个关于 TDengine 的基本概念,方便大家理解。
TDengine是一款国产时序数据库,数据按时间先后顺序存储和检索。所谓时序数据库,就是字面理解,按时间顺序把数据进行存顺序存储和检索的这样一款数据库。
它主要面对的场景包括物联网领域的数据,其中两个与数据同步相关的概念,一个叫Super Table,也叫STable,就是超级表,一个叫 Subtable 子表,这两个表之间是什么关系呢? 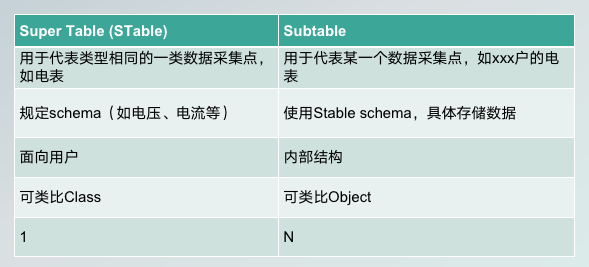 你可以理解为就是 Super Table 是对于相同数据类型的一类数据采集点的抽象,比如电表就可以作为一个 Super Table,具体到某一户的某一块电表,作为一条具体的数据,具体的数据采集量存储在 Subtable 里面。
你可以理解为就是 Super Table 是对于相同数据类型的一类数据采集点的抽象,比如电表就可以作为一个 Super Table,具体到某一户的某一块电表,作为一条具体的数据,具体的数据采集量存储在 Subtable 里面。
另外,Super Table 主要完成的是 schema 定义,Subtable 是使用 Schema 去完成具体的数据存储。Super Table 主要面向的使用场景是用户操作 Super Table,Subtable 更多的是一个内部的结构,一般来讲是不让用户直接进行操作。可以类比为我们面向对象的概念里面的 class 和 object 这样的概念,所以它们两个之间的对应关系也就是一对 n 的对应关系。
这里面有着 TDengine 比较独特的一个设计理念,就是一个设备一张 Subtable。在后面的数据同步的时候,跟这个理念设计是有一些关系的,所以在这简单跟大家提一下。
2 Source 功能特性
再具体说一下 SeaTunnel TDengine Source 这一端,现在已经具备了哪些功能特性,实现方式,以及应用场景。 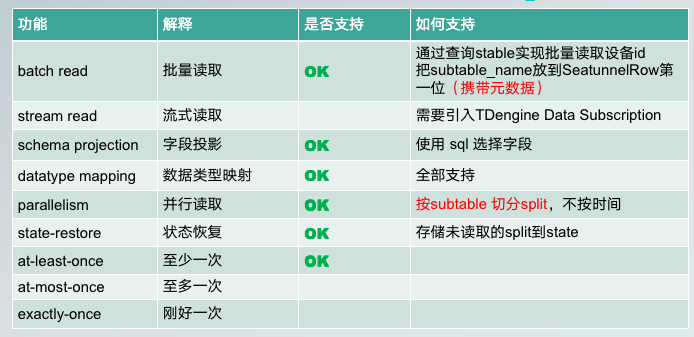 TDengine Source,即读取端现在支持批量读取。具体实现方式其实很简单,就是通过访问 stable,而不是具体到某一个 Subtable,通过 SCO,因为 SP 下辖了很多 subtable 指标,所以就对 SCO 的定义和访问,就可以批量获取到所有设备 ID 的持续数据。注意,子表名其实就是设备 ID,这个设备 ID 在用户直接访问超级表时是无法直接访问到的,因为它是相对比较隐藏的一层。但是在 Sink 端,我们在输出数据的时候需要这部分数据,所以,目前表名子表 ID 我把它放在了 SeaTunnelRow 的第一位,还携带了元数据,刚才我们也有提到这种设计。
TDengine Source,即读取端现在支持批量读取。具体实现方式其实很简单,就是通过访问 stable,而不是具体到某一个 Subtable,通过 SCO,因为 SP 下辖了很多 subtable 指标,所以就对 SCO 的定义和访问,就可以批量获取到所有设备 ID 的持续数据。注意,子表名其实就是设备 ID,这个设备 ID 在用户直接访问超级表时是无法直接访问到的,因为它是相对比较隐藏的一层。但是在 Sink 端,我们在输出数据的时候需要这部分数据,所以,目前表名子表 ID 我把它放在了 SeaTunnelRow 的第一位,还携带了元数据,刚才我们也有提到这种设计。
流式数据的读取,目前还没有接入,这块是我们下一步要接入的一个方向。方案是引入 TDengine subscription 特性。
字段投影,字段映射,我们可以在配置中的 Transform 选取若干字段做同步,或者进行字段重命名。
数据类型映射,TDengine 所有的数据类型目前是都支持的。
并行读取,大家主要做的是分片,然后并行多线程地去读数据。TDengine 里的设计是按照 subtable,就是按子表去切分数据分片,而不是像其他的一些数据引擎时序数据引擎那样按照时间去切分片。
为什么这样设计?这就与我们刚才提到一个设备一张表的设计理念有关。TDengine 表示,这是因为在数据集成同步的场景下,按表同步,而不是把表切分后再按照时间做切分,性能会更高。因此,按时间同步因为涉及到地点认证本身的数据存储模式和其他的数据实际数据引擎的一个设计上的不同,所以这块也做了一些取舍。
关于容错的,就是状态恢复,包括至少一次至多一次刚好一次的语义,目前实现的是至少一次,具体的时间逻辑还要具体跟大家讨论。
3 Sink 功能特性
Sink 端是 c 端在接入数据以后,把数据写入到对应的 TDengine 实例,涉及元数据的识别过程。 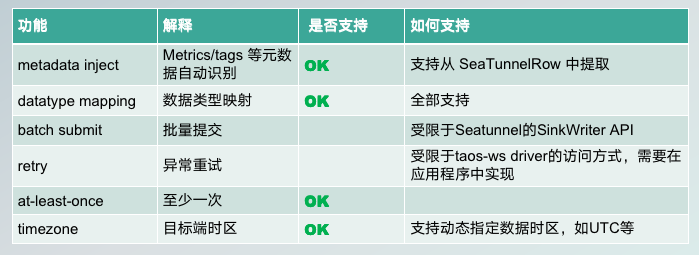 目前,数据是分具体的指标以及指标对应的 title,我们叫标签,字段的识别是自动的,我们的 connector 自己去完成,不需要用户配置。识别完了之后,取出对应的字段,就可以完成一个插入操作了。
目前,数据是分具体的指标以及指标对应的 title,我们叫标签,字段的识别是自动的,我们的 connector 自己去完成,不需要用户配置。识别完了之后,取出对应的字段,就可以完成一个插入操作了。
数据类型映射和 Source 一样,是全部都支持的。
批量提交和异常重试,受限于我们现在使用的 HTTP 的 restful 风格的 driver,导致这两个目前还没有实现,但后续会追加上。
对应的容错机制也是至少一次的保证。
这里特别提一下,在时域数据库里时间、 time、stamp、字段是相对比较重要的,所有的数据都是跟着 stamp 走的,所以在数据跨时区导入导出的时候,可能会涉及到时区的变更,所以这块也专门提供了市时区指定的功能。
TDengine Connector 读取解析
下面我分别解读一下 TDengine Connector 读取和写入的功能模块实现方式及功能特性。
1 字段类型映射
关于读取这一部分,目前所有 TDengine 的数据类型都是可以完整映射到 SeaTunnel 数据类型的。
但是这里面有一个特例,就是 Json。目前我们把 Json 当成了一个 string 进行传输和导入导出。如果后续有具体的场景和需求,需要 Json 单独和 SQL 分开处理,我们可以再做进一步迭代。
2 批量读取
关于批量读取,由于 TDengine 本身的设计特点,所有的批量数据的读取是针对超级表的操作,而超级表的操作是在 Source 端。我们在实现逻辑的时候,实际上是把超级表的同步过程翻译为了若干的子表的同步过程,由子表的每一张子表对应一个不同的分片,就可以把批量同步数据,而不是对时间分片做更细的分片。
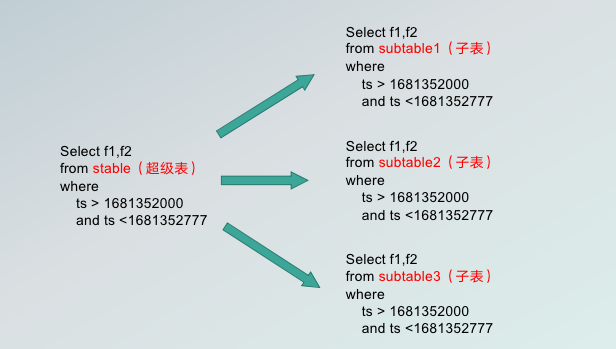 这张图可以清晰地展示批量读取的过程。
这张图可以清晰地展示批量读取的过程。
3并行读取:切分Split,分配Reader
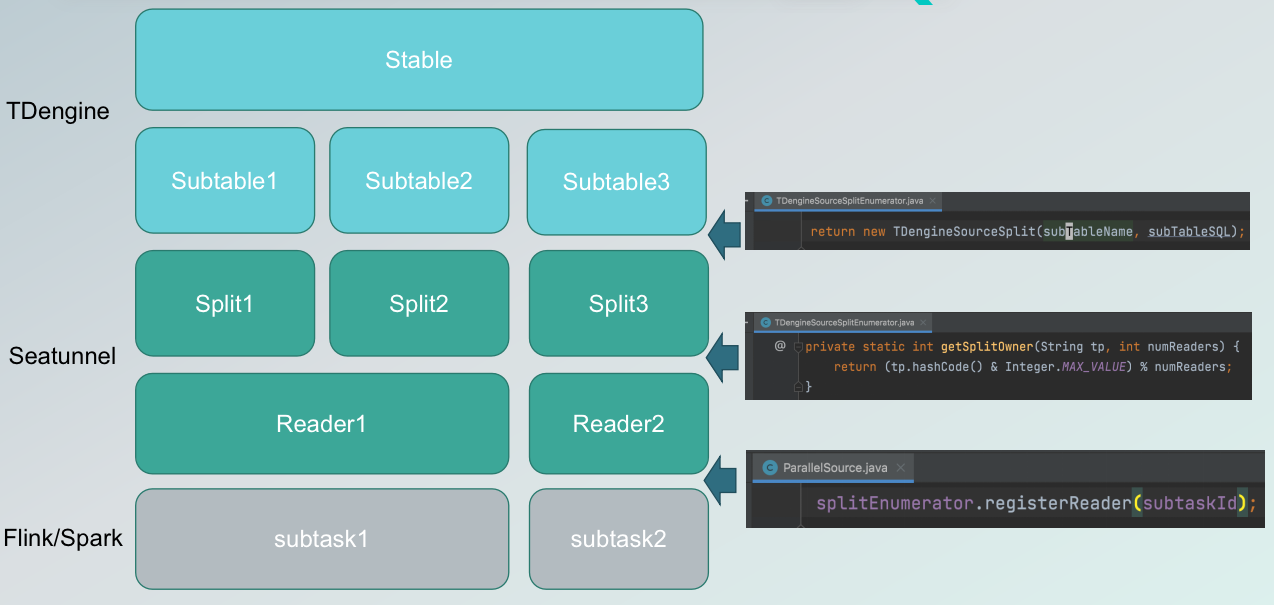
上图展示了不同的技术组件,在不同的层次上起到的不同作用,以及不同的组件里面概念之间一对一,和一对多的对应关系。
首先,我们要同步的数据源就是 TDengine,要同步的是某一张 stable,就是 super table,supertable 下面一对多地映射了多张 subtable,我们在实际导入导出的时候,实际上是把不同的子表映射到 SeaTunnel 分片上去,SeaTunnel 分片再通过哈希方式把它们分配给不同的 reader。不同的 Reader 再对应到不同的引擎底层的具体的执行单元,比如 Flink 的 sub task。这样就完成了数据的并行读取,以及具体 split 的拆分和 reader 的映射关系。
4 状态恢复
Reader 的状态恢复其实和 Flink 和 Spark 的很多做法类似。
当进程宕掉或者出现问题的时候,需要把 Reader 所有还没有读到的那些split 以及正在读还没读完的 split,存储到对应的 state 里面,等状态恢复后,从 state 状态里将其读出来,继续去消费、读取就可以了。
TDengine Connector 写入解析
1 数据提交写入流程
SeaTunnel 原生地支持两阶段提交的数据协助保障,具体的实现逻辑是借助一个数据协调器叫 Sink coordinator,还有 Sink Writer,writer 运行在不同的 worker上面,每一个 writer 独立完成事务的写入。
数据写入分成两步,第一步就是大家比较常见的两阶段提交,先做预提交,之后把自己的 commit 信息反馈到协调器,等所有 worker 把提交信息的全部反馈完以后,由统一由 coordinator 协调器来完成最后的事务写入。
当然也有更简单的写法,直接由 worker 完成写入以及 commit 操作,不属于两阶段提交的范畴。
2元数据的识别和注入

在 Sink 端,这是一条完整的真实的 TDengine insert 语句,包括 subtable,通过从抽象层的 SECAM rode 里面就可以直接提取到,因为 SeaTunnelRow 承载了一部分元数据的传输功能,所以从这里直接就能提取到。
第二部分就是 stable,需要在用户在配置文件中配置。但是 Supertable 下面的对应的 subtable 用户不需要配置和指定,导过来的字段中,tag 和 valve 混杂,在隐私的语句里需要分开完成,所以在这里也是 connector 从 TDengine 的 元数据里读取信息,做自动识别,从 SeaTunnelRow 中识别 tag 和 valve,并把它们安放在不同的位置上,完成一个具体的插入过程。
所以,只需要用户配置 stable 这一项。这里用到了一些元数据的注入工作,可以减少大家的配置复杂度。
另外,关于时区的配置,因为 TDengine 是时序数据库,导入导出场景下对于时区配置有着特别要求,我们针对这个场景做了一些时区参数配置,可以动态指定时区。
TDengine Connector 使用示例
下面展示一个 TDengine Connector 的使用示例,看看最终的效果。
我以在 TDengine 实例之间做数据传输为例。当然其他数据场景也是支持的,只需要换对应的 Source 插件和 Sink 插件即可。 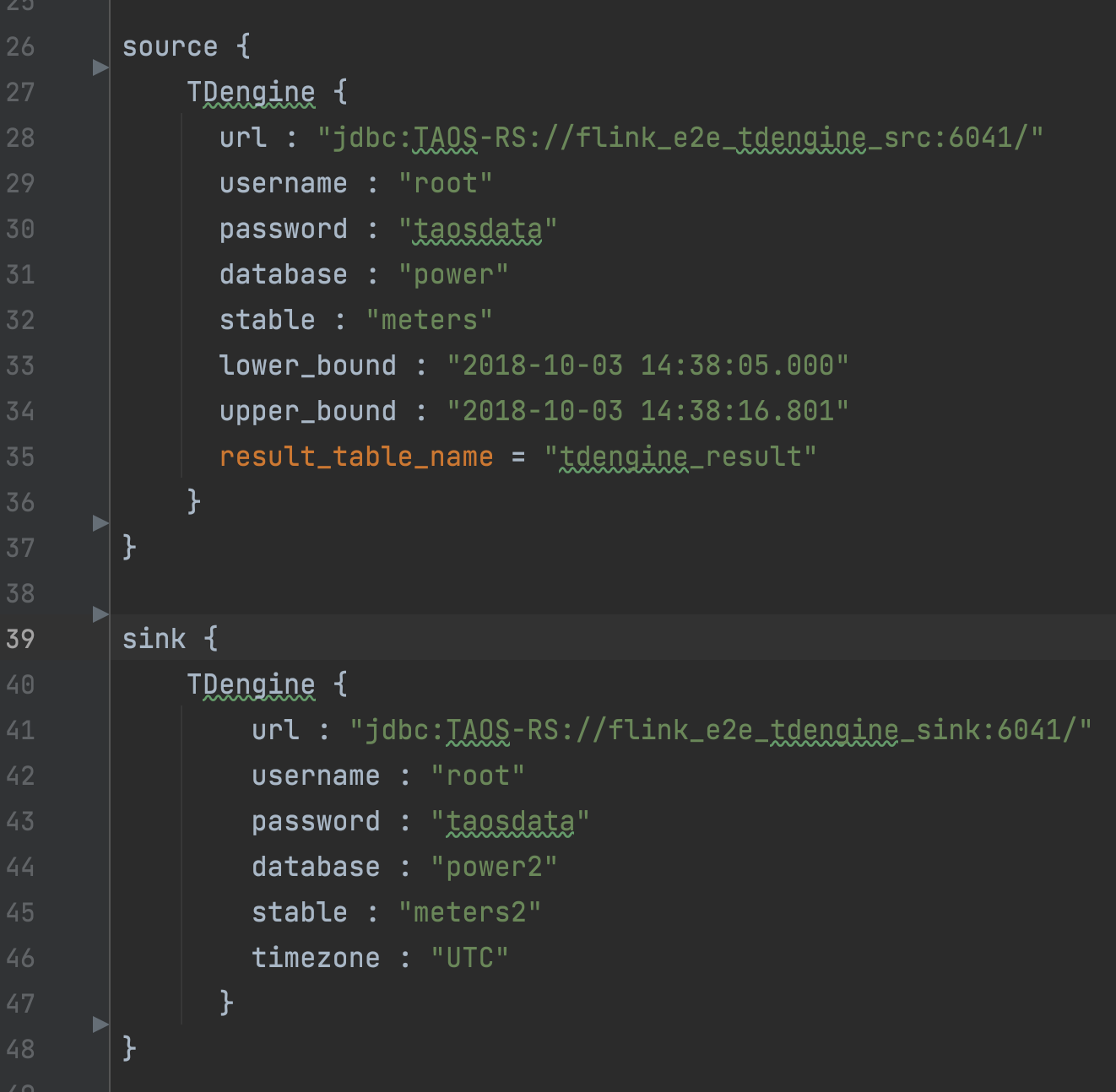
可以看到,Source 其实除了 URL username、password 基本参数以外,只需要配置一个 stable,就是你的表,以及它的上时间序列的上下界即可。
Reserve table name 是对应到如果有 transform 过程的话,需要用到配置,如果要是没有转换的过程,这一个参数配置也是不是必须的。Sink 端也是对应基本参数配置,只是多了一项 timezone,就是时区的配置。
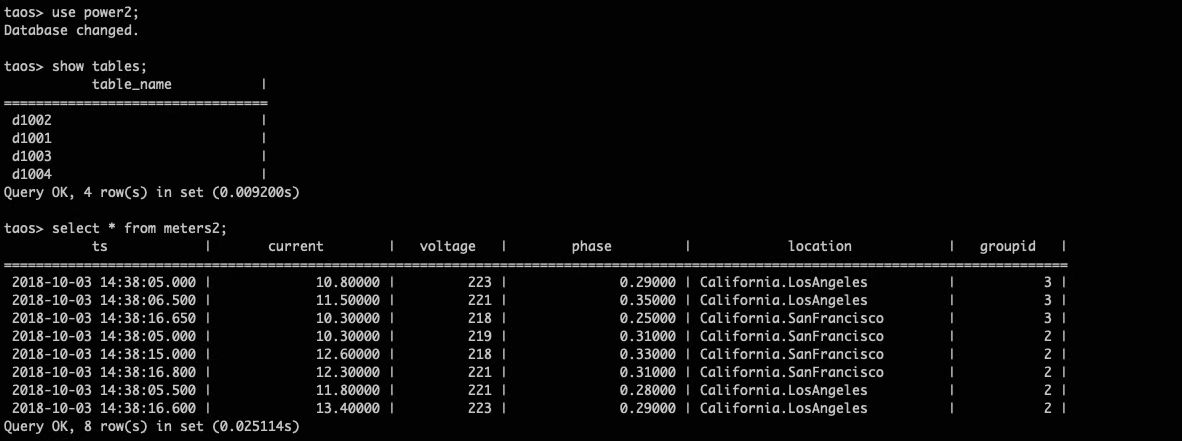 上图为导入、导出之后的效果图,对应的数据指标和 tag 都可以比较合理地安排在不同的位置上做同步。
上图为导入、导出之后的效果图,对应的数据指标和 tag 都可以比较合理地安排在不同的位置上做同步。
TDengine Connector 的下一步计划
● Source 端:
- 支持 streaming 数据集成(目前仅支持batch操作)
● Sink 端:
- 支持数据写入异常重试机制
- 支持数据批量写入(目前仅支持批量读取,单条写入)
如何参与贡献
最后跟大家简单分享一下,新同学怎么入手参与社区贡献。
● 寻找你感兴趣的 issue
- https://github.com/apache/incubator-seatunnel/issues/2828
- https://github.com/apache/incubator-seatunnel/issues/3018
- https://github.com/apache/incubator-seatunnel/issues?q=is:open+is:issue+label:"help+wanted"
● 参考贡献指南 * https://github.com/apache/incubator-seatunnel/issues/2828 * https://github.com/apache/incubator-seatunnel/pull/2995【贡献指南】 * https://github.com/apache/incubator-seatunnel/blob/dev/docs/en/contribution/setup.md 【编译指南】
● 新手教程
- 【SeaTunnel 连接器极简开发流程】
- 【新 API Connector 开发解析】
- 【Source 与 Sink API 设计解析】
● 参与讨论 & 寻求帮助
- 在邮件列表、Slack 中讨论
- 通过微信群沟通(如果没有加入请关注 SeaTunnel 公众号入群)
- 参与 PR Review 发表你的见解

本文由 白鲸开源科技 提供发布支持!