
我是韩山峰,来自金红叶纸业集团。今天,我将向大家介绍 Apache SeaTunnel 在我们金红叶纸业集团中的应用场景,包括我们为何选择 Apache SeaTunnel ,以及我们如何基于其提升我们内部的数据开发效率。
文|韩山峰 编辑整理| 曾辉
讲师介绍

韩山峰 金红叶纸业 数据分析师
01 产品选择历程
在我刚加入金红叶的时候,所有数据都在 Oracle 数据库中。在那时,我们用的是 Oracle 视图来做数仓。
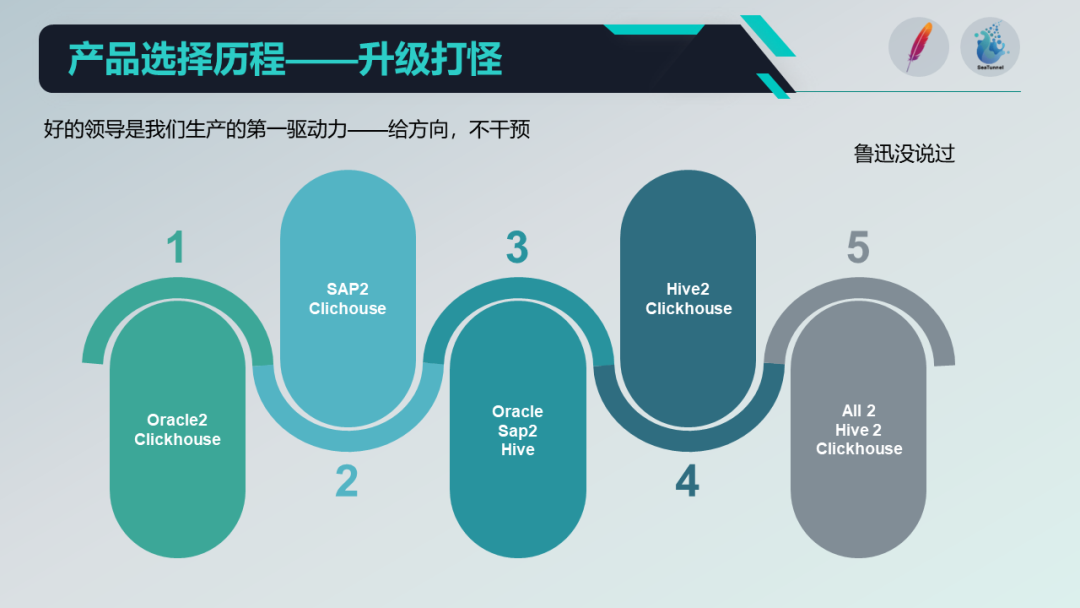
如果一个视图不能满足需求,我们就会创建另一个视图,如果两个视图还不能满足需求,我们就会再套一个视图。但随着时间的推移,这种方式的效率问题开始显现,于是我们开始寻找新的方案。
第一个任务是研究 Oracle 和 Clickhouse 之间的数据同步。这一阶段,我们的目标很简单,即直接将系统表数据推送到 Clickhouse,然后由 Clickhouse 直接做前端应用。当解决了 Oracle 到 Clickhouse 的数据同步问题后,我们开始进入第二个阶段。
第二阶段,我们开始处理 SAP 的数据。作为一个传统企业,我们的制造、营销及供应链生产,都依赖于 ERP 系统,特别是 SAP,这也给我们带来了数据输出的挑战。我们选择了使用SAP的RFC接口进行数据输出,并且很巧合的是我们在第一阶段使用的工具 Kettle 也支持这种方式。
第三阶段,我们规划使用 Hive 来建设我们的数仓。然而,由于 Kettle 本身存在的问题和限制,我们开始寻找新的工具,能够将我们的 Oracle 数据库和 SAP 接口的数据导入到 Hive,并在数仓中进行模型处理和数据清洗。
第四阶段,我们开始探索如何将清洗过的 Hiv e数据推送到 Clickhouse,因为我们的 BI、报表以及可视化应用,更多的是依赖于 Clickhouse 。我们在这一阶段探讨了如何打通整个数据生态的问题。
在这个过程中,我们评估了多种解决方案,包括商业解决方案和开源的 Apache SeaTunnel ,我还记得刚接触 Apache SeaTunnel 时,当时它的名字叫 “Waterdrop” 。
我们详细阅读了它在 GitHub上 的文档,进行了深入的代码分析,并最终决定基于 Apache SeaTunnel 来搭建我们的数据集成工具。
在定好工具之后,我们开始面临新的挑战。企业内部除了标准的业务系统外,我们还购买了一些 SaaS 服务。很多 SaaS 服务只给你一个客户端或者一个 Web 账号密码,获取想要的数据会有一些困难。
这就引出了我们的第五阶段,即如何将所有的数据通过一个工具集成到我们的平台中,然后通过我们的 Clickhouse 对外提供服务。这个过程对我们来说是艰难的,但我们最终实现了目标,提升了我们的数据开发效率。
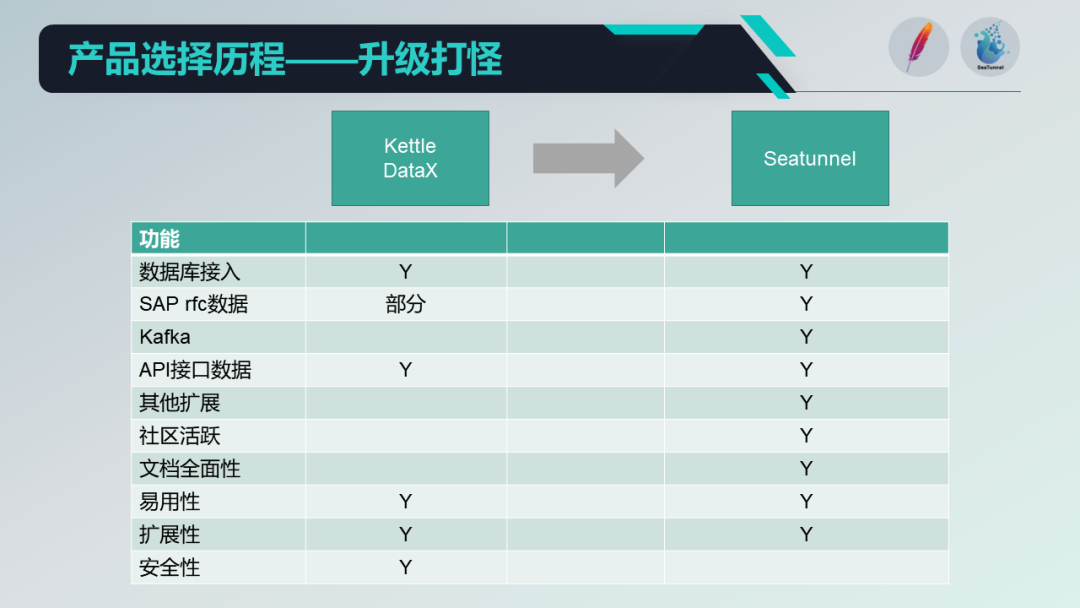
我们经历了五个阶段来选择并实施合适的数据产品。通过对不同产品的比较,从 Kettle 进行迭代升级到 SeaTunnel 。
我们列举了几个关键的步骤: 首先,我们处理的是传统的离线数据接入。其次,我们实现了通过 RFC 接口进行数据接入,这一步 Apache SeaTunnel 在原生形态下只部分支持。为了完整支持这一功能,我们研究了 SAP 文档和 Apache SeaTunnel 的源代码,对其进行了开发和优化。
在这个过程中,SeaTunnel 为我们技术团队提供了详细的文档,包括中英文版本。当我们遇到问题时,我们可以通过提交 Github 请求或 Slack、Apache SeaTunnel 的社区群来寻求解决。过程中配置文件和文档对于开发者来说相对容易理解,这也是我们选择Apache SeaTunnel的原因之一!
02 产品应用场景
在数据接入方面,我们主要有以下几个应用场景:

离线数据接入:这是我们最主要的应用场景,我们将各个业务系统的数据库和不同的库表通过 Apache SeaTunnel 同步到我们的 Hive 中,然后在 Hive 内部处理业务逻辑,再将处理后的数据输出到我们的 Clickhouse 中,最后通过前端的 BI 或报表工具对数据进行展示。
RFC数据接入:这是我们的另一个主要应用场景。在这个过程中。我们使用 SAP 的 RFC 接口进行数据接入,该接口是 SAP 提供的标准对外接口之一,同时提供 Java 和 Python 的实现。
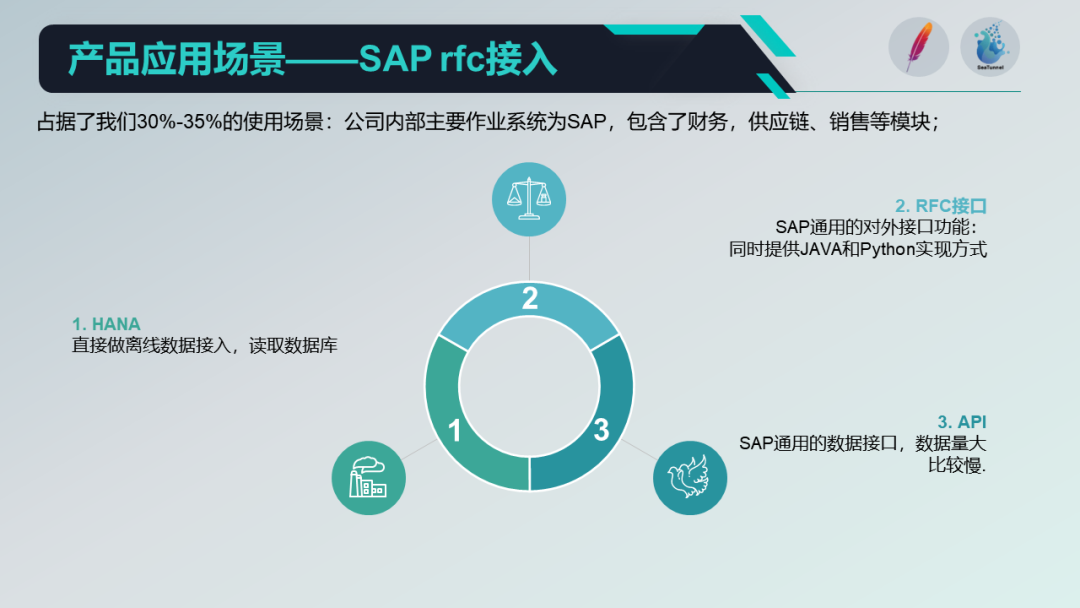
第三方数据接入:虽然这种场景在我们的应用中比重较小,我们会通过 HTTP 协议或 Kafka 协议接入这些数据,然后进行内部的数据分析。
03 开发效率提升
接下来跟大家介绍一下,我们团队在开发效率方面的提升,这么说吧!它基本上把我们算是彻底地变成了这种 “复制粘贴” 工程师了,所有的主题,都采用这种标准化的目录结构、标准化的模板去建造,然后分发分工处理;就是完全变成一个流水线的一个工作。
然后第二个就是说在“流水线”的过程中,我们有很多这种固定化的一些东西,也是一方面是内部的一个规范性的约束,一方面就是说我们也从开源的里边学了一些,学习到一些东西,然后把它用在我们这边。
当我们的团队第一次接触开源时,我们的态度主要是借鉴和应用。但是我们发现 SeaTunnel 这个活跃度高文档齐全的项目,我们就拿来使用。

在使用过程中,我们发现它确实能够解决我们公司内部,包括我们的数据团队内部的一些问题。在使用过程中,我们也发现了一些问题,这促使我们提出了 PR 并尝试反馈一些正向的建议。这种反馈其实也帮助了我们,所以我们也想一直在做一些对于社区来说是积极的反馈。
我们在2021年时使用的是1.0的版本,2.0的版本当时还没出来。我们在使用1.0的版本时,遇到了很多问题,到了2.0时代,支持的协议真的很多,有一些是我们非常需要的,比如 HTTP 这种协议。在我们内部的测试之后,我们发现这确实能极大地减轻我们的开发时间。
04 产品升级迭代
在我们刚开始的那个架构图中,我们实际上使用的是 Azkaban ,这是因为当时我们没有太多的时间去测试不同的产品,所以我们选择了最简单的 Azkaban 来做我们整个集群的资源调度工具。
但它也存在一些问题,比如它不能很好地管理我的各种脚本。

随着我们接入的主题越来越多,相关主题的依赖也变得越来越多。原来可能只有一两个主题相互之间可以解决,现在我们需要非常小心地调整各个依赖之间的调度时间。有的时候,可能突然出现数据量大的任务需要耗费一两个小时,那么接下来的任务可能就会执行失败。我们需要非常小心地处理各个依赖的调度。
然后,我们接触到了 Apache DolphinScheduler 这个工具,它基本上能够很好地解决我们的调度依赖问题和资源管理问题,我们的后续计划就是使用 DolphinScheduler 这个工具去替代当前的 Azkaban 。
最后,我想分享一本我最近阅读关于软件行业书籍中的一段话,它让我有很深的感触。这本书描述的是1960年代,那个时候还是真空管的年代,芯片还在初始阶段。
书中有一段话我觉得非常深刻,它说:芯片越简单,它所提供的可靠性和电力节省程度就越好。我觉得这也适用于我们的软件程序。如果我们的程序对用户来说足够简单,它的可靠性和它提供的功能就会越强大。
本文由 白鲸开源科技 提供发布支持!