响应中文乱码:
当调用接口,响应正文返回的中文是乱码时,一般是响应正文的编码格式不为 utf-8 导致,此时需要根据实际的编码格式处理
示例:
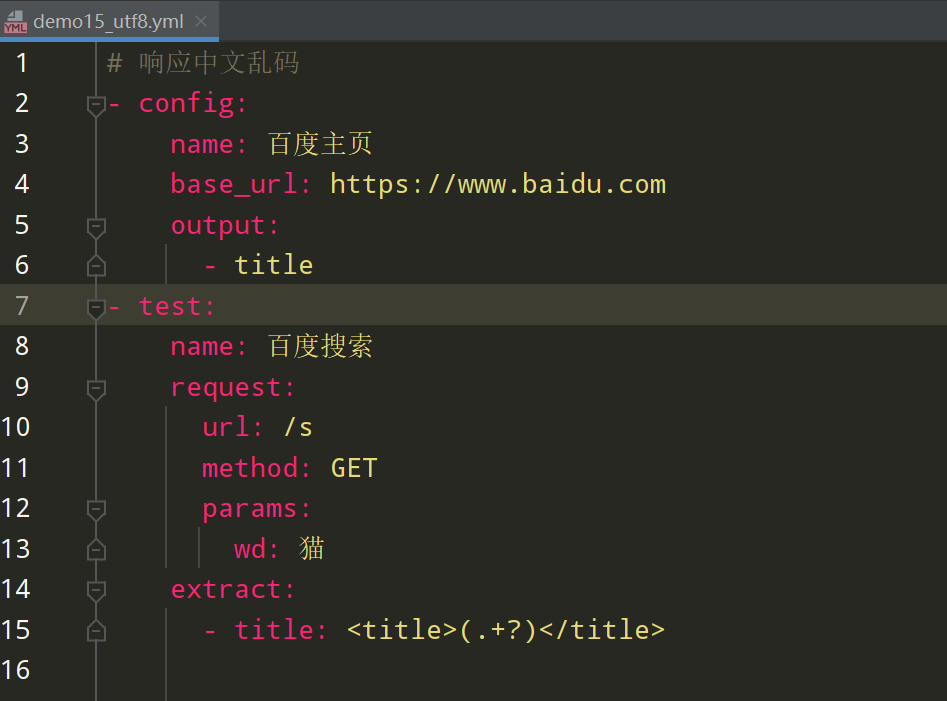
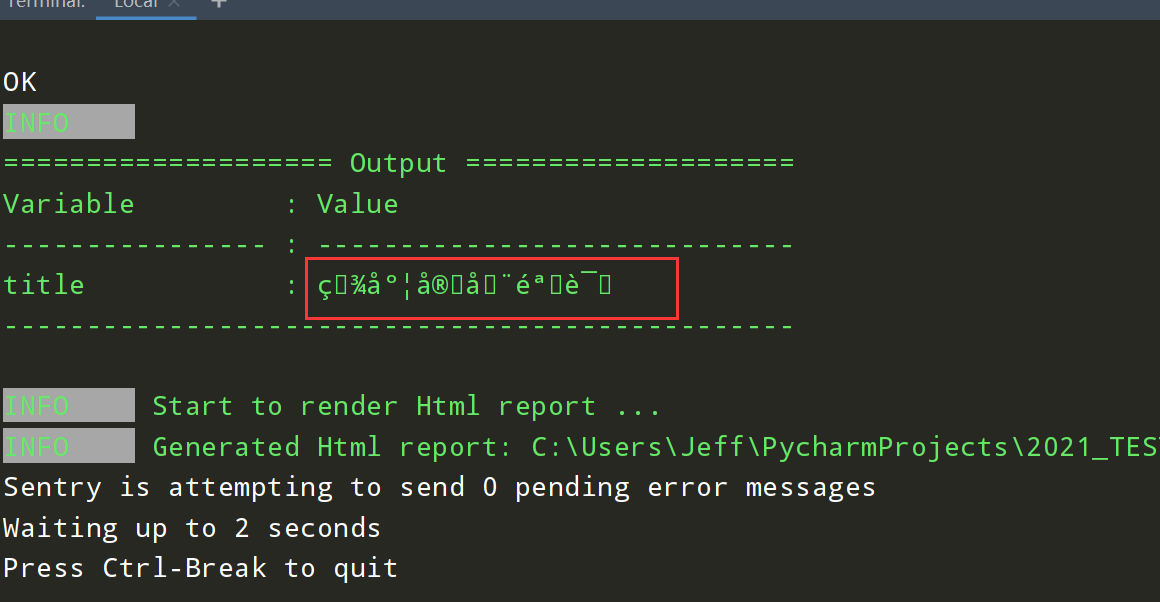
图1中 extract 提取title标题,output 输出 title 变量值,如下图2可见,输出的变量值成了乱码,图3的报告中可以看到响应的编码为 ISO-8859-1

解决方式如下:
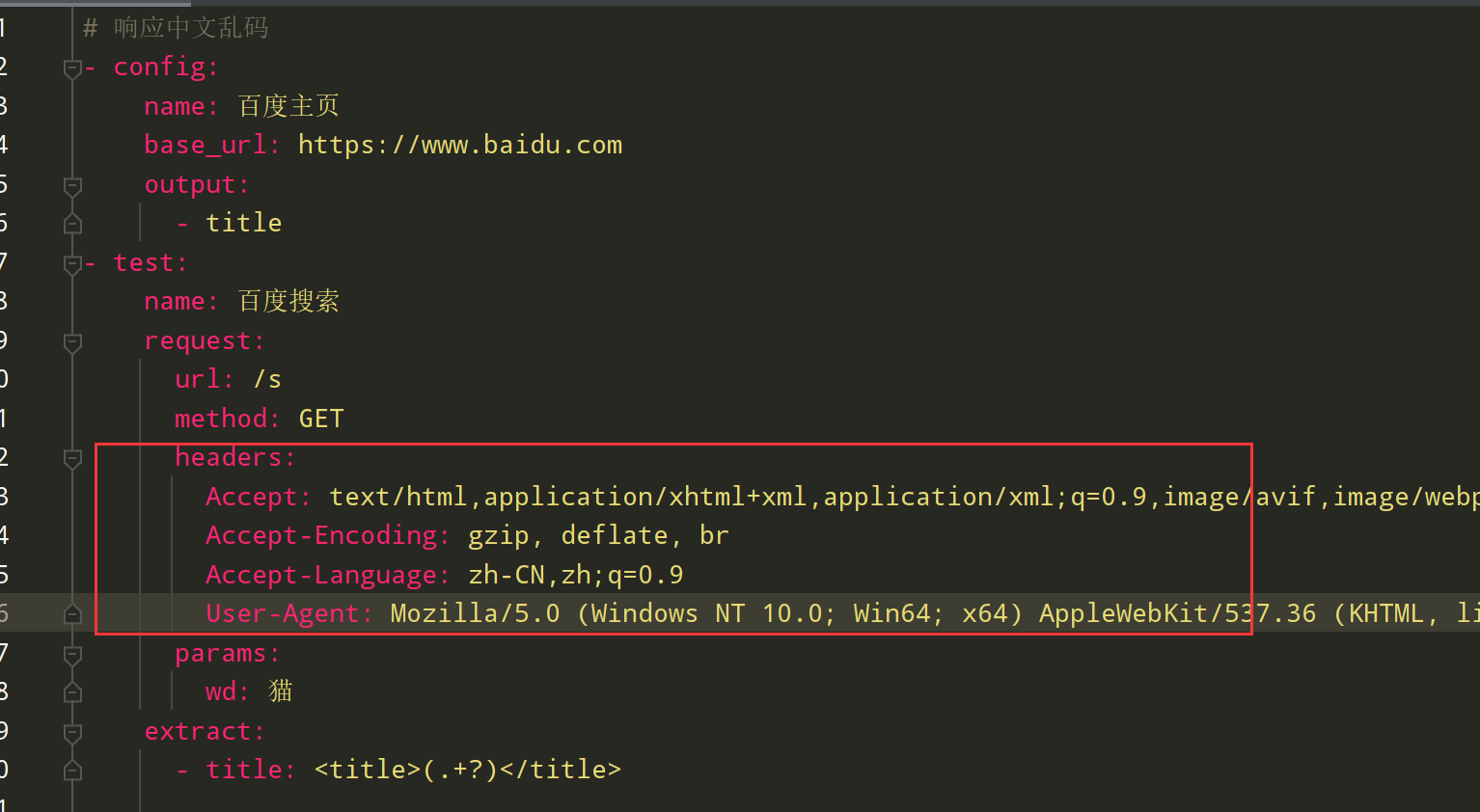
方式一,添加headers头部信息,如下图
4个关键字必须:
User-Agent: *****
Accept: *****
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9

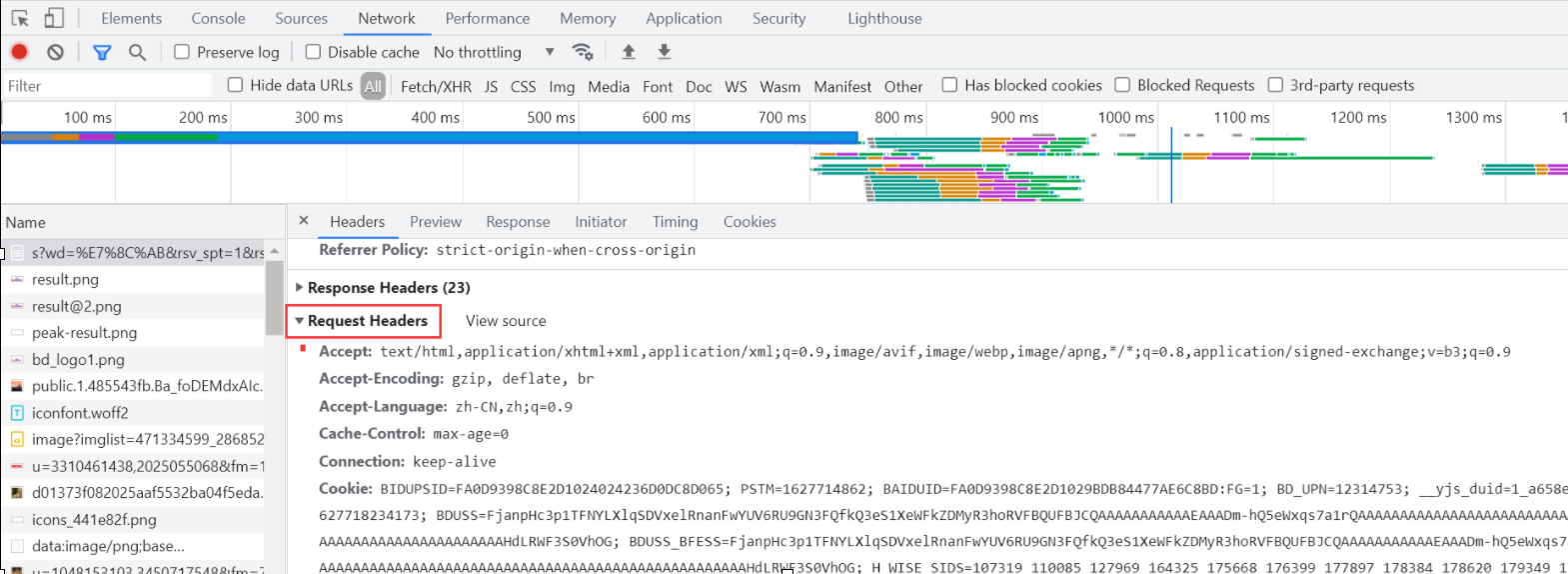
上述头部信息关键字,可通过F12键获取
yaml示例:
添加headers头部信息,如下图
添加头部执行后,输出的变量值为utf-8 中文编码;如下图
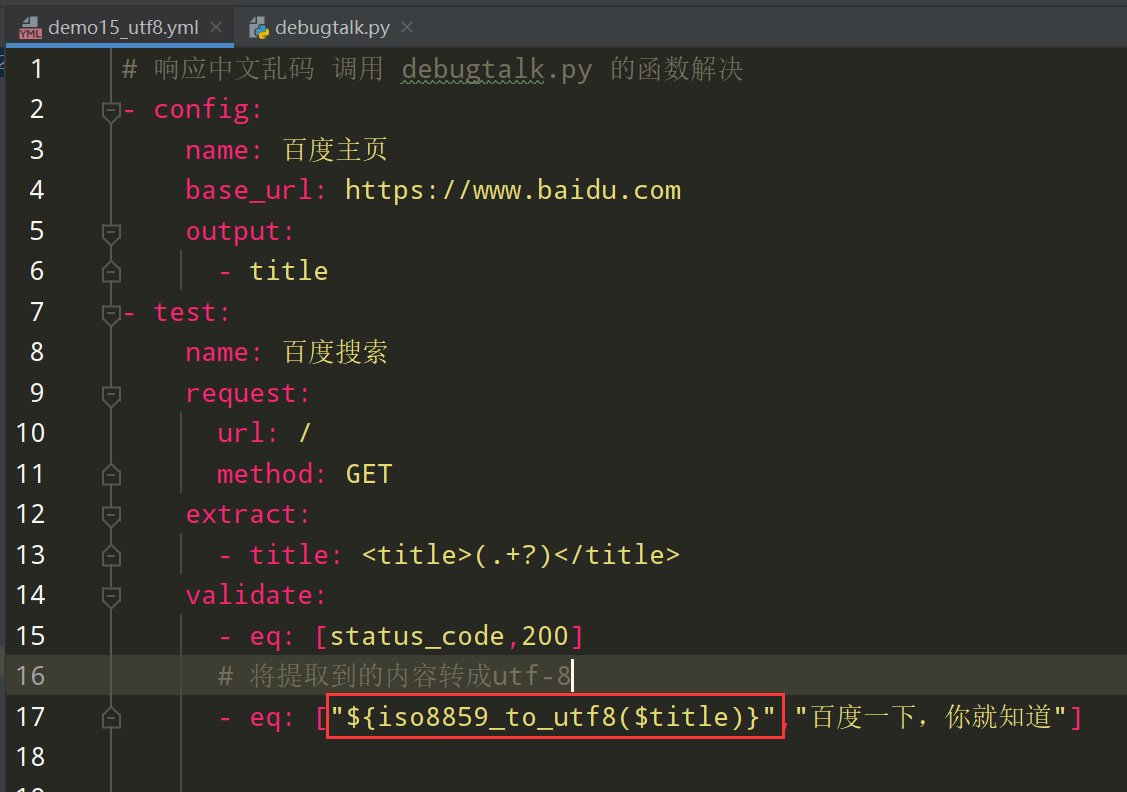
方式二,通过 debugtalk.py 辅助函数编写代码然后yaml文件中调用;
python中内置函数 encode() 和 decode() ,encode()是编码、decode()是解码
debugtalk.py文件的代码如下:
# encode编码 decode解码
# iso8859-1 编码,解码成 utf-8
def iso8859_to_utf8(str):
return str.encode("iso8859-1").decode("utf-8")
# utf-8 编码,解码成 iso8859-1
def utf8_to_iso8859(str):
return str.encode("utf-8").decode("iso8859-1")
# unicode_escape 编码,解码成 utf-8
def unicode_escape_to_utf8(str):
return str.encode("unicode_escape").decode("utf-8")在yaml文件中,断言引用函数需要加引号 " ",如下图
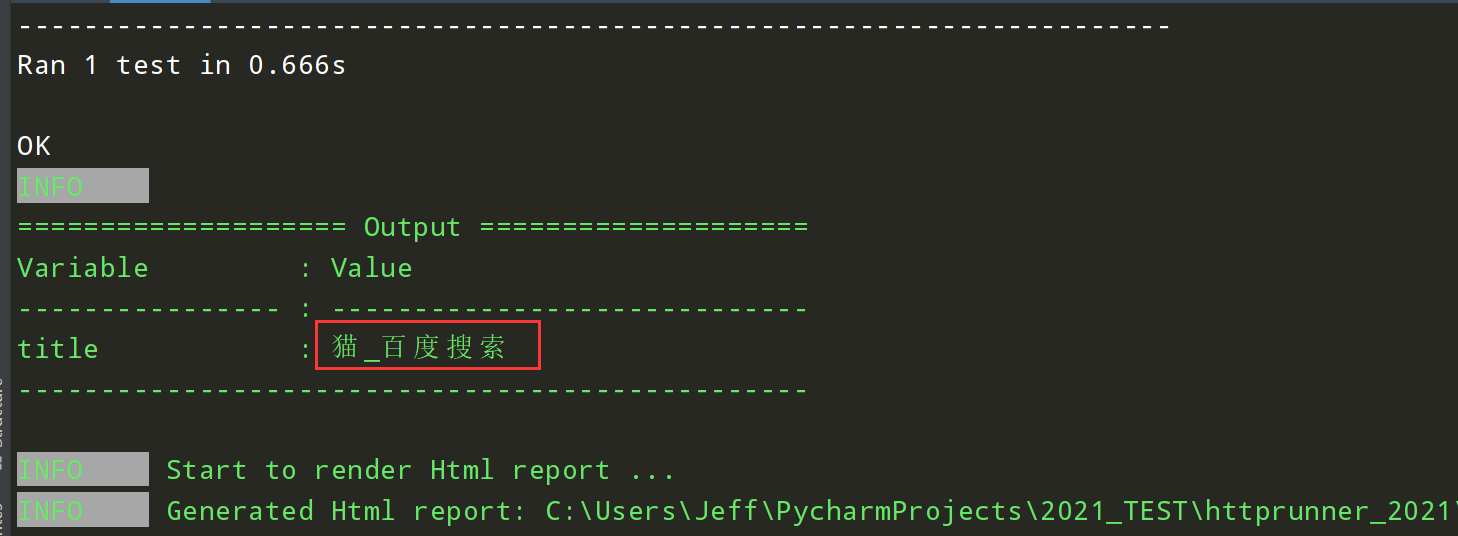
测试报告展示成功,断言成功,如下图:

上述是通过utf-8进行断言比对,还可以通过 iso8859-1 进行断言比对;如下图:
variables: 变量;
把预期结果先做个变量然后转成和实际结果一样的编码,最后再通过断言进行比对,如下图:

测试报告展示成功,断言成功,如下图:

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


如果对你有帮助的话,点个赞收个藏,给作者一个鼓励。也方便你下次能够快速查找。
如有不懂还要咨询下方小卡片,博主也希望和志同道合的测试人员一起学习进步
在适当的年龄,选择适当的岗位,尽量去发挥好自己的优势。
我的自动化测试开发之路,一路走来都离不每个阶段的计划,因为自己喜欢规划和总结,
测试开发视频教程、学习笔记领取传送门!!!