1. 什么是LSTM
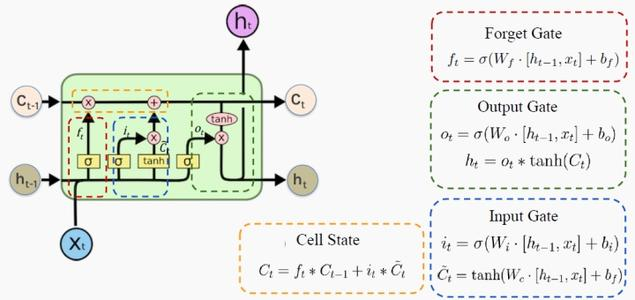
长短期记忆网络 LSTM(long short-term memory)是 RNN 的一种变体,其核心概念在于细胞状态以及“门”结构。细胞状态相当于信息传输的路径,让信息能在序列连中传递下去。你可以将其看作网络的“记忆”。理论上讲,细胞状态能够将序列处理过程中的相关信息一直传递下去。因此,即使是较早时间步长的信息也能携带到较后时间步长的细胞中来,这克服了短时记忆的影响。信息的添加和移除我们通过“门”结构来实现,“门”结构在训练过程中会去学习该保存或遗忘哪些信息。

2. 实验代码
2.1. 搭建一个只有一层RNN和Dense网络的模型。
2.2. 验证LSTM里的逻辑
假设我的输入数据是x = [1,0],
kernel = [[[2, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0],
[1, 1, 0, 1, 1, 0, 0, 1, 1 ,0, 0, 0],]]
recurrent_kernel = [[1, 0, 0, 1, 2,1,0,1,2,0,1,0],
[1, 1, 0, 0, 2,1,0,1,2,2,0,0],
[1, 0, 1, 2, 0,1,0,1,1,0,1,0]]
biase = [3, 1, 0, 1, 1,0,0,1,0,2,0.0,0]
通过下面手算,h的结果是[0, 4,1], c 的结果是[0,4,1]. 注意无激活函数。

代码验证上面的结果
def change_weight():
# Create a simple Dense layer
lstm_layer = LSTM(units=3, input_shape=(3, 2), activation=None, recurrent_activation=None, return_sequences=True,
return_state= True)
# Simulate input data (batch size of 1 for demonstration)
input_data = np.array([
[[1.0, 2], [2, 3], [3, 4]],
[[5, 6], [6, 7], [7, 8]],
[[9, 10], [10, 11], [11, 12]]
])
# Pass the input data through the layer to initialize the weights and biases
lstm_layer(input_data)
kernel, recurrent_kernel, biases = lstm_layer.get_weights()
# Print the initial weights and biases
print("recurrent_kernel:", recurrent_kernel, recurrent_kernel.shape ) # (3,3)
print('kernal:',kernel, kernel.shape) #(2,3)
print('biase: ',biases , biases.shape) # (3)
kernel = np.array([[2, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0],
[1, 1, 0, 1, 1, 0, 0, 1, 1 ,0, 0, 0],])
recurrent_kernel = np.array([[1, 0, 0, 1, 2,1,0,1,2,0,1,0],
[1, 1, 0, 0, 2,1,0,1,2,2,0,0],
[1, 0, 1, 2, 0,1,0,1,1,0,1,0]])
biases = np.array([3, 1, 0, 1, 1,0,0,1,0,2,0.0,0])
lstm_layer.set_weights([kernel, recurrent_kernel, biases])
print(lstm_layer.get_weights())
# test_data = np.array([
# [[1.0, 3], [1, 1], [2, 3]]
# ])
test_data = np.array([
[[1,0.0]]
])
output, memory_state, carry_state = lstm_layer(test_data)
print(output)
print(memory_state)
print(carry_state)
if __name__ == '__main__':
change_weight()执行结果:
recurrent_kernel: [[-0.36744034 -0.11181469 -0.10642298 0.5450207 -0.30208975 0.5405432
0.09643812 -0.14983998 0.1859854 0.2336958 -0.16187981 0.11621032]
[ 0.07727922 -0.226477 0.1491096 -0.03933501 0.31236103 -0.12963092
0.10522162 -0.4815724 -0.2093935 0.34740582 -0.60979587 -0.15877807]
[ 0.15371156 0.01244636 -0.09840634 -0.32093546 0.06523462 0.18934932
0.38859126 -0.3261706 -0.05138849 0.42713478 0.49390993 0.37013963]] (3, 12)
kernal: [[-0.47606698 -0.43589187 -0.5371355 -0.07337284 0.30526626 -0.18241835
-0.03675252 0.2873094 0.33218485 0.24838251 0.17765659 0.4312396 ]
[ 0.4007727 0.41280174 0.40750778 -0.6245315 0.6382301 0.42889225
0.11961156 -0.6021105 -0.43556038 0.39798307 0.6390712 0.16719025]] (2, 12)
biase: [0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0.] (12,)
[array([[2., 1., 1., 0., 0., 0., 0., 1., 1., 0., 1., 0.],
[1., 1., 0., 1., 1., 0., 0., 1., 1., 0., 0., 0.]], dtype=float32), array([[1., 0., 0., 1., 2., 1., 0., 1., 2., 0., 1., 0.],
[1., 1., 0., 0., 2., 1., 0., 1., 2., 2., 0., 0.],
[1., 0., 1., 2., 0., 1., 0., 1., 1., 0., 1., 0.]], dtype=float32), array([3., 1., 0., 1., 1., 0., 0., 1., 0., 2., 0., 0.], dtype=float32)]
tf.Tensor([[[0. 4. 0.]]], shape=(1, 1, 3), dtype=float32)
tf.Tensor([[0. 4. 0.]], shape=(1, 3), dtype=float32)
tf.Tensor([[0. 4. 1.]], shape=(1, 3), dtype=float32)可以看出h=[0,4,0], c=[0,4,1]