欢迎大家关注我的公众号【老周聊架构】,Java后端主流技术栈的原理、源码分析、架构以及各种互联网高并发、高性能、高可用的解决方案。
一、概念
1、零拷贝
根据wikipedia中介绍:
“Zero-copy” describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
翻译中文则是:
“零拷贝”描述了计算机操作,其中CPU不执行将数据从一个存储区复制到另一个存储区的任务。通过网络传输文件时,通常用于节省CPU周期和内存带宽。
2、广义狭义之分
从上面的概念不难发现零拷贝的核心是CPU不执行将数据从一个存储区复制到另一个存储区的任务。
可能你会说,那零拷贝是不是0次调用CPU消耗资源啊?既对也不对,为什么这样说呢?
实际上,零拷贝有广义和狭义之分。
2.1 广义零拷贝
能减少拷贝次数,减少不必要的数据拷贝,就算作“零拷贝”。
这是目前,对零拷贝最为广泛的定义,我们需要知道的是,这是广义上的零拷贝,并不是操作系统意义上的零拷贝。
2.2 狭义零拷贝
Linux 2.4 内核新增 sendfile 系统调用,提供了零拷贝。磁盘数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer(socket buffer),无需 CPU 拷贝。这是真正操作系统意义上的零拷贝(也就是狭义零拷贝)。
等等我,老周,这就开车了吗?sendfile、DMA 又是啥玩意啊? 别着急,老周等下马上就给你一一道来。
3、Linux I/O 机制
介绍 DMA 之前,我们先来了解下 Linux I/O 机制。
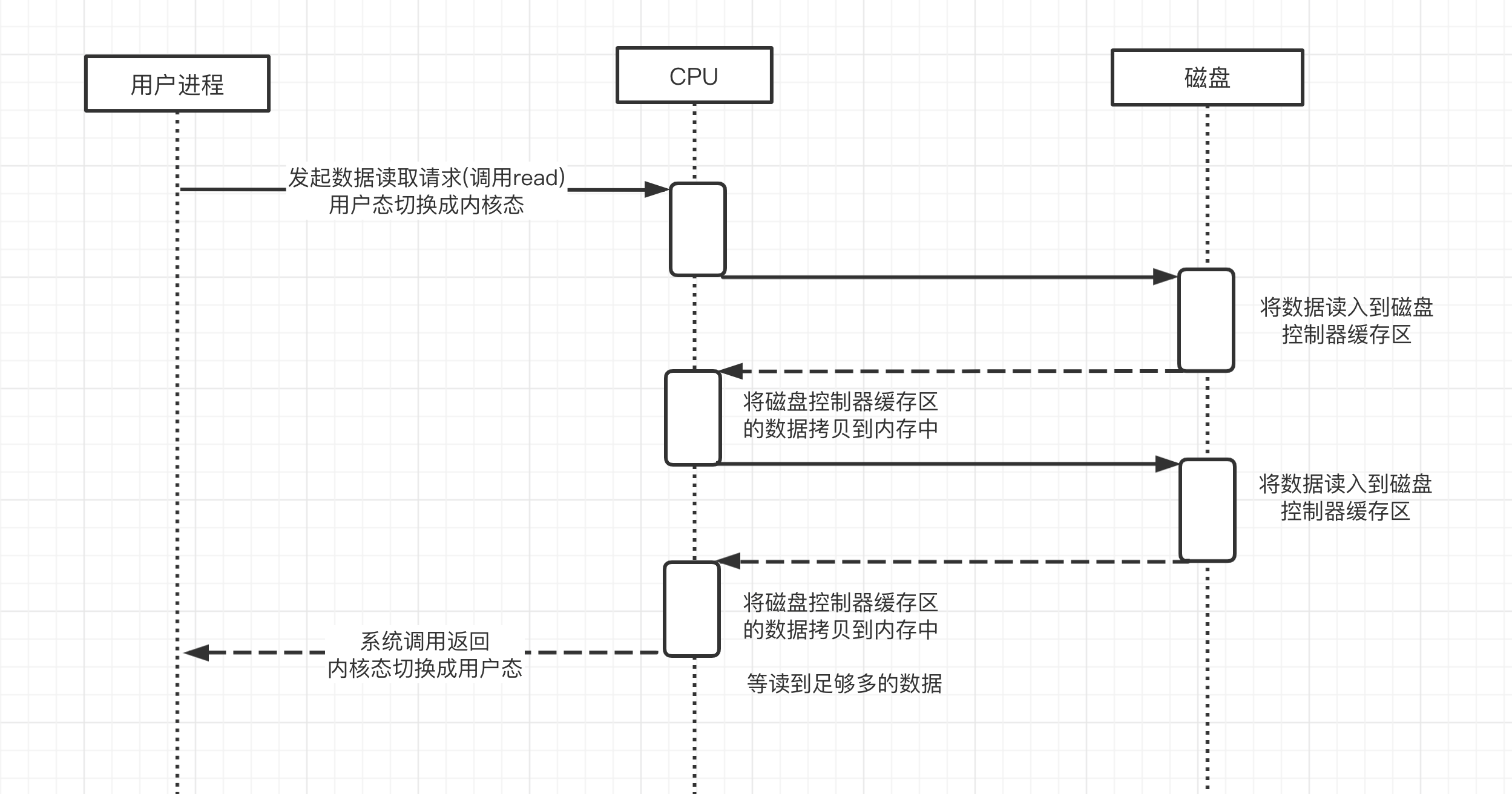
用户进程需要读取磁盘数据,需要CPU中断,发起IO请求,每次的IO中断,都带来CPU的上下文切换。
3.1 DMA
为了解决CPU的上下文切换,聪明的程序员们提出了 DMA(Direct Memory Access,直接内存存取),是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。通俗点理解,就是让硬件可以跳过CPU的调度,直接访问主内存。
下面请看老周画的图,看完你心里就一目了然了。
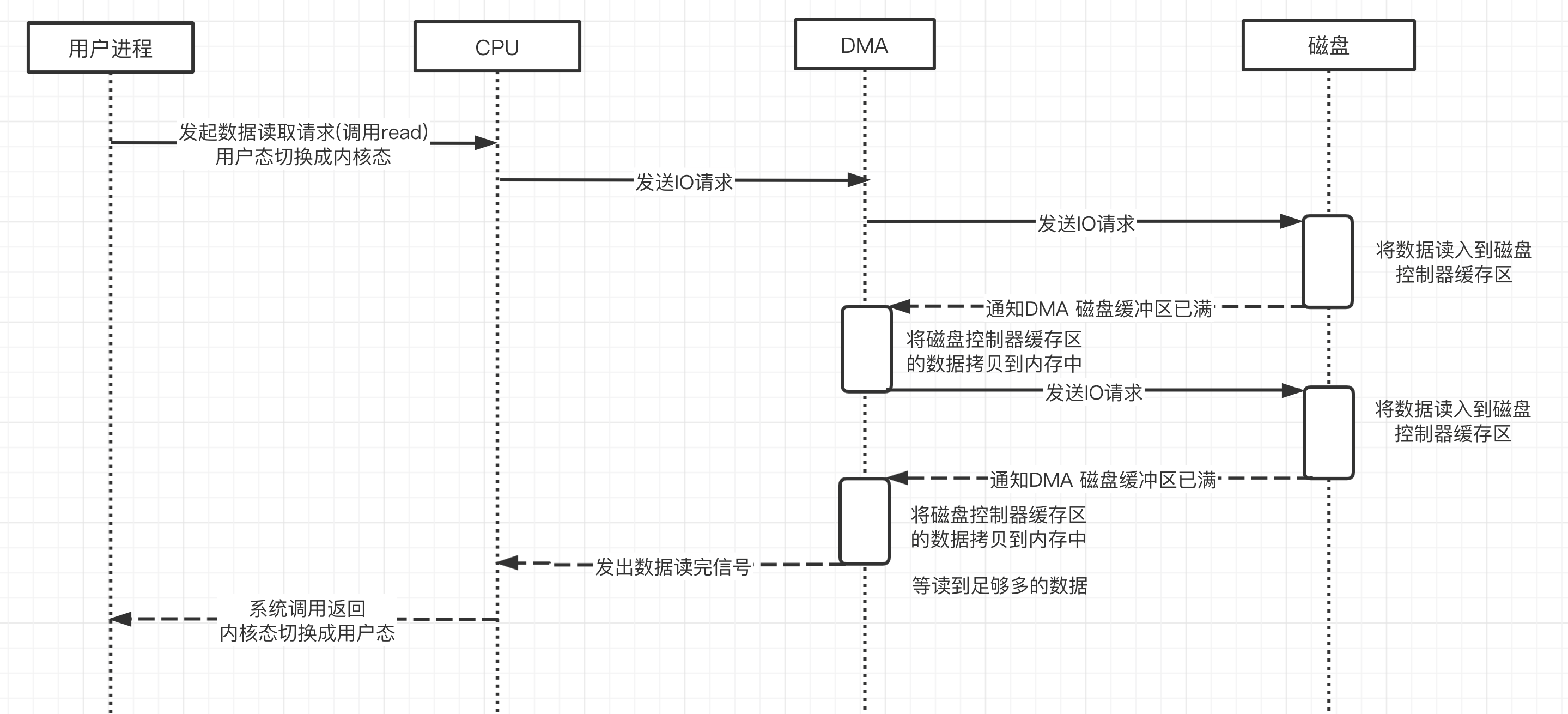
DMA 控制器,接管了数据读写请求,减少 CPU 的负担。这样一来,CPU 能高效工作了。
现代硬盘基本都支持 DMA。
比如我们常见的磁盘控制器、显卡、网卡、声卡都是支持 DMA 的,可以说 DMA 已经彻底融入我们的计算机世界了。
3.2 Linux IO 流程
实际因此 IO 读取,涉及两个过程:
- DMA 等待数据准备好,把磁盘数据读取到操作系统内核缓冲区;
- 用户进程,将内核缓冲区的数据 copy 到用户空间。
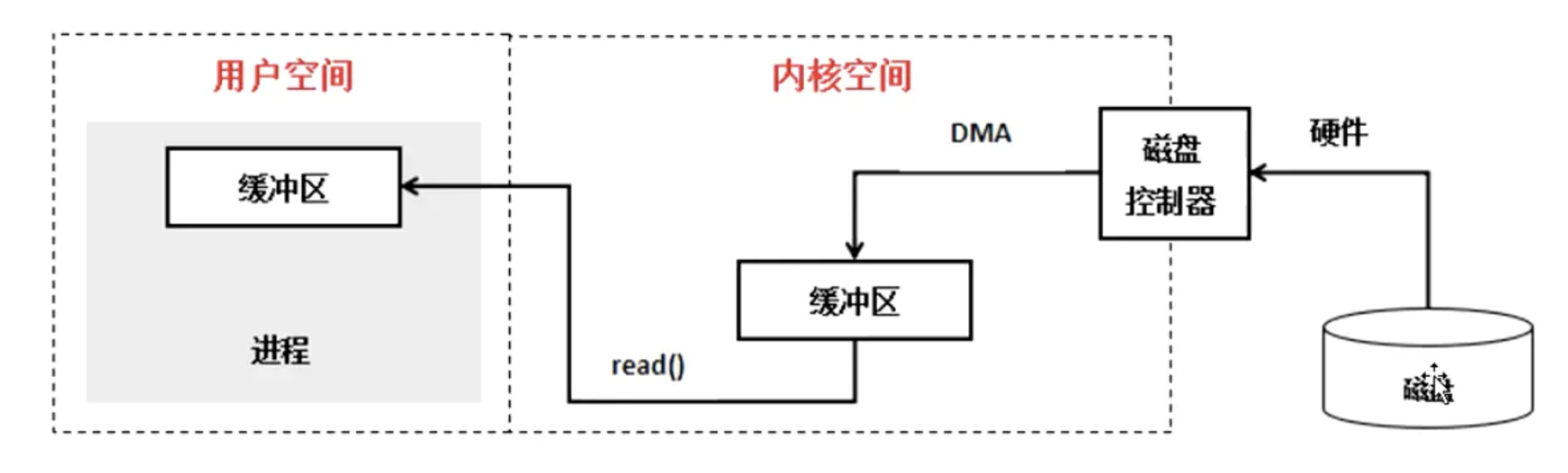
了解完 DMA 以及 Linux I/O 流程,相信你对 Linux I/O 机制有个大致的脉络了,但你可能会问,了解完这些,跟我们题目的零拷贝技术有啥关联么?有的,让我们进入下一节来说道说道。
二、传统 IO 的劣势
我们刚学 Java 的时候,都会学 IO 和 网络编程,最常见的就是写个聊天程序或是群聊。
我们来写个简单的,代码如下:
File file = new File("index.html");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
byte[] arr = new byte[(int) file.length()];
raf.read(arr);
Socket socket = new ServerSocket(8080).accept();
socket.getOutputStream().write(arr);
服务端读取 html 里的内容后变成字节数组,然后监听 8080 端口,接收请求处理,将 html 里的字节流写到 socket 中,那么,我们调用read、write这两个方法,在 OS 底层发生了什么呢?
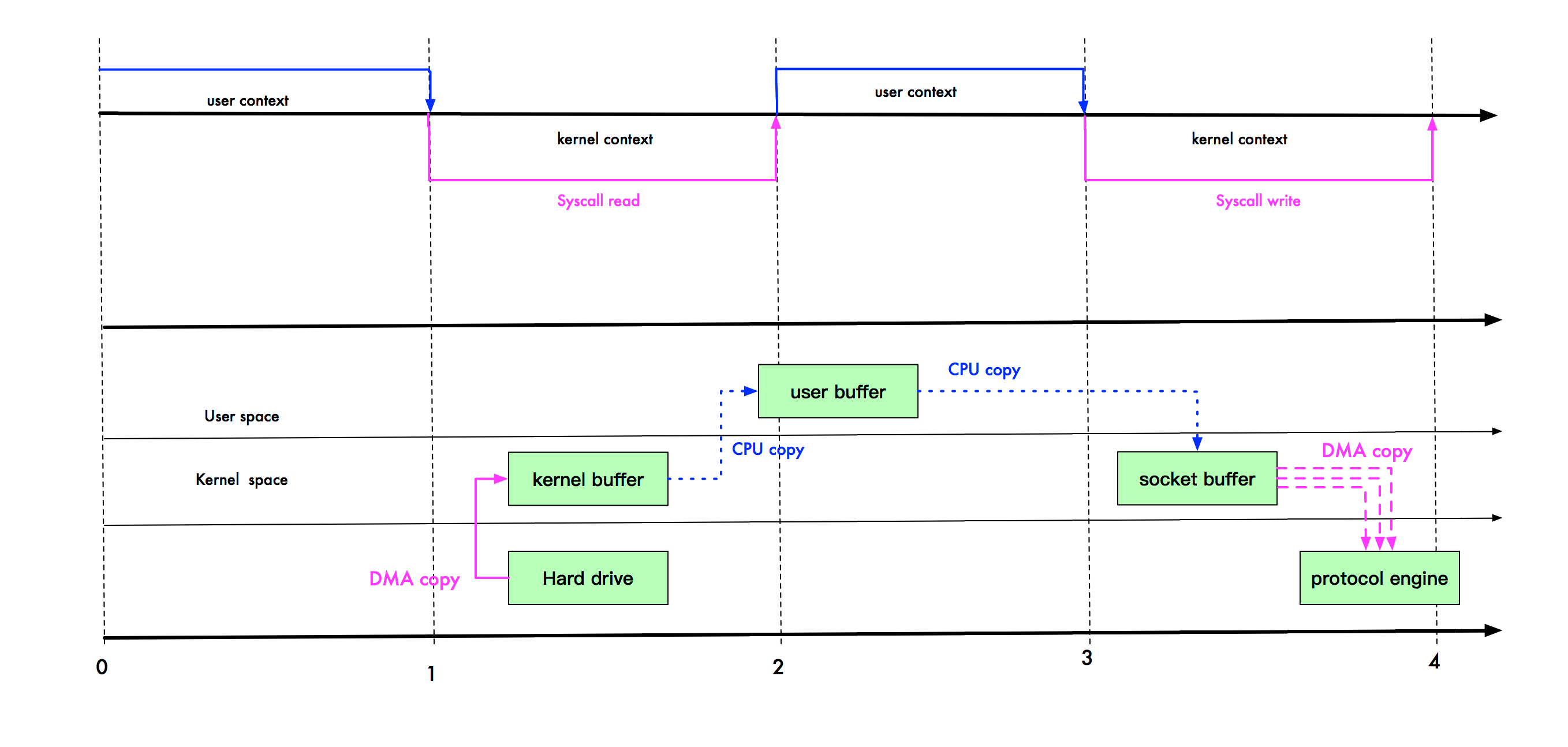
上图中,上半部分表示用户态和内核态的上下文切换。下半部分表示数据复制操作。下面说说它们的步骤:
- read 调用导致用户态到内核态的一次变化,同时,第一次复制开始:DMA(Direct Memory Access,直接内存存取,即不使用 CPU 拷贝数据到内存,而是 DMA 引擎传输数据到内存)引擎从磁盘读取 index.html 文件,并将数据放入到内核缓冲区。
- 发生第二次数据拷贝,即:将内核缓冲区的数据拷贝到用户缓冲区,同时,发生了一次用内核态到用户态的上下文切换。
- 发生第三次数据拷贝,我们调用 write 方法,系统将用户缓冲区的数据拷贝到 socket 缓冲区。此时,又发生了一次用户态到内核态的上下文切换。
- 第四次拷贝,数据异步的从 socket 缓冲区,使用 DMA 引擎拷贝到网络协议引擎。这一段,不需要进行上下文切换。
- write 方法返回,再次从内核态切换到用户态。
你也看到了,是不是感觉复制拷贝以及上下文切换操作很多,那有没有什么优化手段?有的,聪明的程序员又出现了,为了优化上述问题,零拷贝技术出现了。
三、零拷贝
目的:减少 IO 流程中不必要的拷贝
零拷贝需要 OS 支持,也就是需要 kernel暴 露 api,虚拟机不能操作内核。
Linux 支持的(常见)零拷贝
1、mmap 内存映射
那我们这里先来了解下什么是mmap 内存映射。
在 Linux 中我们可以使用 mmap 用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。
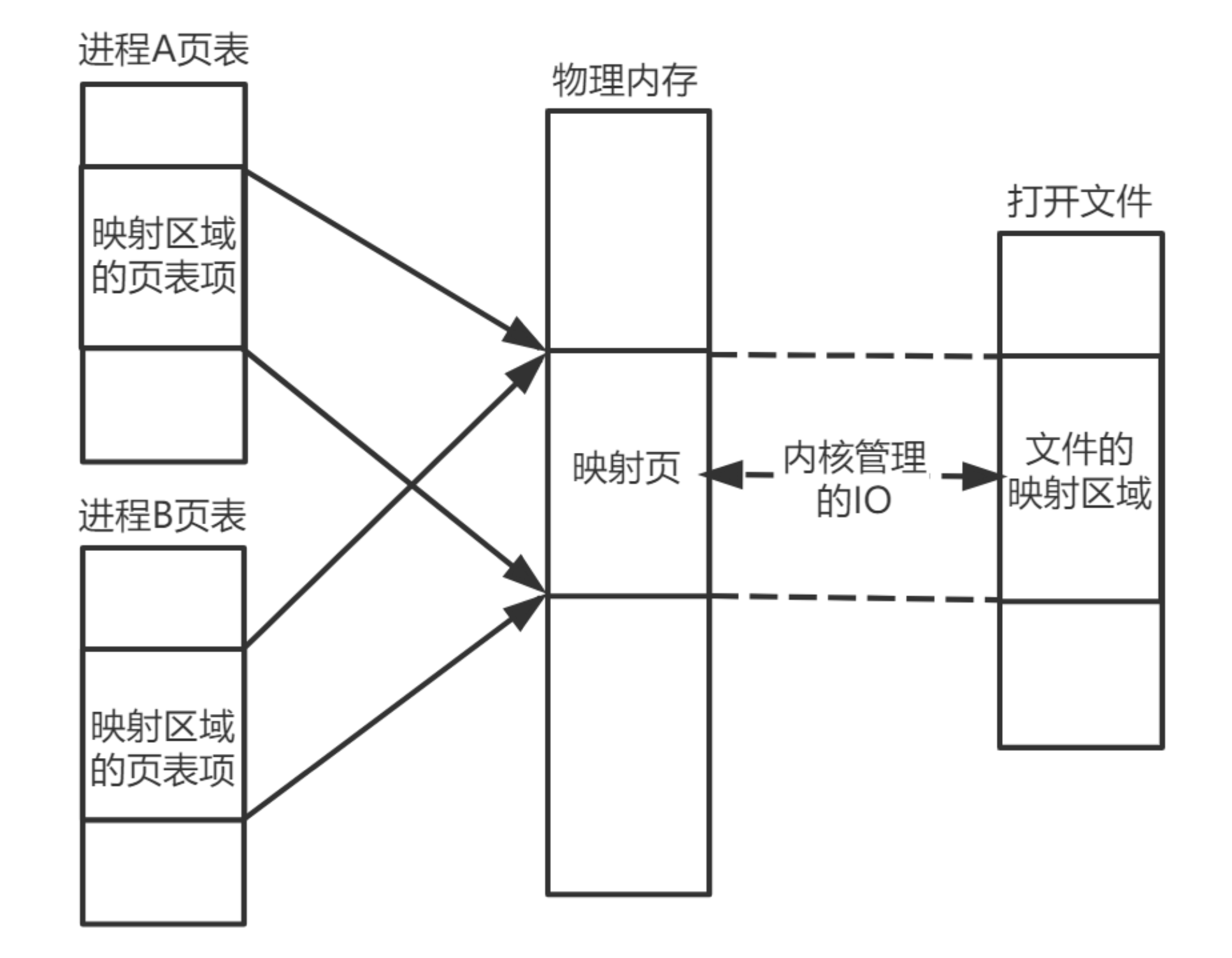
映射关系可以分为两种
- 文件映射:磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。
- 匿名映射:初始化全为 0 的内存空间。
而对于映射关系是否共享又分为
- 私有映射(MAP_PRIVATE) 多进程间数据共享,修改不反应到磁盘实际文件,是一个 copy-on- write(写时复制) 的映射方式。
- 共享映射(MAP_SHARED) 多进程间数据共享,修改反应到磁盘实际文件中。
因此总结起来有4种组合
- 私有文件映射:多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中。
- 私有匿名映射:mmap会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存 (malloc分配大内存会调用mmap)。 例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会 copy-on-write。
- 共享文件映射:多个进程通过虚拟内存技术共享同样的物理内存空间,对内存文件的修改会反应到实际物理文件中,他也是进程间通信(IPC)的一种机制。
- 共享匿名映射:这种机制在进行fork的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信(IPC)。
mmap 只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。
在 mmap 之后,并没有在将文件内容加载到物理页上,只上在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生"缺页",由内核的缺页异常处理程序处理,将文件对应内容,以页为单位(4096)加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多。
好了,了解完 mmap 内存映射的原理后,我们再来看下 mmap 是怎么对上面传统 IO 进行优化的。

mmap 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少内核空间到用户空间的拷贝次数。
如上图,user buffer 和 kernel buffer 共享 index.html。如果你想把硬盘的 index.html 传输到网络中,再也不用拷贝到用户空间,再从用户空间拷贝到 socket 缓冲区。
现在,你只需要从内核缓冲区拷贝到 socket 缓冲区即可,这将减少一次内存拷贝(从 4 次变成了 3 次),但不减少上下文切换次数。
2、sendfile
那么,我们还能继续优化吗? Linux 2.1 版本 提供了 sendFile 函数。
when calling the sendfile() system call, data are fetched from disk and copied into a kernel buffer by DMA copy. Then data are copied directly from the kernel buffer to the socket buffer. Once all data are copied into the socket buffer, the sendfile() system call will return to indicate the completion of data transfer from the kernel buffer to socket buffer. Then, data will be copied to the buffer on the network card and transferred to the network.
其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 Socket Buffer,同时,由于和用户态完全无关,就减少了一次上下文切换。

如上图,我们进行 sendFile 系统调用时,数据被 DMA 引擎从文件复制到内核缓冲区,然后调用 write 方法时,从内核缓冲区进入到 socket,这时,是没有上下文切换的,因为都在内核空间。
最后,数据从 socket 缓冲区进入到协议栈。此时,数据经过了 3 次拷贝,2 次上下文切换。那么,还能不能再继续优化呢? 例如直接从内核缓冲区拷贝到网络协议栈?
3、Sendfile With DMA Scatter/Gather Copy
实际上,Linux 在 2.4 版本中,做了一些优化。
Then by using the DMA scatter/gather operation, the network interface card can gather all the data from different memory locations and store the assembled packet in the network card buffer.
避免了从内核缓冲区拷贝到 socket buffer 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝。
具体如下图:

Scatter/Gather 可以看作是 sendfile 的增强版,批量 sendfile。
现在,index.html 要从文件进入到网络协议栈,只需 2 次拷贝:第一次使用 DMA 引擎从文件拷贝到内核缓冲区,第二次从内核缓冲区将数据拷贝到网络协议栈;内核缓存区只会拷贝一些 offset 和 length 信息到 socket buffer,基本无消耗。
4、零拷贝小结
等一等,老周,不是说的零拷贝吗?怎么还需要 2 次拷贝?
首先我们说零拷贝,是从操作系统的角度来说的(也就是我们上文所说的狭义零拷贝)。因为内核缓冲区之间,没有数据是重复的(只有 kernel buffer 有一份数据,sendFile 2.1 版本实际上有 2 份数据,算不上零拷贝(严谨点的话叫狭义零拷贝))。例如我们刚开始的例子,内核缓存区和 socket 缓冲区的数据就是重复的。
mmap 和 sendFile 的区别
- mmap 适合小数据量读写,sendFile 适合大文件传输。
- sendFile 可以利用 DMA 方式,减少 CPU 拷贝,mmap 则不能(必须从内核拷贝到 Socket 缓冲区)。
- RocketMQ 在消费消息时,使用了 mmap。Kafka 使用了 sendFile。
| CPU拷贝 | DMA拷贝 | 上下文切换 | 系统调用 | |
|---|---|---|---|---|
| 传统 IO | 2 | 2 | 4 | read/write |
| mmap | 1 | 2 | 4 | mmap/write |
| sendfile | 1 | 2 | 2 | sendfile |
| sendfile with dma scatter/gather copy | 0 | 2 | 2 | sendfile |
四、零拷贝在Java中的应用
1、NIO
1.1 MappedByteBuffer
首先要说明的是,Java NlO 中 的 Channel (通道)就相当于操作系统中的内核缓冲区,有可能是读缓冲区,也有可能是网络缓冲区,而 Buffer 就相当于操作系统中的用户缓冲区。
MappedByteBuffer mappedByteBuffer = new RandomAccessFile(file, "r")
.getChannel()
.map(FileChannel.MapMode.READ_ONLY, 0, len);
NIO 中的 FileChannel.map() 方法其实就是采用了操作系统中的内存映射方式,底层就是调用 Linux mmap() 实现的。
将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射。这种方式适合读取大文件,同时也能对文件内容进行更改,但是如果其后要通过 SocketChannel 发送,还是需要CPU进行数据的拷贝。
使用 MappedByteBuffer,小文件,效率不高;一个进程访问,效率也不高。
MappedByteBuffer 只能通过调用 FileChannel 的 map() 取得,再没有其他方式。
FileChannel.map() 是抽象方法,具体实现是在 FileChannelImpl.map() 可自行查看 JDK 源码,其 map0() 方法就是调用了 Linux 内核的 mmap 的 API。
使用 MappedByteBuffer 类要注意的是:mmap的文件映射,在 full gc 时才会进行释放。当 close 时,需要手动清除内存映射文件,可以反射调用 sun.misc.Cleaner 方法。
1.2 sendfile
- FileChannel.transferTo() 方法直接将当前通道内容传输到另一个通道,没有涉及到 Buffer 的任何操作,NIO 中的 Buffer 是 JVM 堆或者堆外内存,但不论如何他们都是操作系统内核空间的内存。
- transferTo() 的实现方式就是通过系统调用 sendfile() (当然这是Linux中的系统调用)。
// 使用sendfile:读取磁盘文件,并网络发送
FileChannel sourceChannel = new RandomAccessFile(source, "rw").getChannel();
SocketChannel socketChannel = SocketChannel.open(sa);
sourceChannel.transferTo(0, sourceChannel.size(), socketChannel);
ZeroCopyFile实现文件复制:
class ZeroCopyFile {
public void copyFile(File src, File dest) {
try (FileChannel srcChannel = new FileInputStream(src).getChannel();
FileChannel destChannel = new FileInputStream(dest).getChannel()) {
srcChannel.transferTo(0, srcChannel.size(), destChannel);
} catch (IOException e) {
e.printStackTrace();
}
}
}
Java NIO 提供的 FileChannel.transferTo 和 transferFrom 并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供 sendfile 这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
2、Netty
Netty 中也用到了 FileChannel.transferTo 方法,所以 Netty 的零拷贝也包括上面讲的操作系统级别的零拷贝。
传统的 ByteBuffer,如果需要将两个 ByteBuffer 中的数据组合到一起,我们需要首先创建一个size=size1+size2 大小的新的数组,然后将两个数组中的数据拷贝到新的数组中。但是使用 Netty 提供的组合 ByteBuf,就可以避免这样的操作,因为 CompositeByteBuf 并没有真正将多个 Buffer 组合起来,而是保存了它们的引用,从而避免了数据的拷贝,实现了零拷贝。
CompositeByteBuf:将多个缓冲区显示为单个合并缓冲区的虚拟缓冲区。
建议使用 ByteBufAllocator.compositeBuffer() 或者 Unpooled.wrappedBuffer(ByteBuf…),而不是显式调用构造函数。
我们l来看下源码
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
public static final ByteToMessageDecoder.Cumulator MERGE_CUMULATOR = new ByteToMessageDecoder.Cumulator() {
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf var5;
try {
ByteBuf buffer;
if (cumulation.writerIndex() <= cumulation.maxCapacity() - in.readableBytes() && cumulation.refCnt() <= 1 && !cumulation.isReadOnly()) {
buffer = cumulation;
} else {
buffer = ByteToMessageDecoder.expandCumulation(alloc, cumulation, in.readableBytes());
}
buffer.writeBytes(in);
var5 = buffer;
} finally {
in.release();
}
return var5;
}
};
// 可以看出来这里用了ByteBufAllocator 来分配readable的空间,并写入累积器中
static ByteBuf expandCumulation(ByteBufAllocator alloc, ByteBuf cumulation, int readable) {
ByteBuf oldCumulation = cumulation;
cumulation = alloc.buffer(cumulation.readableBytes() + readable);
cumulation.writeBytes(oldCumulation); // 将原始累积器的数据copy到新的累积器
oldCumulation.release(); // 释放原始的累积器
return cumulation;
}
...
}
写文件Region
从这里我们可以看出 netty 也调用了 FileChannelDe tansferTo 方法:
public class DefaultFileRegion extends AbstractReferenceCounted implements FileRegion {
private FileChannel file;
public long transferTo(WritableByteChannel target, long position) throws IOException {
long count = this.count - position;
if (count >= 0L && position >= 0L) {
if (count == 0L) {
return 0L;
} else if (this.refCnt() == 0) {
throw new IllegalReferenceCountException(0);
} else {
this.open();
long written = this.file.transferTo(this.position + position, count, target);
if (written > 0L) {
this.transferred += written;
} else if (written == 0L) {
validate(this, position);
}
return written;
}
} else {
throw new IllegalArgumentException("position out of range: " + position + " (expected: 0 - " + (this.count - 1L) + ')');
}
}
...
}
3、RocketMQ、Kafka等MQ
MQ这块的应用老周后续再来分析,敬请期待~
欢迎大家关注我的公众号【老周聊架构】,Java后端主流技术栈的原理、源码分析、架构以及各种互联网高并发、高性能、高可用的解决方案。

喜欢的话,一键三连走一波。