推荐:使用 NSDT场景编辑器 助你快速搭建可编辑的3D应用场景
我们都知道,GAN在生成非结构化合成数据(如图像和文本)方面越来越受欢迎。然而,在使用GAN生成合成表格数据方面所做的工作很少。合成数据具有许多好处,包括其在机器学习应用程序、数据隐私、数据分析和数据增强中的使用。只有少数模型可用于生成合成表格数据,CTGAN(条件表格生成对抗网络)就是其中之一。与其他 GAN 一样,它使用生成器和鉴别器神经网络来创建与真实数据具有相似统计属性的合成数据。CTGAN可以保留真实数据的底层结构,包括列之间的相关性。CTGAN的额外好处包括通过特定于模式的规范化来增强训练过程,一些架构更改,以及通过使用条件生成器和采样训练来解决数据不平衡问题。
在这篇博文中,我使用CTGAN根据从Kaggle收集的信用分析数据集生成合成数据。
CTGAN的优点
- 生成与实际数据具有类似统计属性的合成表格数据,包括不同列之间的相关性。
- 保留真实数据的底层结构。
- CTGAN生成的合成数据可用于各种应用,例如数据增强,数据隐私和数据分析。
- 可以处理连续、离散和分类数据。
CTGAN的缺点
- CTGAN需要大量的真实表格数据来训练模型并生成与真实数据具有相似统计属性的合成数据。
- CTGAN是计算密集型的,可能需要大量的计算资源。
- CTGAN生成的合成数据的质量可能会有所不同,具体取决于用于训练模型的真实数据的质量。
调整CTGAN
与所有其他机器学习模型一样,CTGAN在调优时表现更好。在调整CTGAN时需要考虑多个参数。但是,对于此演示,我使用了“ctgan 库”附带的所有默认参数:
- 纪元:生成器和鉴别器网络在数据集上训练的次数。
- 学习率:模型在训练期间调整权重的速率。
- 批量大小:每次训练迭代中使用的样本数。
- 生成器和鉴别器网络大小。
- 优化算法的选择。
CTGAN还考虑了超参数,例如潜在空间的维数,生成器和判别器网络中的层数以及每层中使用的激活函数。参数和超参数的选择会影响生成的合成数据的性能和质量。
CTGAN的验证
CTGAN的验证是棘手的,因为它存在局限性,例如难以评估生成的合成数据的质量,特别是在涉及表格数据时。尽管有一些指标可用于评估真实数据和合成数据之间的相似性,但确定合成数据是否准确表示真实数据中的基本模式和关系仍然具有挑战性。此外,CTGAN容易受到过度拟合的影响,并且可以产生与训练数据过于相似的合成数据,这可能会限制它们泛化到新数据的能力。
一些常见的验证技术包括:
- 统计测试:比较生成数据和真实数据的统计属性。例如,使用相关性分析、柯尔莫哥罗夫-斯米尔诺夫检验、安德森-达林检验和卡方检验等检验来比较生成的数据和真实数据的分布。
- 可视化:通过绘制直方图、散点图或热图来可视化异同。
- 应用程序测试:通过在实际应用程序中使用合成数据,查看其性能是否与真实数据相似。
个案研究
关于信用分析数据
信用分析数据包含连续和离散/分类格式的客户数据。出于演示目的,我通过删除具有 null 值的行并删除本演示不需要的几列来预处理数据。由于计算资源的限制,运行所有数据和所有列将需要大量的计算能力,而我没有。以下是连续变量和分类变量的列列表(离散值,如子变量计数 (CNT_CHINDREN) 被视为分类变量):
分类变量:
TARGET
NAME_CONTRACT_TYPE
CODE_GENDER
FLAG_OWN_CAR
FLAG_OWN_REALTY
CNT_CHILDREN连续变量:
AMT_INCOME_TOTAL
AMT_CREDIT
AMT_ANNUITY
AMT_GOODS_PRICE生成模型需要大量干净的数据来训练以获得更好的结果。但是,由于计算能力的限制,我从超过 10,000 行的真实数据中只选择了 9,993 行(正好是 300,000 行)进行本演示。虽然这个数字可能被认为相对较小,但对于本演示的目的来说应该足够了。
真实数据的位置:
生成的合成数据的位置:

信用分析数据 |图片来源:作者
结果
我生成了 10k(确切地说是 9997)合成数据点,并将它们与真实数据进行了比较。结果看起来不错,尽管仍有改进的潜力。在我的分析中,我使用了默认参数,其中“relu”作为激活函数和 3000 个 epoch。增加纪元的数量应该可以更好地生成类似真实的合成数据。生成器和鉴别器损失看起来也不错,损耗越低,表示合成数据和真实数据之间的相似性越近:

发生器和鉴别器损耗 |图片来源:作者
绝对对数平均值和标准差图中沿对角线的点表示生成的数据质量良好。

数值数据的绝对对数平均值和标准差 |图片来源:作者
下图中连续列的累积总和并不完全重叠,但它们很接近,这表明合成数据的生成良好且没有过度拟合。分类/离散数据的重叠表明生成的合成数据接近真实。进一步的统计分析见下图:
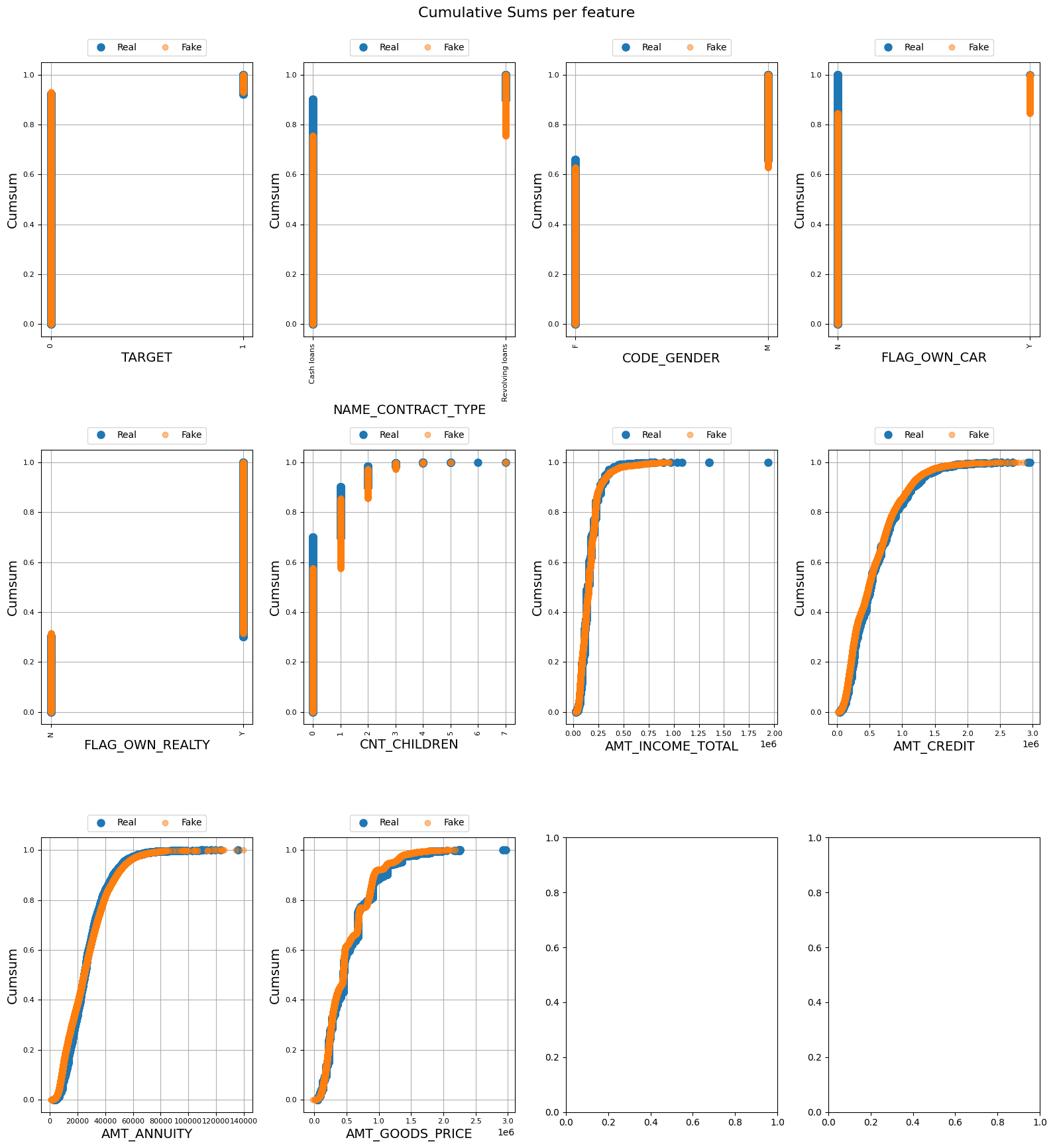
每个要素的累计总和 |图片来源:作者
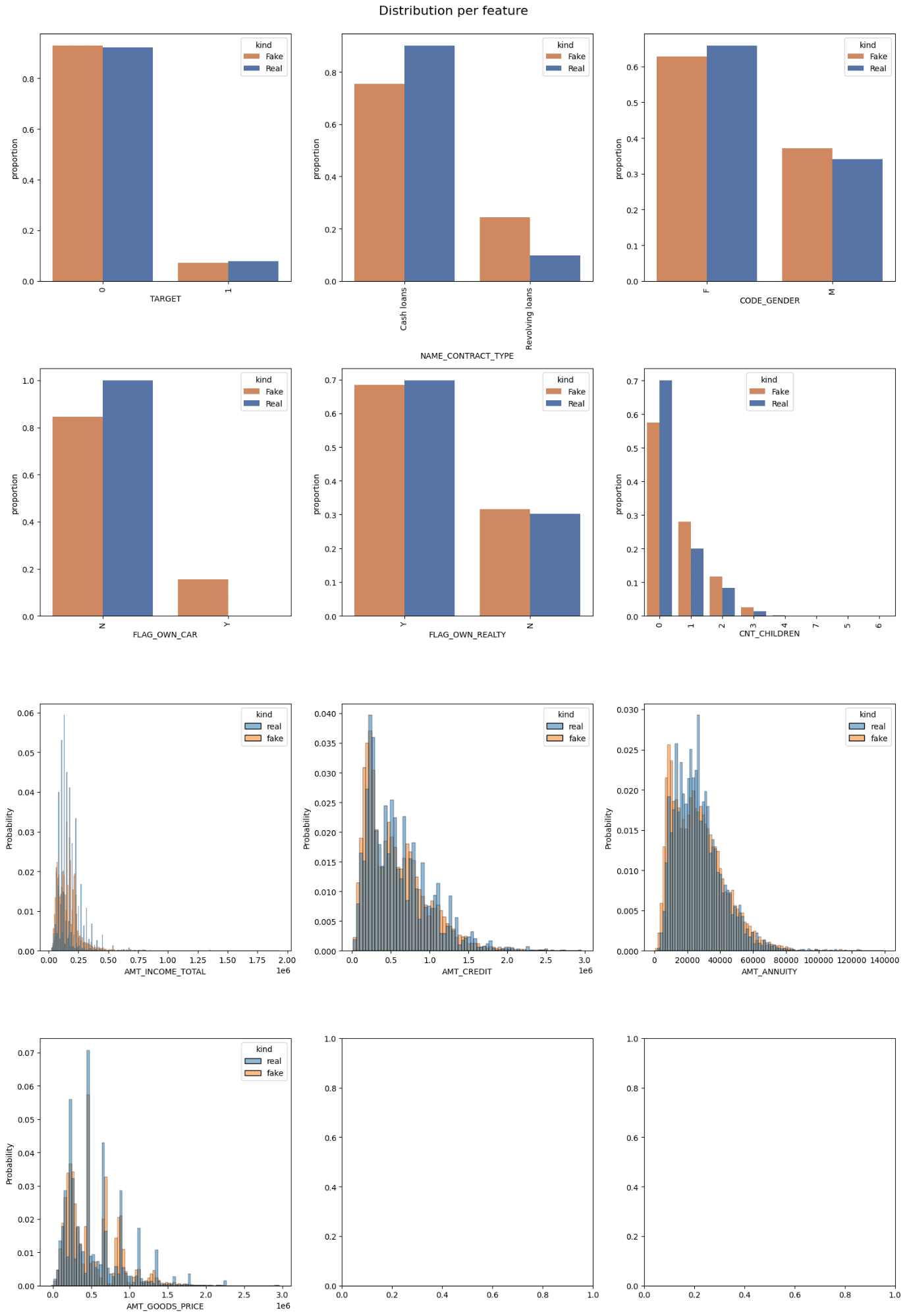
功能分布|图片来源:作者

特征分布 |图片来源:作者
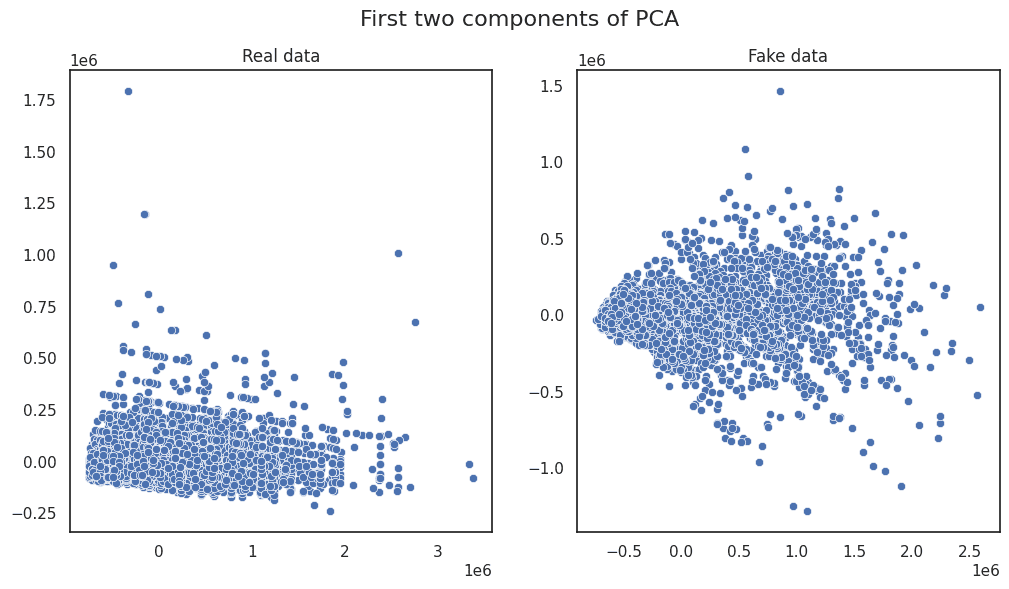
主成分分析 |图片来源:作者
以下关联图显示了变量之间的明显相关性。重要的是要注意,即使经过彻底的微调,真实数据和合成数据之间的属性也可能存在差异。这些差异实际上是有益的,因为它们可能会揭示数据集中可用于创建新解决方案的隐藏属性。据观察,增加纪元数可以提高合成数据的质量。
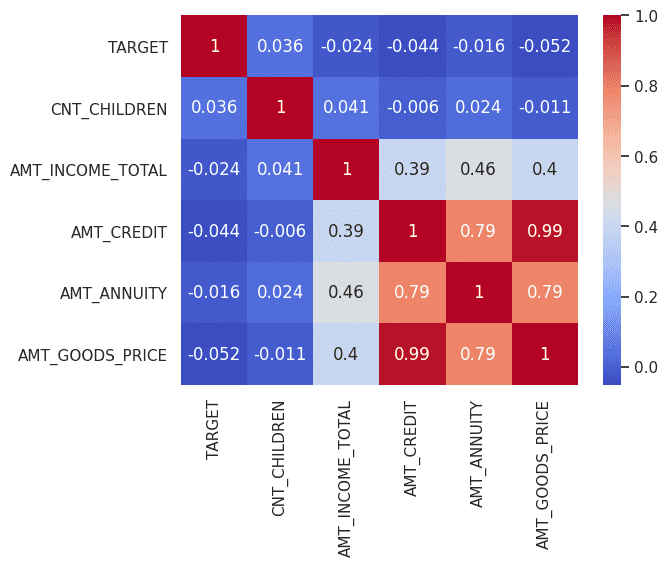
变量之间的相关性(真实数据) |图片来源:作者
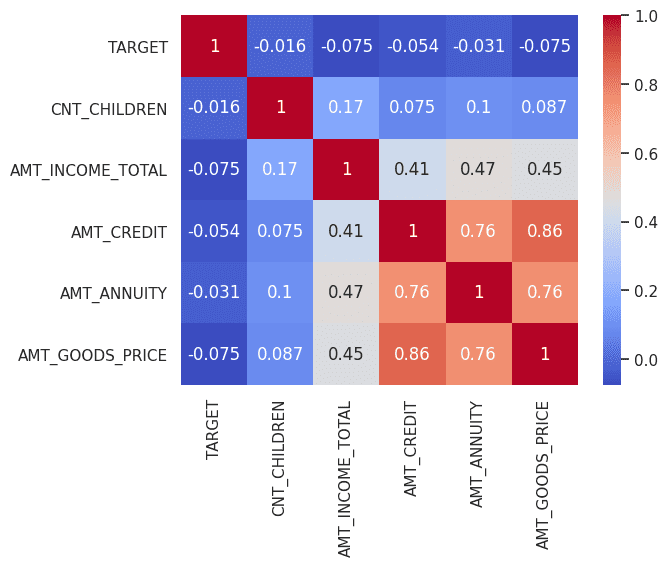
变量之间的相关性(合成数据) |图片来源:作者
样本数据和实际数据的汇总统计似乎也令人满意。
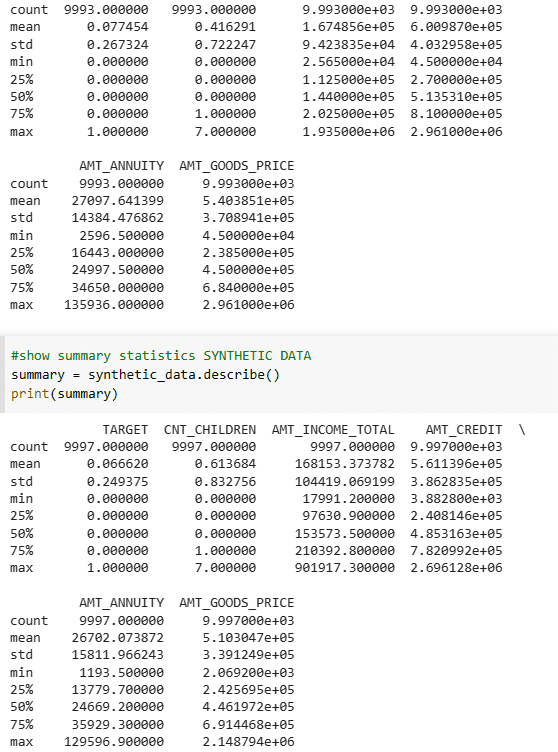
真实数据和合成数据的汇总统计 |图片来源:作者
Python代码
# Install CTGAN
!pip install ctgan
# Install table evaluator to analyze generated synthetic data
!pip install table_evaluator
# Import libraries
import torch
import pandas as pd
import seaborn as sns
import torch.nn as nn
from ctgan import CTGAN
from ctgan.synthesizers.ctgan import Generator
# Import training Data
data = pd.read_csv("./application_data_edited_2.csv")
# Declare Categorical Columns
categorical_features = [
"TARGET",
"NAME_CONTRACT_TYPE",
"CODE_GENDER",
"FLAG_OWN_CAR",
"FLAG_OWN_REALTY",
"CNT_CHILDREN",
]
# Declare Continuous Columns
continuous_cols = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]
# Train Model
from ctgan import CTGAN
ctgan = CTGAN(verbose=True)
ctgan.fit(data, categorical_features, epochs=100000)
# Generate synthetic_data
synthetic_data = ctgan.sample(10000)
# Analyze Synthetic Data
from table_evaluator import TableEvaluator
print(data.shape, synthetic_data.shape)
table_evaluator = TableEvaluator(data, synthetic_data, cat_cols=categorical_features)
table_evaluator.visual_evaluation()
# compute the correlation matrix
corr = synthetic_data.corr()
# plot the heatmap
sns.heatmap(corr, annot=True, cmap="coolwarm")
# show summary statistics SYNTHETIC DATA
summary = synthetic_data.describe()
print(summary)
结论
CTGAN的训练过程有望收敛到生成的合成数据与真实数据无法区分的程度。然而,在现实中,不能保证趋同。有几个因素会影响CTGAN的收敛性,包括超参数的选择、数据的复杂性和模型的架构。此外,训练过程的不稳定性可能导致模式崩溃,其中生成器仅生成一组有限的相似样本,而不是探索数据分布的全部多样性。