CoNLL-2003 数据集包括 1,393 篇英文新闻文章和 909 篇德文新闻文章。总共包含4 个实体:PER(人员),LOC(位置),ORG(组织)和 MISC(其他,包括所有其他类型的实体)。
我们将查看英文数据。
1. 下载CoNLL-2003数据集
https://data.deepai.org/conll2003.zip
下载后解压你会发现有如下文件。

打开train.txt文件, 你会发现如下内容。
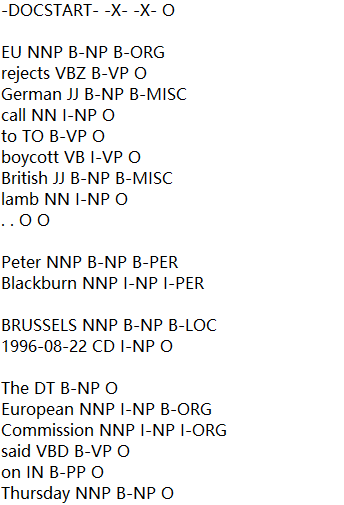
CoNLL-2003 数据文件包含由单个空格分隔的四列。每个单词都单独占一行,每个句子后面都有一个空行。每行的第一项是单词,第二项是词性 (POS) 标记,第三项是句法块标记,第四项是命名实体标记。块标签和命名实体标签的格式为 I-TYPE,这意味着该单词位于 TYPE 类型的短语内。仅当两个相同类型的短语紧随其后时,第二个短语的第一个单词才会带有标签 B-TYPE 以表明它开始一个新短语。带有标签 O 的单词不是短语的一部分。
2. 对数据预处理
数据文件夹中的 train.txt、valid.txt 和 test.txt 包含句子及其标签。我们只需要命名实体标签。我们将单词及其命名实体提取到一个数组中 - [ [‘EU’, ‘B-ORG’], [‘rejects’, ‘O’], [‘German’, ‘B-MISC’], [‘call’, ‘O’], [‘to’, ‘O’], [‘boycott’, ‘O’], [‘British’, ‘B-MISC’], [‘lamb’, ‘O’], [‘.’, ‘O’] ]。
下面代码是提取句子数组和对应句子的label数组.
import tensorflow as tf
import numpy as np
from constant.config import *
conll2003_path = "D:/ml/conll2003"
def load_file(path = "/train.txt"):
# Load the dataset
train_sentences = []
train_labels = []
with open(conll2003_path + path) as f:
sentence = []
labels = []
for line in f:
line = line.strip()
if line:
word, pos, chunk, label = line.split()
sentence.append(word)
labels.append(label)
else:
train_sentences.append(sentence)
train_labels.append(labels)
sentence = []
labels = []
return train_sentences, train_labels把句子中的词转为相应的index后,对每个句子进行预处理,比如小写化,固定没个句子的长度。如果句子长与最大长度,剪掉多余的。如果句子少于最大长度,补0. 最后把label数字化。
max_len =64
def preproces(word2idx, tag2idx, num_tags, train_sentences, train_labels):
# Convert sentences and labels to numerical sequences
X = [[word2idx[word.lower()] for word in sentence] for sentence in train_sentences]
X = tf.keras.preprocessing.sequence.pad_sequences(maxlen=max_len, sequences=X, padding="post", value=0)
y = [[tag2idx[tag] for tag in labels] for labels in train_labels]
y = tf.keras.preprocessing.sequence.pad_sequences(maxlen=max_len, sequences=y, padding="post", value=tag2idx["O"])
y = tf.keras.utils.to_categorical(y, num_tags)
return X, y取数据集,包含调用上面两个方法。取数据,把词转换为index,预处理,以及最后保存数据集。
def get_dataset():
# Load the dataset
train_sentences, train_labels = load_file("/train.txt")
valid_sentences, valid_labels = load_file("/valid.txt")
test_sentences, test_labels = load_file("/test.txt")
# Create vocabulary and tag dictionaries
all_sentencses = np.concatenate([train_sentences, valid_sentences,test_sentences ])
all_labels = np.concatenate([train_labels, valid_labels, test_labels])
vocab = set()
tags = set()
for sentence in all_sentencses:
for word in sentence:
vocab.add(word.lower())
# word2idx = {w: i + 1 for i, w in enumerate(vocab)}
word2idx = {}
if len(word2idx) == 0:
word2idx["PADDING_TOKEN"] = len(word2idx)
word2idx["UNKNOWN_TOKEN"] = len(word2idx)
for word in vocab:
word2idx[word] = len(word2idx)
for labels in all_labels:
for label in labels:
tags.add(label)
tag2idx = {t: i for i, t in enumerate(tags)}
save_dict(word2idx, nlp_ner_config.conll2003_word2idx)
save_dict(tag2idx, nlp_ner_config.conll2003_idx2Label)
num_words = len(word2idx) + 1
num_tags = len(tag2idx)
train_X, train_y = preproces(word2idx, tag2idx, num_tags, train_sentences, train_labels);
valid_X, valid_y = preproces(word2idx, tag2idx, num_tags, valid_sentences, valid_labels);
test_X, test_y = preproces(word2idx, tag2idx, num_tags, test_sentences, test_labels);
np.savez( nlp_ner_config.conll2003_DATASET, train_X = train_X, train_y = train_y, valid_X = valid_X, valid_y =valid_y , test_X =test_X, test_y= test_y)
return train_X, train_y, valid_X, valid_y , test_X, test_y保持预处理过的训练集,验证集以及测试集,为训练NER模型做准备。
np.savez(dataset_file, train_X=train_features, train_y=train_labels, valid_X=valid_features, valid_y=valid_labels, test_X=test_features,
test_y=test_labels)
至此你会有如下三个文件。
下面代码是load这些文件,保存文件,以及加载数据集
def load_dataset():
dataset = np.load(os.path.join(nlp_ner_config.conll2003_DATASET_PATH ,'dataset.npz'))
train_X = dataset['train_X']
train_y = dataset['train_y']
valid_X = dataset['valid_X']
valid_y = dataset['valid_y']
test_X = dataset['test_X']
test_y = dataset['test_y']
return train_X, train_y, valid_X, valid_y, test_X, test_y
def save_dict(dict, file_path):
import json
# Saving the dictionary to a file
with open(file_path, 'w') as f:
json.dump(dict, f)
def load_dict(path_file):
import json
# Loading the dictionary from the file
with open(path_file, 'r') as f:
loaded_dict = json.load(f)
return loaded_dict;
print(loaded_dict) # Output: {'key1': 'value1', 'key2': 'value2'}
写一个main方法测试一下代码吧
if __name__ == '__main__':
get_dataset()
train_X, train_y, valid_X, valid_y, test_X, test_y =load_dataset()
print(len(train_X))
print(len(train_y))
print(np.array(train_X).shape)
print(np.array(train_y).shape)输出结果是
14987
14987
(14987, 64)
(14987, 64, 9)
整个代码如下:
import tensorflow as tf
import numpy as np
from constant.config import *
conll2003_path = "D:/ml/conll2003"
def load_file(path = "/train.txt"):
# Load the dataset
train_sentences = []
train_labels = []
with open(conll2003_path + path) as f:
sentence = []
labels = []
for line in f:
line = line.strip()
if line:
word, pos, chunk, label = line.split()
sentence.append(word)
labels.append(label)
else:
train_sentences.append(sentence)
train_labels.append(labels)
sentence = []
labels = []
return train_sentences, train_labels
def preproces(word2idx, tag2idx, num_tags, train_sentences, train_labels):
# Convert sentences and labels to numerical sequences
X = [[word2idx[word.lower()] for word in sentence] for sentence in train_sentences]
X = tf.keras.preprocessing.sequence.pad_sequences(maxlen=max_len, sequences=X, padding="post", value=0)
y = [[tag2idx[tag] for tag in labels] for labels in train_labels]
y = tf.keras.preprocessing.sequence.pad_sequences(maxlen=max_len, sequences=y, padding="post", value=tag2idx["O"])
y = tf.keras.utils.to_categorical(y, num_tags)
return X, y
def get_dataset():
# Load the dataset
train_sentences, train_labels = load_file("/train.txt")
valid_sentences, valid_labels = load_file("/valid.txt")
test_sentences, test_labels = load_file("/test.txt")
# Create vocabulary and tag dictionaries
all_sentencses = np.concatenate([train_sentences, valid_sentences,test_sentences ])
all_labels = np.concatenate([train_labels, valid_labels, test_labels])
vocab = set()
tags = set()
for sentence in all_sentencses:
for word in sentence:
vocab.add(word.lower())
for labels in all_labels:
for label in labels:
tags.add(label)
word2idx = {w: i + 1 for i, w in enumerate(vocab)}
tag2idx = {t: i for i, t in enumerate(tags)}
save_dict(word2idx, nlp_ner_config.conll2003_word2idx)
save_dict(tag2idx, nlp_ner_config.conll2003_idx2Label)
num_words = len(word2idx) + 1
num_tags = len(tag2idx)
train_X, train_y = preproces(word2idx, tag2idx, num_tags, train_sentences, train_labels);
valid_X, valid_y = preproces(word2idx, tag2idx, num_tags, valid_sentences, valid_labels);
test_X, test_y = preproces(word2idx, tag2idx, num_tags, test_sentences, test_labels);
np.savez( nlp_ner_config.conll2003_DATASET, train_X = train_X, train_y = train_y, valid_X = valid_X, valid_y =valid_y , test_X =test_X, test_y= test_y)
return train_X, train_y, valid_X, valid_y , test_X, test_y
def load_dataset():
dataset = np.load(os.path.join(nlp_ner_config.conll2003_DATASET_PATH ,'dataset.npz'))
train_X = dataset['train_X']
train_y = dataset['train_y']
valid_X = dataset['valid_X']
valid_y = dataset['valid_y']
test_X = dataset['test_X']
test_y = dataset['test_y']
return train_X, train_y, valid_X, valid_y, test_X, test_y
max_len =64
def save_dict(dict, file_path):
import json
# Saving the dictionary to a file
with open(file_path, 'w') as f:
json.dump(dict, f)
def load_dict(path_file):
import json
# Loading the dictionary from the file
with open(path_file, 'r') as f:
loaded_dict = json.load(f)
return loaded_dict;
print(loaded_dict) # Output: {'key1': 'value1', 'key2': 'value2'}
if __name__ == '__main__':
get_dataset()
train_X, train_y, valid_X, valid_y, test_X, test_y =load_dataset()
print(len(train_X))
print(len(train_y))
print(np.array(train_X).shape)
print(np.array(train_y).shape)