Go调试神器pprof使用教程
go的GC会自动管理内存,但是这不代表go程序就不会内存泄露了。 go常见产生内存泄露的原因就是goroutine没有结束,简单说就是goroutine 被阻塞了,这样就会导致goroutine引用的内存不被GC回收。
1 概念
在Go中,我们可以通过标准库的代码包runtime和runtime/pprof中的程序来生成三种包含实时性数据的概要文件,分别是CPU概要文件、内存概要文件和程序阻塞概要文件。
- CPU概要文件:默认情况下,Go的运行时系统会以100Hz的频率对CPU的使用情况进行取样
- 内存概要文件:程序运行过程中堆内存的分配情况
- 程序阻塞概要文件:用于保护用户程序中的Goroutine阻塞事件的记录
- Goroutine 活跃Goroutine信息的记录 仅在获取时取样一次
- Threadcreate 系统线程创建情况的记录 仅在获取时取样一次
- Heap 堆内存分配情况的记录 默认每分配512K字节时取样一次
- Block Goroutine阻塞事件的记录 默认每发生一次阻塞事件时取样一次
2 使用
前提:代码中引入pprof
package main
import "net/http"
import _ "net/http/pprof"
func main() {
go func() {
http.ListenAndServe("0.0.0.0:80", nil)
}()
select {
}
}
①浏览器中查看
- 浏览器中输入地址localhost/debug/pprof
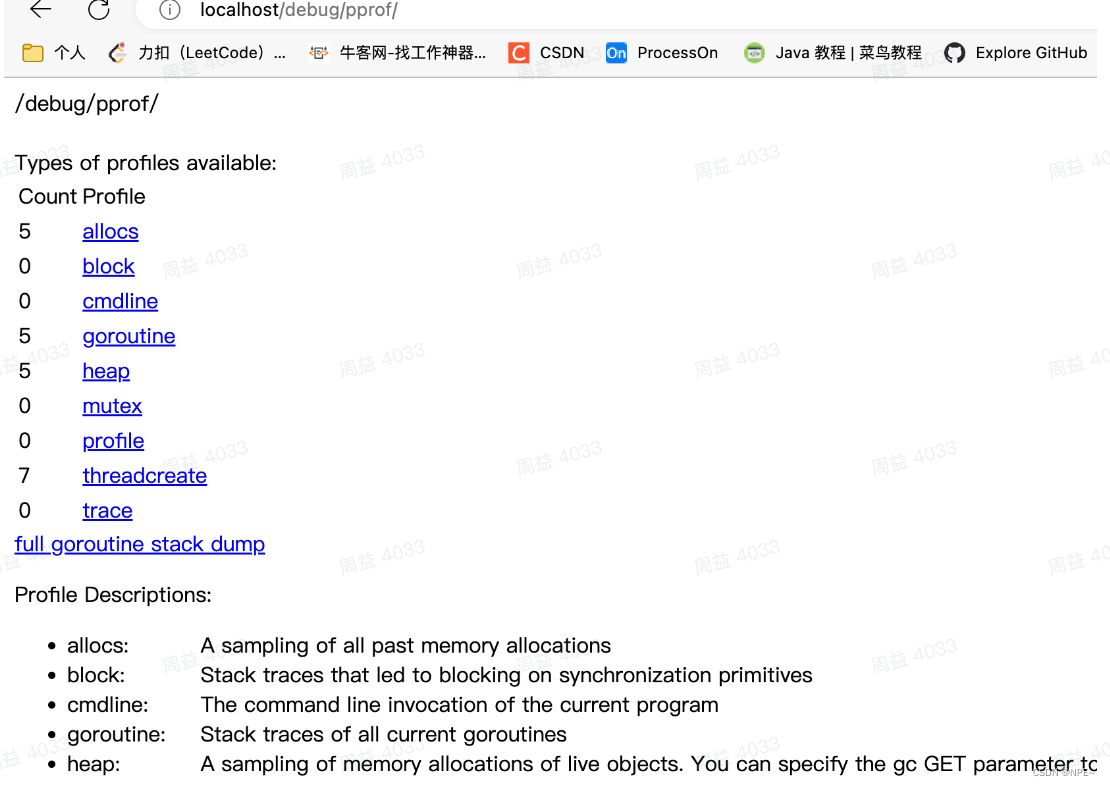
profiles下分别是block(阻塞情况)、goroutine数量、heap(堆)、mutex(锁)和threadcreate(创建的物理线程)
点击heap可以看到如下堆内存及GC相关的参数信息

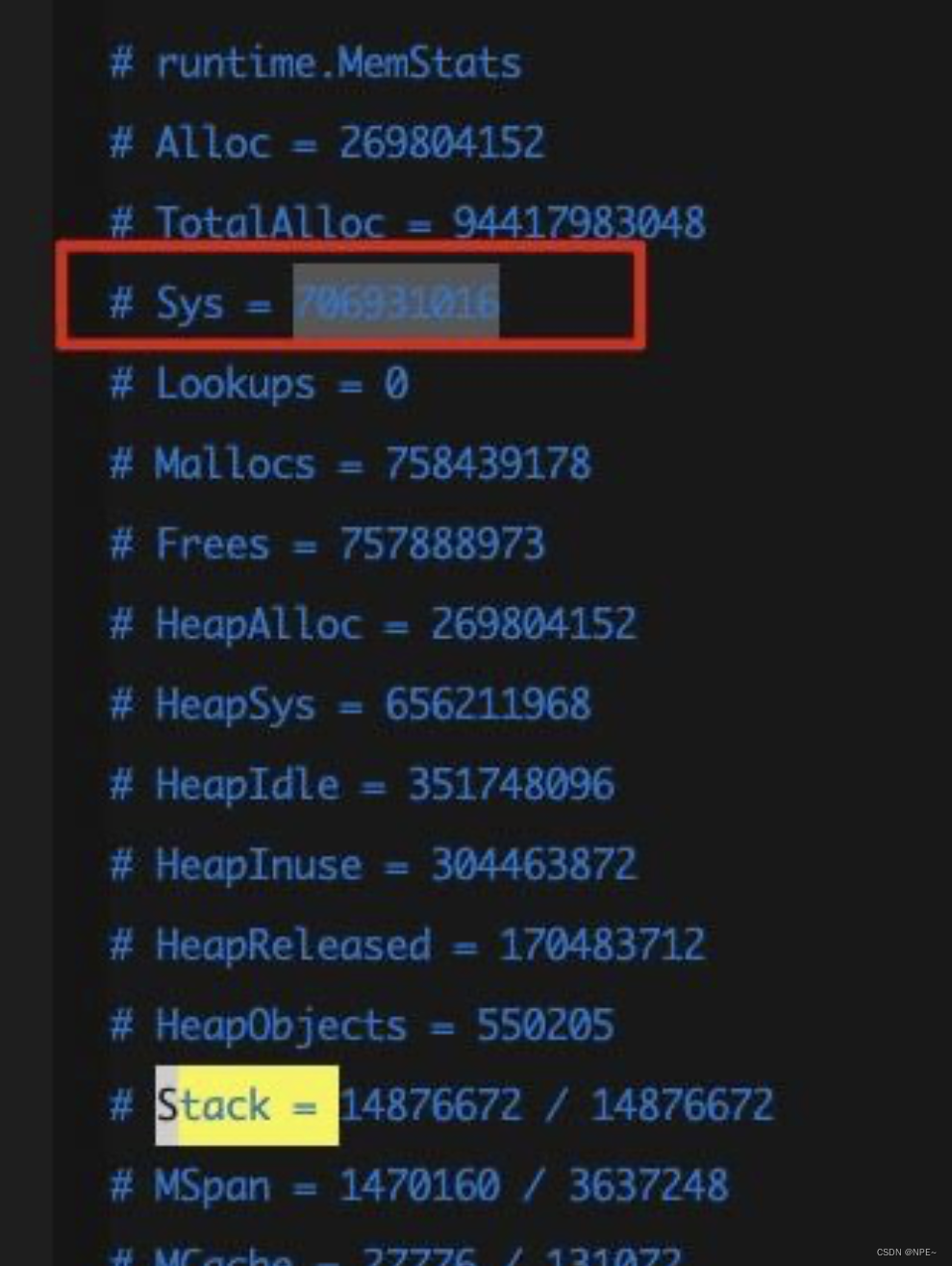
这里是调用Go底层的runtime.MemStats结构体获取,该结构体相关字段解释如下:
Alloc uint64 //golang语言框架堆空间分配的字节数
TotalAlloc uint64 //从服务开始运行至今分配器为分配的堆空间总 和,只有增加,释放的时候不减少
Sys uint64 //服务现在系统使用的内存
Lookups uint64 //被runtime监视的指针数
Mallocs uint64 //服务malloc heap objects的次数
Frees uint64 //服务回收的heap objects的次数
HeapAlloc uint64 //服务分配的堆内存字节数
HeapSys uint64 //系统分配的作为运行栈的内存
HeapIdle uint64 //申请但是未分配的堆内存或者回收了的堆内存(空闲)字节数
HeapInuse uint64 //正在使用的堆内存字节数
HeapReleased uint64 //返回给OS的堆内存,类似C/C++中的free。
HeapObjects uint64 //堆内存块申请的量
StackInuse uint64 //正在使用的栈字节数
StackSys uint64 //系统分配的作为运行栈的内存
MSpanInuse uint64 //用于测试用的结构体使用的字节数
MSpanSys uint64 //系统为测试用的结构体分配的字节数
MCacheInuse uint64 //mcache结构体申请的字节数(不会被视为垃圾回收)
MCacheSys uint64 //操作系统申请的堆空间用于mcache的字节数
BuckHashSys uint64 //用于剖析桶散列表的堆空间
GCSys uint64 //垃圾回收标记元信息使用的内存
OtherSys uint64 //golang系统架构占用的额外空间
NextGC uint64 //垃圾回收器检视的内存大小
LastGC uint64 // 垃圾回收器最后一次执行时间。
PauseTotalNs uint64 // 垃圾回收或者其他信息收集导致服务暂停的次数。
PauseNs [256]uint64 //一个循环队列,记录最近垃圾回收系统中断的时间
PauseEnd [256]uint64 //一个循环队列,记录最近垃圾回收系统中断的时间开始点。
NumForcedGC uint32 //服务调用runtime.GC()强制使用垃圾回收的次数。
GCCPUFraction float64 //垃圾回收占用服务CPU工作的时间总和。如果有100个goroutine,垃圾回收的时间为1S,那么就占用了100S。
BySize //内存分配器使用情况
如果觉得文字展示不够直观,我们也可以通过导入第三方组建来动态展示图表
package main
import (
"fmt"
_ "github.com/mkevac/debugcharts" // 可选,添加后可以查看几个实时图表数据
"net/http"
_ "net/http/pprof" // 必须,引入 pprof 模块
)
func main() {
go func() {
// terminal: $ go tool pprof -http=:8081 http://localhost:6060/debug/pprof/heap
// web:
// 1、http://localhost:8081/ui
// 2、http://localhost:6060/debug/charts
// 3、http://localhost:6060/debug/pprof
fmt.Println(http.ListenAndServe("0.0.0.0:6060", nil))
}()
fmt.Println("this is a demo about how to use go pprof")
select {
}
}
输入网址:http://localhost:6060/debug/charts/
- 查看效果
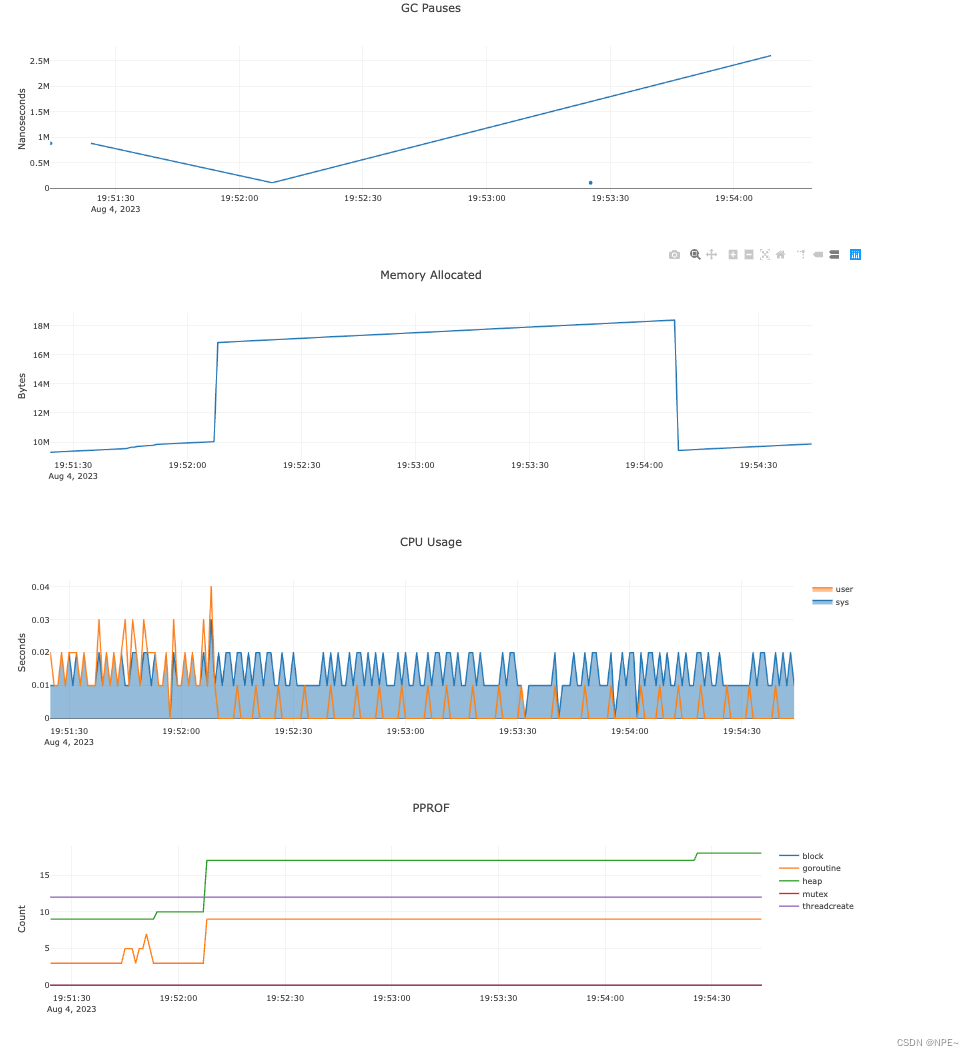
②go tool pprof 命令行工具
例:查看内存使用情况
# 在bash控制台执行如下命令,查看内存使用情况
> go tool pprof http://localhost:80/debug/pprof/heap
会进入如下gdb交互模式:

> help可以查看使用说明
> top 可以查看前10个的内存分配情况
> tree 以树状显示
> png 以图片格式输出
> svg 生成浏览器可以识别的svg文件
例:查看cpu使用情况
> go tool pprof http://localhost:80/debug/pprof/profile
该操作默认需要等待30s
查看其他信息同上操作。
③实战:排查线上问题(内存暴涨)
- 问题:内存暴涨
每天晚上八点左右,服务的内存就开始暴涨,曲线骤降的地方都是手动重启服务才降下来的,内存只要上去了就不会再降了,有时候内存激增直接打爆了内存触发了OOM。
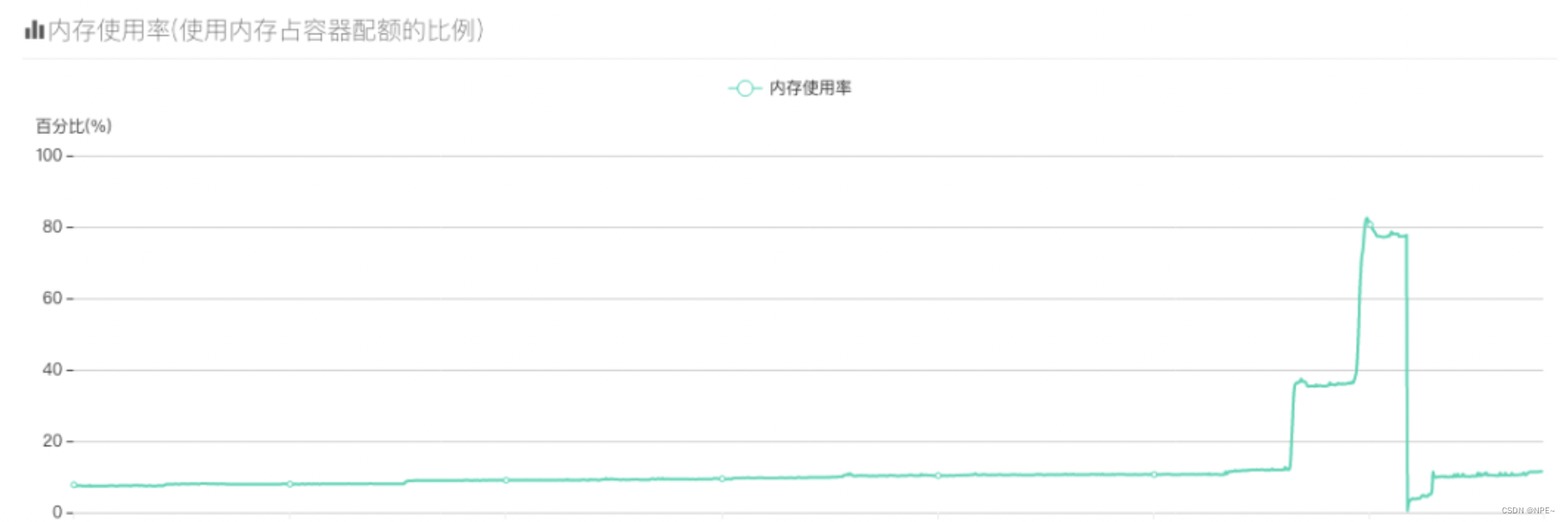
- 有的同学可能就会说了“啊,你容器的内存是不是不够啊,开大一点不就好了?”,容器已经开到20G内存了…我们再用top看看服务内存情况:

让我忍不住直呼好家伙,服务进程使用的常驻内存RES居然有6G+,这明显没把我golang的gc放在眼里,该项目也没用本地缓存之类的,这样的内存占用明显不合理,没办法只好祭出我们golang内存分析利器:pprof。
- 有了pprof就很好办了是吧,瞬间柳暗花明啊,“这个内存泄漏我马上就能fix”,找了一天晚上八点钟,准时蹲着内存泄漏。我们直接找一台能ping通容器并且装了golang的机器,直接用下面的命令看看当前服务的内存分配情况:
$ go tool pprof -inuse_space http://ip:amdin_port/debug/pprof/heap
-inuse_space参数就是当前服务使用的内存情况
还有一个-alloc_space参数是指服务启动以来总共分配的内存情况,显然用前者比较直观,进入交互界面后我们用top命令看下当前占用内存最高的部分:
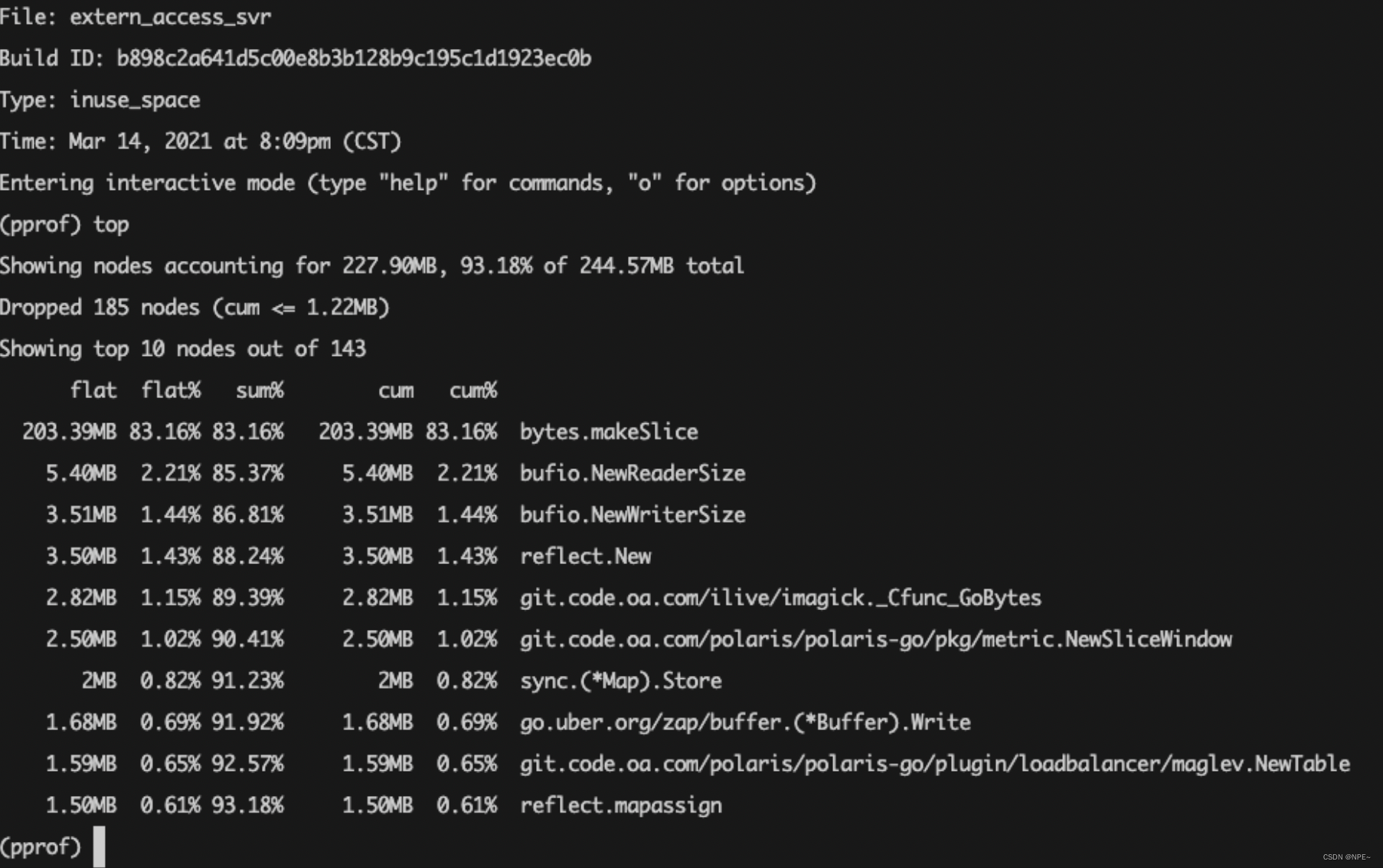
“结果是非常的amazing啊”,当时的内存分配最大的就是bytes.makeSlice,这个是不存在内存泄漏问题的,我们再用命令png生成分配图看看(需要装graphviz):
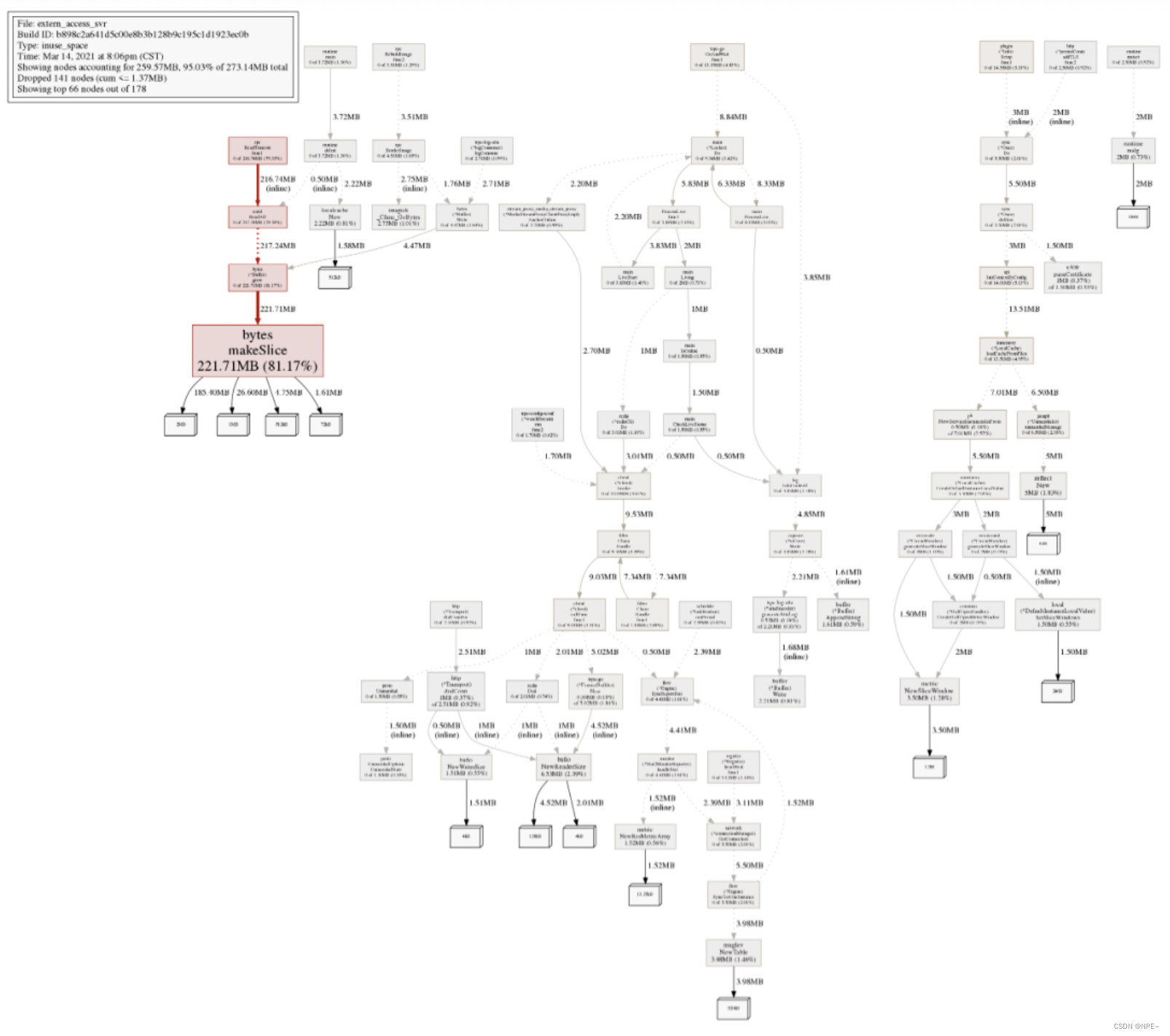
4. 看起来除了bytes.makeSlice分配内存比较大,其他好像也并没有什么问题,不行,再抓一下当前内存分配的详情:
$ wget http://ip:admin_port/debug/pprof/heap?debug=1
这个命令其实就是把当前内存分配的详情文件抓了下来,本地会生成一个叫heap?debug=1的文件,看一看服务内存分配的具体情况:
有句话说的好啊:golang10次内存泄漏,8次goroutine泄漏,1次真正内存泄漏,于是我敲下了下面的命令:
$ wget http://ip:admin_port/debug/pprof/goroutine?debug=1
$ wget http://ip:admin_port/debug/pprof/goroutine?debug=2
- debug=1就是获取服务当前goroutine的数目和大致信息
- debug=2获取服务当前goroutine的详细信息,分别在本地生成了goroutine?debug=1和goroutine?debug=2文件,先看前者:

服务当前的goroutine数也就才1033,也不至于占用那么大的内存。再看看服务线程挂的子线程有多少:
$ ps mp 3030923 -o THREAD,tid | wc -l
好像也不多,只有20多。我们再看看后者,不看不知道,一看吓一跳:
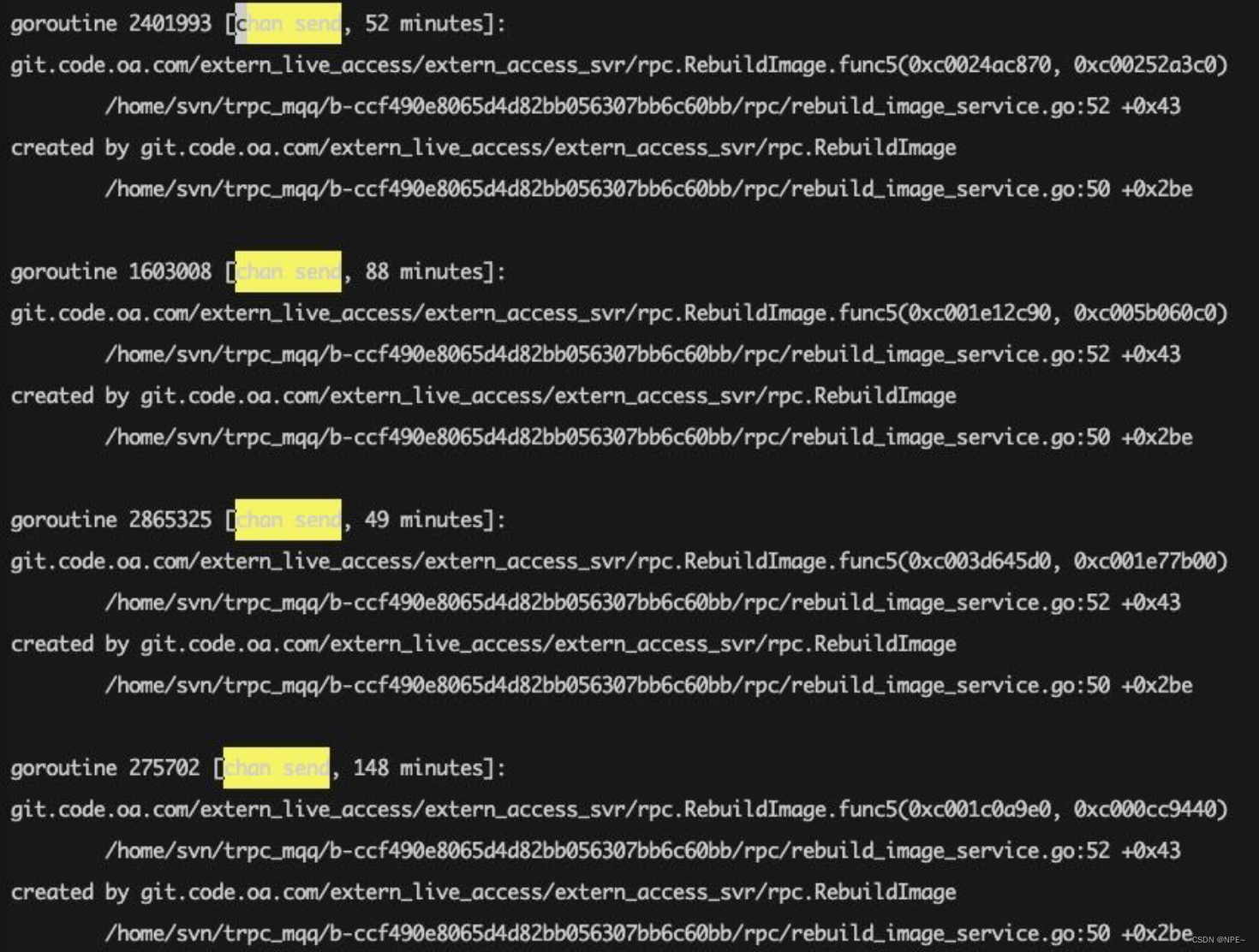
可以看到goroutine里面有很多chan send这种阻塞了很长时间的case,“这不就找到问题了吗?就这?嗯?就这?”,赶紧找到对应的函数,发现之前的同学写了类似这样的代码:
func RebuildImage() {
var wg sync.WaitGroup wg.Add(3)
// 耗时1 go func() { // do sth defer wg.Done() } ()
// 耗时2 go func() { // do sth defer wg.Done() } ()
// 耗时3 go func() { // do sth defer wg.Done() } ()
ch := make(chan struct{
})
go func () {
wg.Wait() ch <- struct{
}{
} }()
// 接收完成或者超时 select { case <- ch: return case <- time.After(time.Second * 10): return }}
简单来说这段代码就是开了3个goroutine处理耗时任务,最后等待三者完成或者超时失败返回,因为这里的channel在make的时候没有设置缓冲值,所以当超时的时候函数返回,此时ch没有消费者了,就一直阻塞了。看一看这里超时的监控项和内存泄漏的曲线:
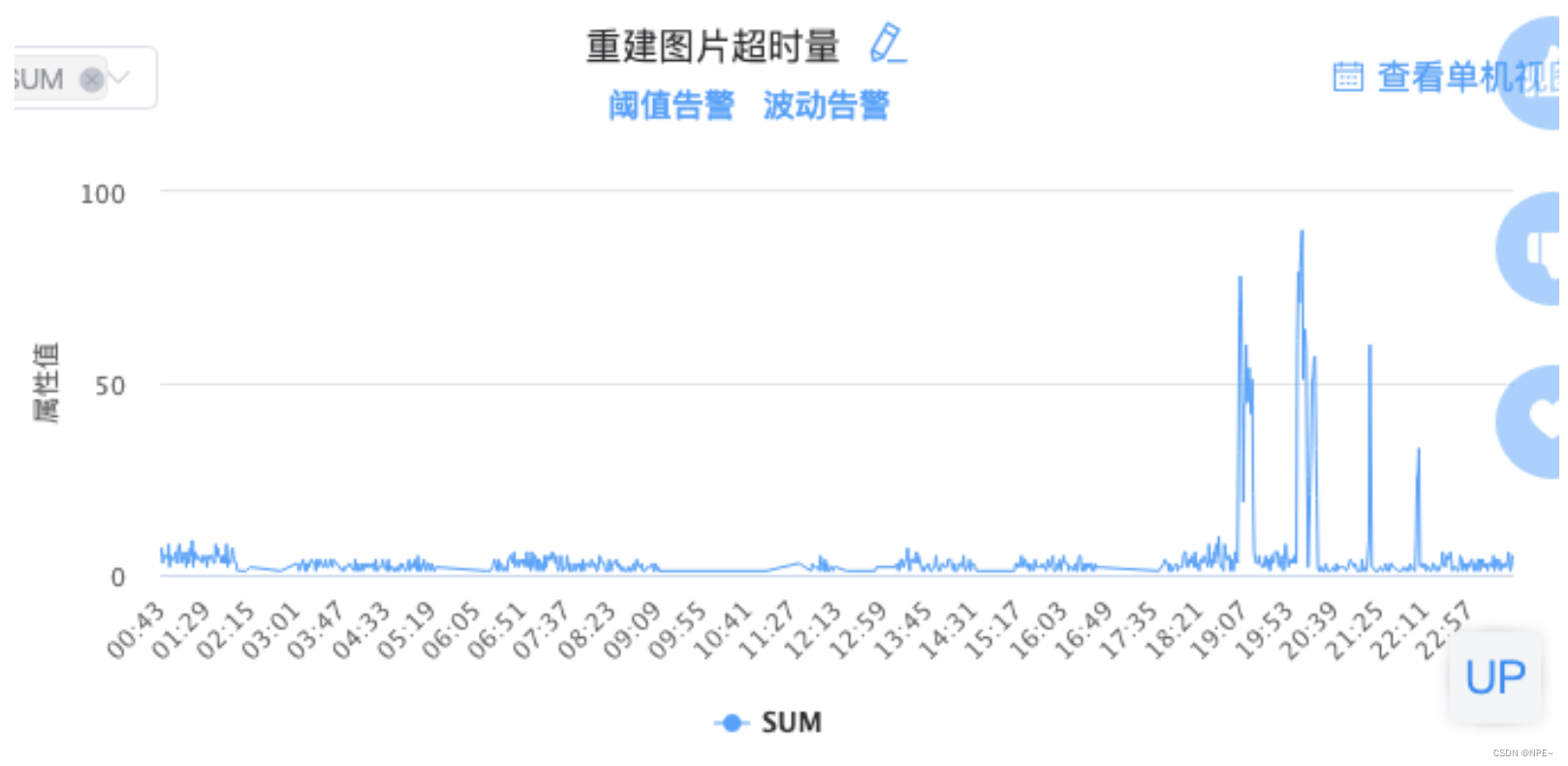
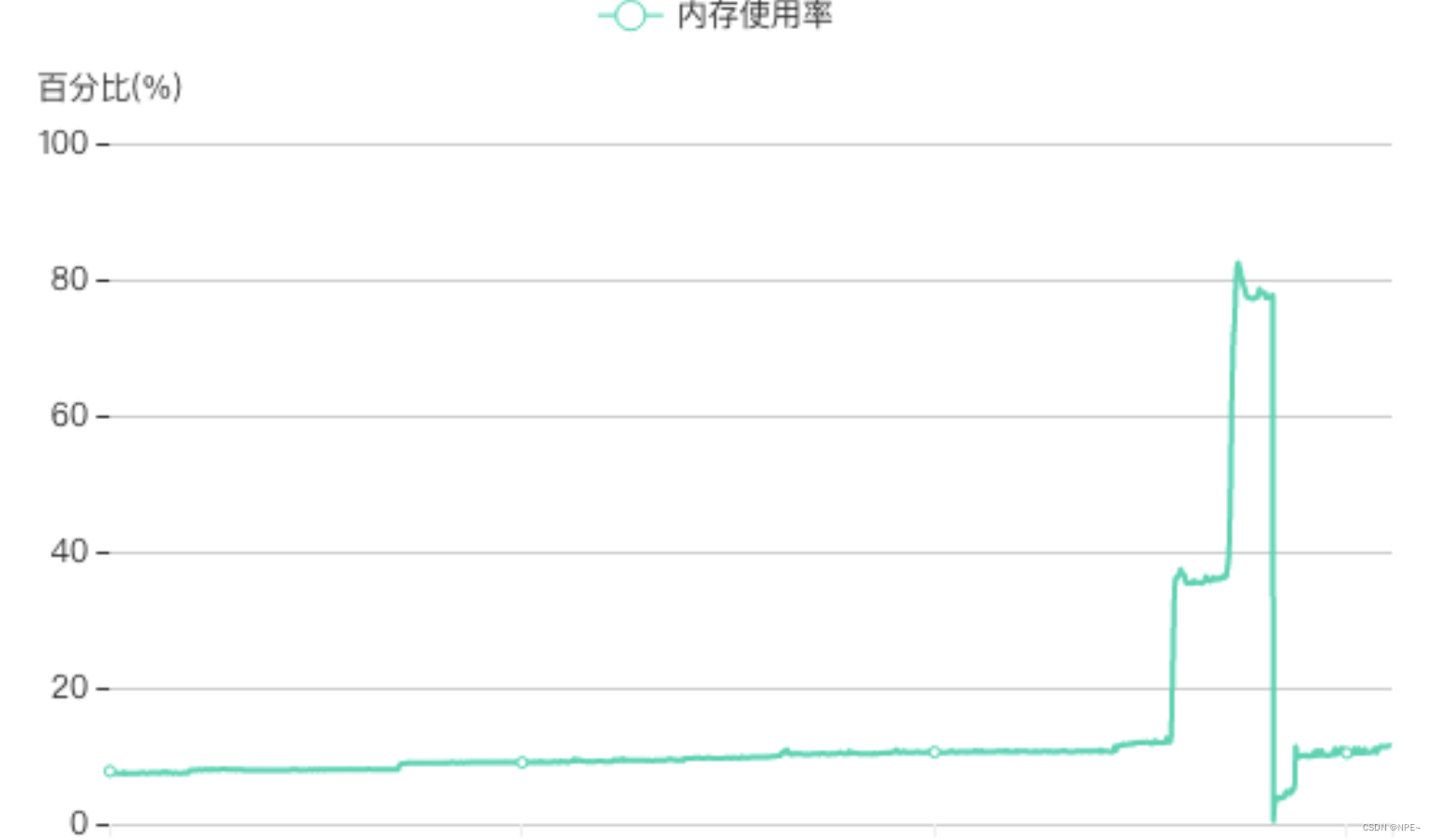
时间也能对上,至此问题解决。
参考:
https://blog.csdn.net/skh2015java/article/details/102748222
https://cloud.tencent.com/developer/article/2279678