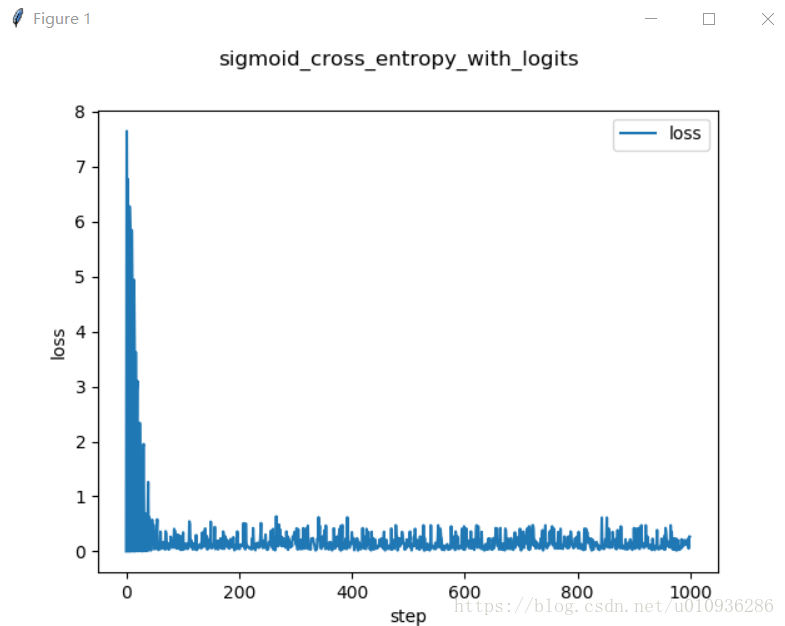
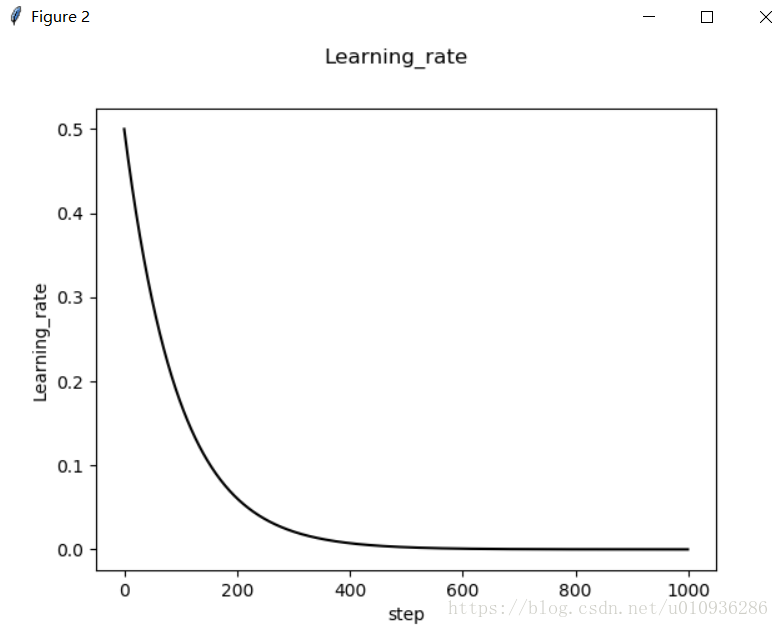
我们直到学习率对于机器学习来说,大的学习率虽然往往能够使得损失函数快速下降,但是导致不收敛或者振荡现象的发生,而小的学习率虽然收敛,但是学习速率太慢,损失函数下降缓慢,需要等待长时间的训练,同时也会容易陷入局部最优。因此,一种解决方法是令学习率随迭代次数的增加而下降。
下面是python示例。该例子可以参考TensorFlow进阶--实现反向传播博文
这里的关键在于
tf.train.exponential_decay(initial_learning_rate,global_step=global_step,decay_steps=10,decay_rate=0.9)
通过设置:
初始学习率initial_learning_rate
当前迭代次数global_step
每decay_steps更新一次学习率
每次更新乘以0.9,达到指数衰减的效果
代码如下
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
#创建计算图会话
sess = tf.Session()
#生成数据并创建在占位符和变量A
x_vals = np.concatenate((np.random.normal(-1,1,50),np.random.normal(3,1,50)))
y_vals = np.concatenate((np.repeat(0.,50),np.repeat(1.,50)))
x_data = tf.placeholder(tf.float32,shape=[1])
y_target = tf.placeholder(tf.float32,shape=[1])
A = tf.Variable(tf.random_normal(mean=10,shape=[1]))
#增加乘法操作
my_output = tf.add(x_data,A)
#由于非归一化logits的交叉熵的损失函数期望批量数据增加一个批量数据的维度
my_output_expanded = tf.expand_dims(my_output,0)
y_target_expanded = tf.expand_dims(y_target,0)
#增加非归一化logits的交叉熵的损失函数
loss = tf.nn.sigmoid_cross_entropy_with_logits( logits=my_output_expanded , labels=y_target_expanded )
#声明变量的优化器
global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.5 #初始学习率
learning_rate = tf.train.exponential_decay(initial_learning_rate,
global_step=global_step,
decay_steps=10,decay_rate=0.9)
my_opt = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_step = my_opt.minimize(loss)
#在运行之前,需要初始化变量
init = tf.initialize_all_variables()
sess.run(init)
num = 1000
step = np.zeros(num)
LOSS = np.zeros_like(step)
Learning_rate_vec = []
# 训练算法
for i in range(num):
rand_index = np.random.choice(100)
rand_x = [x_vals[rand_index]]
rand_y = [y_vals[rand_index]]
sess.run(train_step,feed_dict={x_data:rand_x,y_target:rand_y,global_step:i})
#打印
step[i]= i
LOSS[i] = sess.run(loss,feed_dict={x_data:rand_x,y_target:rand_y})
Learning_rate_vec.append(sess.run(learning_rate,feed_dict={global_step:i}))
if (i+1)%100 ==0:
print('step =' + str(i+1) +' A = '+ str(sess.run(A)))
print('loss =' + str(LOSS[i]) )
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(step,LOSS,label='loss')
ax.set_xlabel('step')
ax.set_ylabel('loss')
fig.suptitle('sigmoid_cross_entropy_with_logits')
handles,labels = ax.get_legend_handles_labels()
ax.legend(handles,labels=labels)
fig2 = plt.figure()
ax2 = fig2.add_subplot(111)
ax2.plot(Learning_rate_vec,'k-')
ax.set_xlabel('step')
ax.set_ylabel('Learning_rate')
fig.suptitle('Learning_rate')
plt.show()
# logdir = './log'
# write = tf.summary.FileWriter(logdir=logdir,graph=sess.graph)