源自:信息与控制
作者:闫於虎 王永雄 潘志群
摘 要
显著性目标检测中学习有效的全局卷积特征至关重要。卷积神经网络模型越深越能获得更好的全局感受野, 但这样往往会丢失局部信息, 还会导致目标边缘粗糙。为了解决这个问题, 引用了一个新的基于注意力的编码器Vision Transformer, 相比于CNN (convolutional neural network)而言, 可以表示浅层到深层的全局特征, 并建立图像中各区域的自注意力关系。具体地, 首先采用Transformer编码器提取目标特征, 编码器在浅层中保留了更多的局部边缘信息, 以恢复最终显著图的空间细节。然后, 利用Transformer编码器前后层之间继承的全局信息, 将Transformer每一层输出特征最终预测。在此基础上, 浅层的边缘监督以获取丰富的边缘信息, 再将浅层信息与全局位置信息相结合。最后, 在解码器中采用渐近融合的方式生成最终显著性图, 促进高层信息和浅层信息地充分融合, 更准确地定位显著目标及其边缘。实验结果表明, 在5个广泛使用的数据集上, 在不进行任何后处理的情况下, 提出的方法性能好于最先进的方法。
关键词
Transformer, 显著性检测, 边缘监督, 渐近融合
引 言
人类视觉系统具有从视觉场景中选择最重要信息的有效注意力机制,而显著性目标检测则是模仿人类这一行为,旨在定位图像中最具视觉特色的目标。图像显著性目标检测作为一种预处理手段,在图像处理和计算机视觉的各个领域中均得到了成功且广泛的应用。例如,目标识别[1]、视觉跟踪[2]、图像检索[3]等。
早期的研究主要基于颜色对比、纹理对比来定位显著物体,虽然取得了一定的进展,但是由于手工特征通常缺乏全局信息,因此很难准确地定位显著物体。随着近几年深度学习的发展,卷积神经网络(convolutional neural network,CNN)[4]实现了端到端的学习,特别是近几年全卷积神经网络(fully convolutional network,FCN)[5]的出现,逐渐取代了传统的显著性检测方法。然而,由于FCN的局部性,基于FCN的方法经常面临全局特征和局部特征之间的权衡。若要对高层信息进行编码,模型需要堆叠众多的卷积层来扩大感受野,但这会丢失局部信息,损失边缘信息,造成边缘模糊等。ZHANG等[6]提出了双向信息传递网络来更好的融合多层特征。LIU等[7]设计了有效的池化操作捕获更多的特征信息。PANG等[8]设计了AIM(aggregate interaction module)模块提取相邻特征之间的信息,他们还设计了SIM(self-interaction module)模块从单层特征中提取多层特征信息以获得更多的特征信息。陈凯等[9]基于特征金字塔网络和注意力机制提出一种结合空间注意力的多层特征融合显著性检测模型。WEI等[10]考虑到特征之间的差异性,设计了CFM(cross feature module)模块,用像素乘法尽可能地避免引入噪声。XIE等[11]在HED(holistically-nested edge detection)的基础上提出了短连接方式融合高层特征和低层特征,从而解决尺度空间问题。这些方法一定程度上影响全局和局部信息地融合效率。针对显著图边界粗糙等问题,人们提出了众多方法来解决此问题。肖传民等[12]首先使用Canny算法进行边缘检测,然后融合3种基本边缘特征用于提取图像中显著性边缘。LUO等[13]提出了基于U-Net的体系结构,其包含IoU(intersection over union)边缘损失,利用边缘线索检测显著目标。LI等[14]通过生成对象的轮廓获得显著实例的分割结果。ZHANG等[15]提出了新的结构损失函数以准确预测显著图的边界。
受ViT(Vision Transformer)[16]的启发,本文放弃传统的基于CNN的方法,引入了Transformer编码器,Transformer为每一层应用自注意力机制来学习全局特征,在保持局部特征的同时,在浅层中注入全局信息,因此具有强大的全局和局部信息获取能力。ZHENG等[17]设计了基于Transformer的显著性检测方法,通过序列化图像和利用Transformer框架来实现完全注意力的特征表示编码器。LIU等[18]在Transformer骨干网络基础上,提出了新的上采样方法,设计了多任务解码器联合执行显著性和边界检测。
尽管上述方法已经达到了非常好的效果,但是依然存在边缘模糊或定位不准确等问题。因此,本文在Transformer的基础上加入边缘监督信息,使得显著物体的边缘部分更加清晰。浅层保存了更好的局部边缘信息,但是要获得显著性目标的边缘特征,仅靠局部信息是不够的,还需要高级语义信息或位置信息[19]。本文设计了边缘引导模块将浅层信息和高层信息融合,从而生成准确的边界图。此外,还设计了新的解码器,通过渐近融合的方式有效地将高层信息和低层信息融合,进而可以更加准确地定位显著性物体。
1 结合Transformer的显著性目标检测网络
模型整体框架如图 1所示。本文模型主要由边缘监督和渐近融合两个模块组成。边缘监督信息准确定位显著物体的边界,采用渐近融合方式有效融合高层信息和浅层信息,进而产生高质量的显著图。

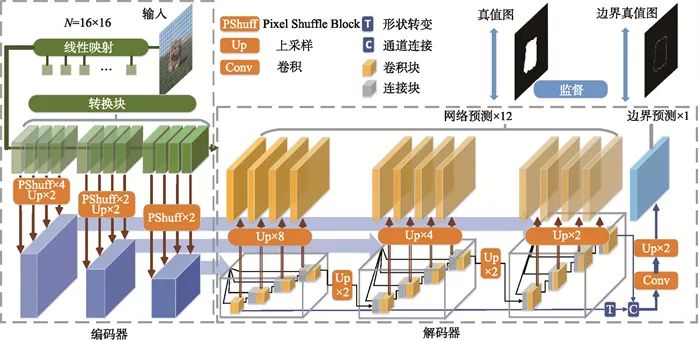
1.1 编码器
本文输入图片大小为384×384,由于Transformer的输入是1维序列,所以要先将2维图像转化为1维序列。受ViT启发,先将输入图像y分割为
![]()
个非重叠的分辨率为16×16的图像块,N表示维度,H、W分别是图像的高和宽,序列长度L为
![]()
,每一个键在序列y′中都表示为一个非重叠的16×16的图像块。由于Transformer编码器拥有位置编码信息和具有多头注意力和多层感知器的编码层,所以,本文将Transformer作为骨干网络。其结构如图 2右侧所示。
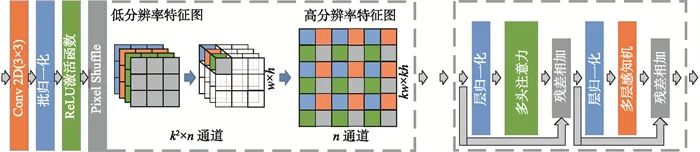
由于注意力机制无法区分位置差异,所以第一步应该将位置信息嵌入到序列y′得到位置增强特征F:
![]()
(1)
其中,EP表示在截断高斯分布下随机初始化的位置编码信息,“+”表示加法操作。
Transformer编码器包含12层,每一层包含多头自注意力(MSA)和多层感知器(MLP)。多头自注意力是自我注意力(SA)的延伸:
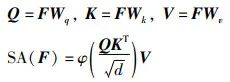
其中,F指自注意力的输入特征,Wq、Wk、Wv是具有可训练参数的权重;d为Q、K、V的维数,φ为softmax激活函数。为了并行应用多个注意力,多头自注意力具有m个独立的自注意力:
![]()
(3)
“⊕”表示concat操作,综上所述,在第i个Transformer层中,输出特征F为
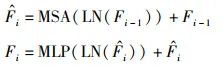
其中,LN (·)为层归一化,Fi 是Transformer第i层的特征。
1.2 边缘监督
利用边缘监督模块建立显著边缘信息的模型,并提取显著边缘特征。浅层保留了更好的边缘信息。然而,要获得显著的边缘特征,仅靠局部信息不够,还需要高级语义信息或位置信息。一般地,顶层的感受野最大,位置最准确。因此,如图 1所示,本文设计了一个自顶向下的位置传播,将富含高层信息的最后一层上采样操作后与富含浅层信息的第一层结合,以增强边缘特征。此方法可以更准确地定位显著物体的轮廓,进而准确地捕获显著物体,融合特征可表示为
![]()
(5)
其中,C1表示第一层的特征信息,其中Trans(F12;θ) 是带有参数θ的卷积层,目的是改变特征的通道数,而R(·)表示ReLU激活函数;UP(F12;C1)为上采样操作,其目标为将F12上采样到与C1相同的大小。在边缘部分,本文采用标准二元交叉熵损失函数:
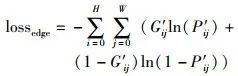
其中,H、W分别是图像的高和宽,P′ij为边缘显著图,G′ij为边缘真值图。
1.3 渐近融合
渐近融合模块用于融合高层信息与浅层信息。渐近融合方式不但可以缓解高层信息传递过程中特征稀释的问题,而且这种方式可以更加有效地融合高层信息与浅层信息。本文将Transformer层的特征逐层上采样至与输入图片相同的分辨率大小。本文没有单独采用传统的双线性插值上采样,而是结合了一种新型的上采样方式:Pixel-shuffle上采样操作[20]。
在卷积操作中,通常都会将卷积之后的图像经过上采样之后恢复到原图像的大小,在传统CNN中,多数采用双线性插值方法进行计算,但会引入参数,增加计算复杂度。而Pixel-shuffle也是一种上采样操作,以放大输入特征图的尺寸,减少通道数。它不是直接通过插值等方式产生高分辨率图片,而是通过卷积先得到k2个通道的特征图,然后通过周期筛选的方法得到高分辨图像。子像素卷积作为上采样第一步用来捕获更丰富的空间特征,子像素卷积通过像素打乱对每个通道的像素进行重排列,得到一个全新的特征图。如图 2左侧所示,如果原图像形状为w×h×(k2×n),w、h、k2×n分别为图像的宽度、高度、通道数,k为图像放大倍数,经过Pixel-shuffle操作之后,特征图的形状为kw×kh×n。
为了更有效地融合Transformer层的特征信息,降低直接上采样带来的噪声,先将12个输出特征分为3个阶段,自第1阶段到第3阶段分别上采样,如图 1所示,这里的上采样包括Pixel-shuffle操作和常规上采样操作。在第i层,特征F′i与上一层特征F′i+1上采样后concat融合后经过卷积操作得到特征F″i。最后一层特征F′12直接上采样后卷积得到特征F″12。融合公式如下:
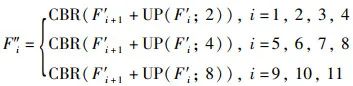
其中,“CBR”表示卷积、批归一化、ReLU激活函数操作。
然后,每一层特征经过一系列卷积操作得到与输入图像相同大小的图像,共有12个输出特征图,将最后一层的特征图作为最终显著性图。本阶段的损失函数为
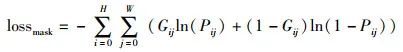
(8)
其中,Pij为显著图,Gij为真值图,本阶段共有12个损失函数。因此,本文最终损失函数为
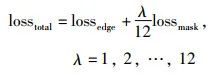
2 实验和结果分析
2.1 实施细节
在常规的DUTS数据集上训练模型[21]。Transformer编码器参数是在ImageNet数据集上预训练权重初始化,其余参数在Pytorch设置中随机初始化,使用SGD(stochastic gradient descent)优化器训练网络,设置momentum=0.9,权重衰减为0.000 5。学习率从0.001逐渐衰减至0.000 01,训练共计40个epoch,batch size=2。训练中对训练数据进行垂直、水平翻转等数据增强技术提高模型鲁棒性,输入图片统一裁剪为384×384。在测试阶段,将最后一层的输出作为预测的显著性图。本文采用NVIDIA GTX TITAN Xp×2 GPU硬件平台和Pytorch深度学习框架。
2.2 数据集及评价指标性能对比
在5个广泛应用的公共数据集上评估本文的模型:DUTS-TE[22]、ECSSD[23]、HKU-IS[24]、DUT-OMRON[25]、PASCAL-S[26]。DUTS-TE是评价显著性检测最大的一个数据集,包含10 553张训练图片和5 019张测试图片。ECSSD包含1 000张不同场景下特征信息丰富的图片。HKU-IS有4 447张在低对比度场景下或多目标的图片。数据集DUT-OMRON则包含5 168张高质量的图片,它包含复杂背景或者至少一个显著目标。PASCAL-S包含850张从PASCAL VOC中挑选出来的自然图片。
为了更好地验证本方法的有效性,选择了常见的3个评价指标来评估本文的模型,分别是:平均绝对误差(MAE),F-measure(Fβ),S-measure(Sm)。不同的阈值可以得到不同的准确率和召回率,所以P-R曲线可以全面地评估预测结果。MAE是平均绝对误差,用于衡量显著图和真值图(GT)之间的相似性:
![]()
(10)
其中,P表示的是预测的显著性图,G是相应的真值图,H、W分别是显著图的高和宽。另一个评价指标Fβ是准确率和召回率的加权调和平均值,可以全面地反应准确率和召回率的关系,定义如下:
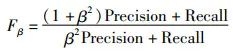
(11)
其中,β2通常设置为0.3来增加准确率的权重。S-measure反映前景和背景之间的联系,可以衡量显著图和真值图之间的结构一致性,定义如下[27]:
![]()
(12)
其中,Sα表示目标相似性,Sβ表示区域相似性,λ通常设置为0.5来平衡Sα与Sβ之的关系。
2.3 性能对比
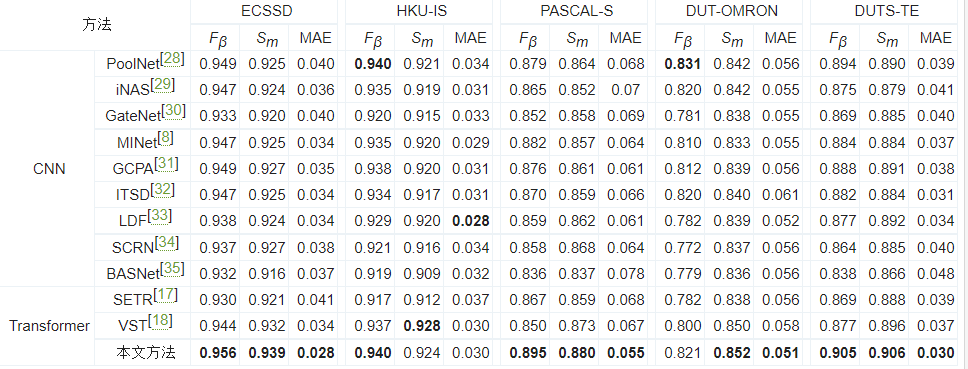
为了更好地验证所提方法的有效性,本文对比了11个主流的显著性检测方法。表 1显示了12种方法在3个评价指标上的评价结果。从实验结果中可以看出,在没有使用任何后处理的情况下,无论是相比基于CNN方法还是相比基于Transformer方法,提出的方法都有很大的优势。如表 1数据可得,当使用Transformer作为骨干网络提取特征时,评价结果要优于将CNN作为骨干网络的方法,这也说明了Transformer中自注意力机制能够更加有效地提取全局特征。特别是在ECSSD、PASCAL-S、DUTS-TE数据集上,评价结果都达到了最优,验证了所提方法的有效性。例如在ECSSD数据集上,MAE指标比最好的LDF方法提高了17.64%。在具有低对比度和多目标的大型数据集DUTS-TE上,Fβ得分提高了12.15%,说明了在面对复杂目标时提出的方法能够准确地分割出显著物体。在5个大型数据集上对模型的验证结果如表 1中所示,表中数据验证了模型具有一定的泛化性、鲁棒性。
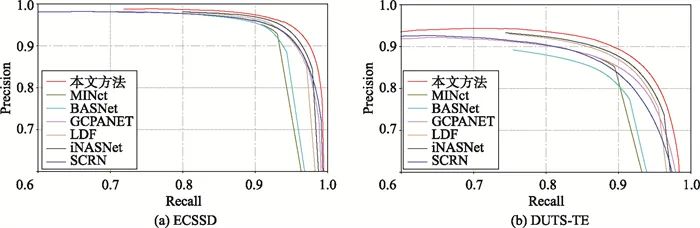
为了更直观地验证所提方法的有效性,图 3展示了不同场景下9个方法的可视化结果。提出的方法在捕获显著性物体中取得了突出的结果。此外,得益于渐近融合策略的有效性,在包含多个显著目标的场景中,提出的方法可以更全面地检测所有目标。如图 3第1行,在面对低对比度场景下,提出的方法也能准确定位显著物体。在小目标、复杂场景中,本文结果可以更好地屏蔽背景噪声,准确捕获显著物体,如图 3第4行。值得一提的是,得益于引入显著边缘特征,本文结果不仅可以突出显著区域,而且还可以产生连贯的边缘,例如在第2行和第6行中,本文方法可以更加准确地定位显著物体及其边界。从第7行的比较结果可以看出,本文方法在面对多目标时能够准确区分容易混淆的对象。总之,本文方法在多场景图像、多目标图像、低对比度图像、和复杂场景中表现突出,充分说明了本文方法的有效性。此外,还绘制了在DUTS-TE和ECSSD数据集上不同方法的精度召回曲线图。如图 4所示,实红线表示所提方法在大多数阈值上优于其他方法。由于互补的显著边缘信息的帮助,具有清晰的边缘信息和精确的定位,从而P-R曲线中的结果更好。

2.4 消融实验
以DUTS-TR作为训练集,本节探讨了在大型数据集DUTS-TE上所提网络中不同组件的影响,测试结果如表 2所示。BASNet为Transformer编码器最后一层直接解码所得,由此可知当直接将最后一层上采样时获得的效果并不不好,这种不准确可能是因为直接上采样会损害全局信息和局部信息所导致的。当使用渐近融合的方式时,可以看到MAE

指标有了显著提升,这是因为渐近融合可以有效地融合高层信息和局部信息。结合边缘监督也可以使得效果提升,这是因为监督信息可以更好地定位显著物体的边缘。两种方式都使得检测效果有了一定的提升,当将两者结合起来时,精度又有了进一步的提升。这证明了两者是互补和有效的。
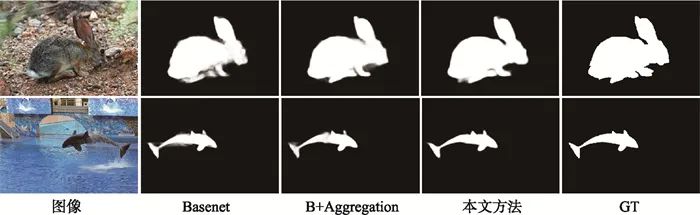
除了定量分析外,本文还通过可视化验证各个模块的作用,如图 5所示,将最后一层直接解码时,得到的显著图较模糊,这是因为这种操作损害了全局信息和局部信息的融合。当加上渐近融合模块(Aggregation)时,来自高层的全局语义信息和浅层的位置信息相互融合,能够更加准确地定位显著物体。在显著边缘特征的帮助下,显著目标的边缘和定位得到了改善。通过可视化再一次验证了本文方法的有效性。
3 结论
本文提出了一个新的基于Transformer的显著性检测方法,克服了传统卷积神经网络的局限性,引入Transformer编码器提取特征,解决了深度模型丢失局部信息的问题,其次,利用边缘监督,得到更准确的边缘特征。在解码器中,采用渐近融合的方式将高层信息与浅层信息有效地融合,进而得到较为准确的特征图。在没有任何后处理的情况下,在5个广泛使用的数据集上的实验结果证明了提出模型的综合性能以及各个模块的有效性,具有一定的泛化性和鲁棒性。下一步研究工作需对深度卷积神经网络或Transformer本身的结构进行改进,设计更加有效的融合模块,使显著目标定位及其边缘更加准确。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询” 发布