Helm Chart安装EFK并验证功能
本文介绍如何通过Helm Chart方式快速在Kubernetes环境中搭建EFK(Elasticsearch,Filebeat,Kibana)V8.5.1 日志收集系统并验证其功能。如果仅对安装有兴趣请直接食用“EFK(Elasticsearch,Filebeat,Kibana)V8.5.1 安装”章节。
日志收集系统背景需求
随着现在各种软件系统的复杂度越来越高,特别是部署到云上之后,再想登录各个节点上查看各个模块的log,基本是不可行了。因为不仅效率低下,而且有时由于安全性,不可能让工程师直接访问各个物理节点。而且现在大规模的软件系统基本都采用集群的部署方式,意味着对每个service,会启动多个完全一样的POD对外提供服务,每个container都会产生自己的log,仅从产生的log来看,你根本不知道是哪个POD产生的,这样对查看分布式的日志更加困难。
所以在云时代,需要一个收集并分析log的解决方案。首先需要将分布在各个角落的log收集到一个集中的地方,方便查看。
几种主流的方案对比
- ELK(Elasticsearch,Logstash,Kibana)
- EFK(Elasticsearch,Filebeat,Kibana)
- EFK(Elasticsearch,Fluentd,Kibana)
这几种日志收集系统的优劣及适用场景网上有很多相关的介绍,我这里只做简单的比较。
a.ELK(Elasticsearch,Logstash,Kibana)对比 EFK(Elasticsearch,Fluentd,Kibana)
架构和适用性:
EFK:EFK架构是以Fluentd为中心的,通过Fluentd收集和传输日志数据到Elasticsearch,然后使用Kibana进行可视化和分析。EFK适用于复杂的日志收集和分析需求,尤其擅长处理大规模的日志数据。
ELK:ELK架构是以Logstash为中心的,通过Logstash收集、转换和传输日志数据到Elasticsearch,然后使用Kibana进行可视化和分析。ELK适用于中等规模的日志收集和分析需求,可以处理多种来源的数据。
组件和技术:
EFK:EFK代表Elasticsearch、Fluentd和Kibana。Elasticsearch是一个分布式搜索和分析引擎,用于存储和索引日志数据。Fluentd是一个开源的日志收集和传输工具,用于从不同来源收集和传输日志数据到Elasticsearch。Kibana是一个可视化工具,用于搜索、分析和可视化存储在Elasticsearch中的数据。
ELK:ELK代表Elasticsearch、Logstash和Kibana。Elasticsearch和Kibana的作用与EFK中相同。Logstash是一个开源的数据收集、转换和传输工具,用于收集、过滤和转换各种来源的数据,并将其发送到Elasticsearch。
配置和插件生态系统:
EFK:Fluentd拥有广泛的插件生态系统,可以方便地集成各种数据源和目标,并进行自定义插件开发。它的配置相对复杂,但也非常灵活。
ELK:Logstash也具有插件生态系统,但相对于Fluentd来说规模较小。Logstash的配置相对简单,主要通过配置文件进行配置。
性能和扩展性:
EFK:由于使用了Fluentd作为数据传输工具,EFK相对于ELK来说更轻量级、高性能和可扩展。Fluentd采用缓冲区机制来处理和缓存日志事件,具有更高的吞吐量和可扩展性。
ELK:由于使用了Logstash作为数据传输工具,ELK在处理大规模数据时可能会占用更多的资源,并且可能会对性能产生一定影响。但对于中等规模的日志收集和分析需求,ELK仍然能够提供良好的性能。
总结来说,当前EFK(Elasticsearch,Fluentd,Kibana)的性能&应用广泛度要高于ELK(Elasticsearch,Logstash,Kibana)
b.ELK(Elasticsearch,Filebeat,Kibana)对比 EFK(Elasticsearch,Fluentd,Kibana)
Fluentd 和 Filebeat 都是常用于日志收集的开源工具,它们可以帮助我们收集、处理和转发大量的日志数据。虽然它们都具有类似的功能,但是它们在设计理念和实现细节上有很大的不同。
Fluentd 是一个日志收集和聚合的工具,由 Treasure Data 公司开发和维护。它支持多种数据输入和输出,并提供了丰富的插件和过滤器来处理和转换数据。Fluentd 通过流水线的方式处理日志数据,可以灵活地构建复杂的数据处理流程。Fluentd 还提供了内置的缓存机制,可以减少数据丢失的风险。同时,Fluentd 是一个轻量级的工具,对系统资源的占用较小。
Filebeat 是 Elastic 公司开源的一款轻量级日志数据采集器,旨在收集、解析和转发各种类型的日志数据。它支持多种数据源,并且能够自动发现新的日志文件。Filebeat 具有较低的资源消耗,并且支持高可用性和故障转移。Filebeat 可以将日志数据转发到多个输出目的地,如 Elasticsearch、Logstash 或 Kafka 等。
两者在设计理念上的区别主要在于 Fluentd 更侧重于数据处理和转换,而 Filebeat 更侧重于数据采集和传输。因此,在选择使用哪种工具时,需要根据具体的场景和需求来考虑。
总体来说,Fluentd 更适用于需要进行复杂数据处理和转换的场景,而 Filebeat 则更适用于简单的日志数据采集和转发场景。如果你需要一个轻量级的工具来处理海量日志数据,Fluentd 可能会更合适;如果你只需要一个简单的日志采集器来快速收集和转发日志数据,那么 Filebeat 可能会更适合你的需求。
1. EFK(Elasticsearch,Filebeat,Kibana)V8.5.1 安装
1.1 前提条件
a. Helm版本>=v3.2.0,其中 Helm 的安装请参考:Helm Install
b.需要有默认的StorageClass,具体准备流程参考:Kubernetes安装StorageClass
c.(非必须)建议有默认的IngressClasses,具体准备流程参考:Kubernetes安装IngressClass 其中第4步“设置为默认Ingress Class”是必须的,同时Ingress的NodePort端口最好设置为80、443
1.2 安装流程
a.创建安装目录
#切换到当前用户根目录并建立logging文件夹
cd ~ && mkdir logging
cd logging
b.创建logging名字空间,独立的名字空间有助于资源管理
kubectl create ns logging
c.添加elastic官方repo仓库
helm repo add elastic https://helm.elastic.co
d.安装elasticsearch
如果需要做某些定制化需求请参考官方 values.yaml 文件,其中每个参数都会有详细描述: 官网参考
helm pull elastic/elasticsearch --version 8.5.1
tar -xvf elasticsearch-8.5.1.tgz
cd elasticsearch
#(非必要)以下的操作主要是修改elasticsearch服务暴露方式以及ingress设置
vi values.yaml
#搜索ClusterIP关键字
service:
enabled: true
labels: {
}
labelsHeadless: {
}
type: ClusterIP #将此处改为NodePort
# Consider that all endpoints are considered "ready" even if the Pods themselves are not
# https://kubernetes.io/docs/reference/kubernetes-api/service-resources/service-v1/#ServiceSpec
publishNotReadyAddresses: false
nodePort: ""
annotations: {
}
httpPortName: http
transportPortName: transport
loadBalancerIP: ""
loadBalancerSourceRanges: []
externalTrafficPolicy: ""
#搜索ingress关键字
ingress:
enabled: false #改为true
annotations: {
}
# kubernetes.io/ingress.class: nginx #取消注释
# kubernetes.io/tls-acme: "true" #取消注释
className: "nginx"
pathtype: ImplementationSpecific
hosts:
- host: chart-example.local
paths:
- path: /
执行安装命令
cd ~/logging
helm install elasticsearch ./elasticsearch -n logging
#成功后看到如下提示
NAME: elasticsearch
LAST DEPLOYED: Wed May 31 02:37:03 2023
NAMESPACE: logging
STATUS: deployed
REVISION: 1
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=logging -l app=elasticsearch-master -w
2. Retrieve elastic user's password.
$ kubectl get secrets --namespace=logging elasticsearch-master-credentials -ojsonpath='{
.data.password}' | base64 -d
3. Test cluster health using Helm test.
$ helm --namespace=logging test elasticsearch
#通过如下命令检测&确保Pod正确运行
kubectl get pods --namespace=logging -l app=elasticsearch-master -w
NAME READY STATUS RESTARTS AGE
elasticsearch-master-0 1/1 Running 0 3h10m
elasticsearch-master-1 1/1 Running 0 3h10m
elasticsearch-master-2 1/1 Running 0 3h10m
e.安装Filebeat
官网参考
cd ~/logging
helm pull elastic/filebeat --version 8.5.1
tar -xvf filebeat-8.5.1.tgz
执行安装命令
helm install filebeat ./filebeat -n logging
#成功后看到如下提示
NAME: filebeat
LAST DEPLOYED: Wed May 31 02:55:52 2023
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Watch all containers come up.
$ kubectl get pods --namespace=logging -l app=filebeat-filebeat -w
#通过如下命令检测&确保Pod正确运行
kubectl get pods --namespace=logging -l app=filebeat-filebeat -w
NAME READY STATUS RESTARTS AGE
filebeat-filebeat-asdn6 1/1 Running 0 3h6m
filebeat-filebeat-sdab4 1/1 Running 0 3h6m
filebeat-filebeat-asbvg 1/1 Running 0 175m
f.安装kibana
官网参考
cd ~/logging
helm pull elastic/kibana --version 8.5.1
tar -xvf kibana-8.5.1.tgz
cd kibana
vi values.yaml
#对外暴露方式设置为NodePort,搜索ClusterIP关键字
service:
type: ClusterIP #此处修改为NodePort
loadBalancerIP: ""
port: 5601
nodePort: ""
labels: {
}
annotations: {
}
# cloud.google.com/load-balancer-type: "Internal"
# service.beta.kubernetes.io/aws-load-balancer-internal: 0.0.0.0/0
# service.beta.kubernetes.io/azure-load-balancer-internal: "true"
# service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
# service.beta.kubernetes.io/cce-load-balancer-internal-vpc: "true"
loadBalancerSourceRanges: []
# 0.0.0.0/0
httpPortName: http
#(非必须)设置ingress地址,搜索ingress关键字
ingress:
enabled: false #修改为true
className: "nginx"
pathtype: ImplementationSpecific
annotations: {
}
# kubernetes.io/ingress.class: nginx #取消注释
# kubernetes.io/tls-acme: "true" #取消注释
hosts:
- host: kibana-example.local
paths:
- path: /
执行安装命令
cd cd ~/logging
helm install kibana ./kibana -n logging
#成功后看到如下提示
NAME: kibana
LAST DEPLOYED: Wed May 31 03:16:37 2023
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Watch all containers come up.
$ kubectl get pods --namespace=logging -l release=kibana -w
2. Retrieve the elastic user's password.
$ kubectl get secrets --namespace=logging elasticsearch-master-credentials -ojsonpath='{
.data.password}' | base64 -d
3. Retrieve the kibana service account token.
$ kubectl get secrets --namespace=logging kibana-kibana-es-token -ojsonpath='{
.data.token}' | base64 -d
#通过如下命令检测&确保Pod正确运行
kubectl get pods --namespace=logging -l release=kibana -w
NAME READY STATUS RESTARTS AGE
kibana-kibana-234897xx1c-h38ncj 1/1 Running 0 177m
2. 功能验证
2.1 图形化界面登陆
a.获取 kibana service NodePort 端口号
kubectl get svc -n logging | grep kibana
kibana-kibana NodePort 172.16.67.29 <none> 5601:30239/TCP 3h3m
看到端口号为19812
b.获取 kibana 界面登录密码
在通过Helm Chart成功安装kibana后可以看到提示:
Retrieve the elastic user’s password.
$ kubectl get secrets --namespace=logging elasticsearch-master-credentials -ojsonpath=‘{.data.password}’ | base64 -d
kubectl get secrets --namespace=logging elasticsearch-master-credentials -ojsonpath='{.data.password}' | base64 -d
54iEaxD2AFE838H
c. 图形话界面登录,默认的用户名为“elastic”
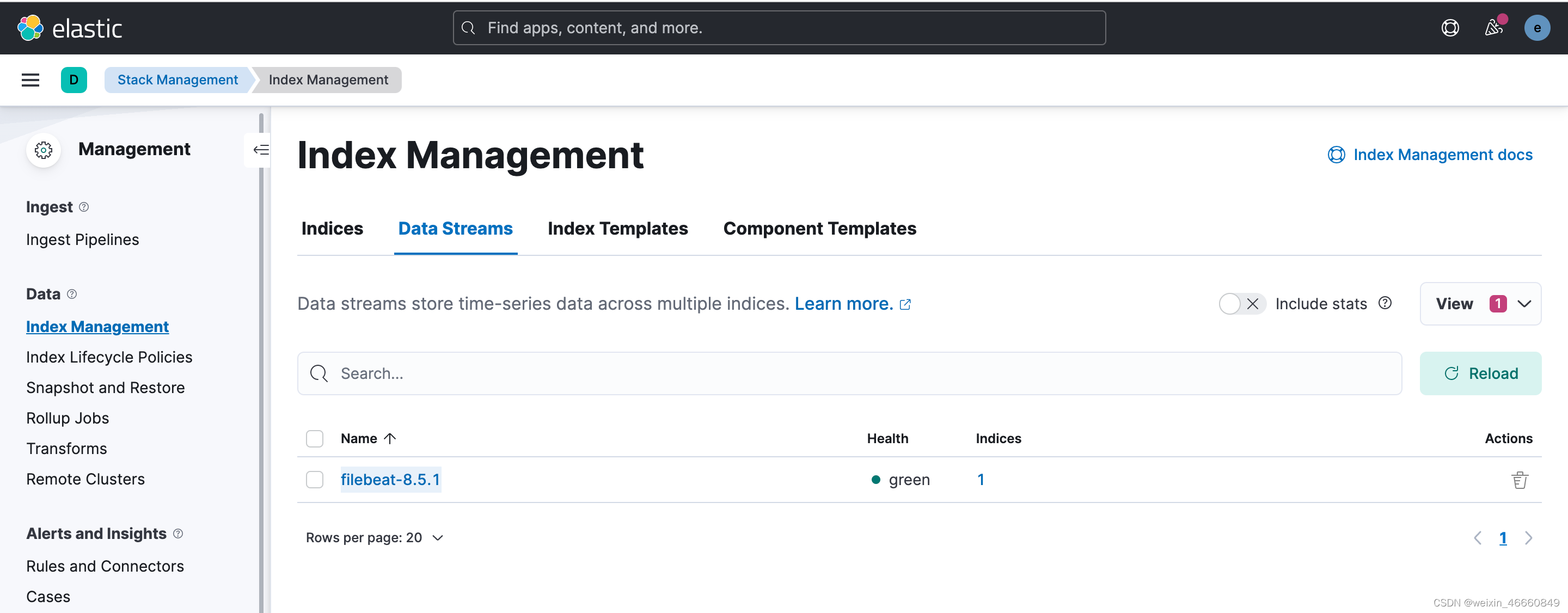
进入 Index Management 中的 Data Streams 中可以看到 filebeat-8.5.1 已被列为数据索引项目
2.2 日志收集验证
a.创建一个生产日志的Pod
cd ~/logging
vi test-logging-pod.yaml
#写入如下内容
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
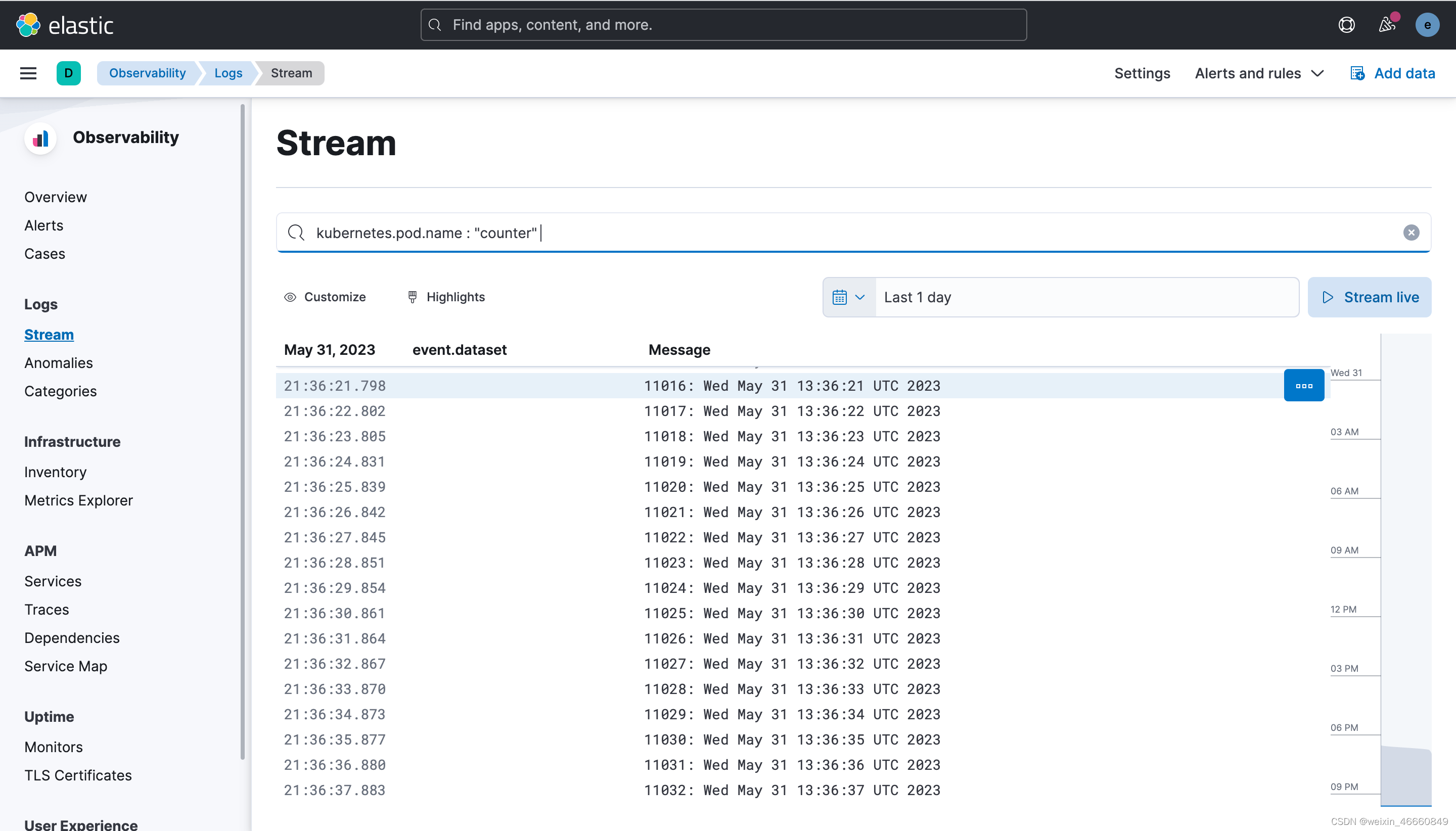
b.界面中查看 Observability->Logs->Stream 栏位下