本文主要对SOD领域内的主要模型方法、数据集、评估方法和数据集做了一定的总结报告,部分内容源自于相关论文和网站博客内容。
一、介绍
显著性检测通常分为眼动点检测和显著目标检测。显著目标检测(SOD)的目的是突出图像中的显著目标区域。而显著性检测的另一个任务凝视点检测(fixation prediction)则起源于认知和心理学研究,与眼动点检测不同的是,显著目标检测更多的受不同领域的应用驱动:比如,在CV研究中,SOD可以应用于图像理解,图像描述,目标检测,无监督的视频目标分割,语义分割,行人重识别;在计算机图形学中,SOD可以应用于非真实性渲染,图像自动裁剪,图像重定位,视频摘要;在机器人领域中,可用于人机交互和目标发现等。在我们的工程项目中,360VR领域内可以针对用户所关注的兴趣区域,对该区域进行着重渲染,不仅可以降低带宽消耗,还可以在有限的带宽限制下提升用户体验。
二、深度显著目标检测模型
(1)基于多层感知机(MLP)的模型
-
MACL:传统SOD方法对于背景对比度低并且容易造成视觉混淆的图像不能产生好的显著性划分。针对此问题,该网络模型使用两个路径从两个超像素不同的窗口中提取局部和全局上下文,随后在同一的混合文本深度学习框架中联合建模。
-
ELD:使用VGG-net提取高级特征,低级特征与图像的其他部分进行比较生成低级距离图,然后使用具有多个1x1卷积和ReLU层的卷积神经网络(CNN)对低级距离图进行编码。我们将编码过的低级距离图和高级特征连接,并将它们送入全卷积网络分类器去评估显著区域。
-
MAP:我们的目的是在无约束图像中的检测显著性目标。在无约束的图像中,显著目标的数量因图像而异。我们提出了一个显著性目标检测系统,直接为输入图像输出一组紧凑的检测窗口。我们的系统利用CNN来生成显著对象的位置建议。位置建议往往是高度重叠和嘈杂的。基于最大后验准则,我们提出了一种新的子集优化框架来从杂乱建议中生成一组紧凑的检测窗口。
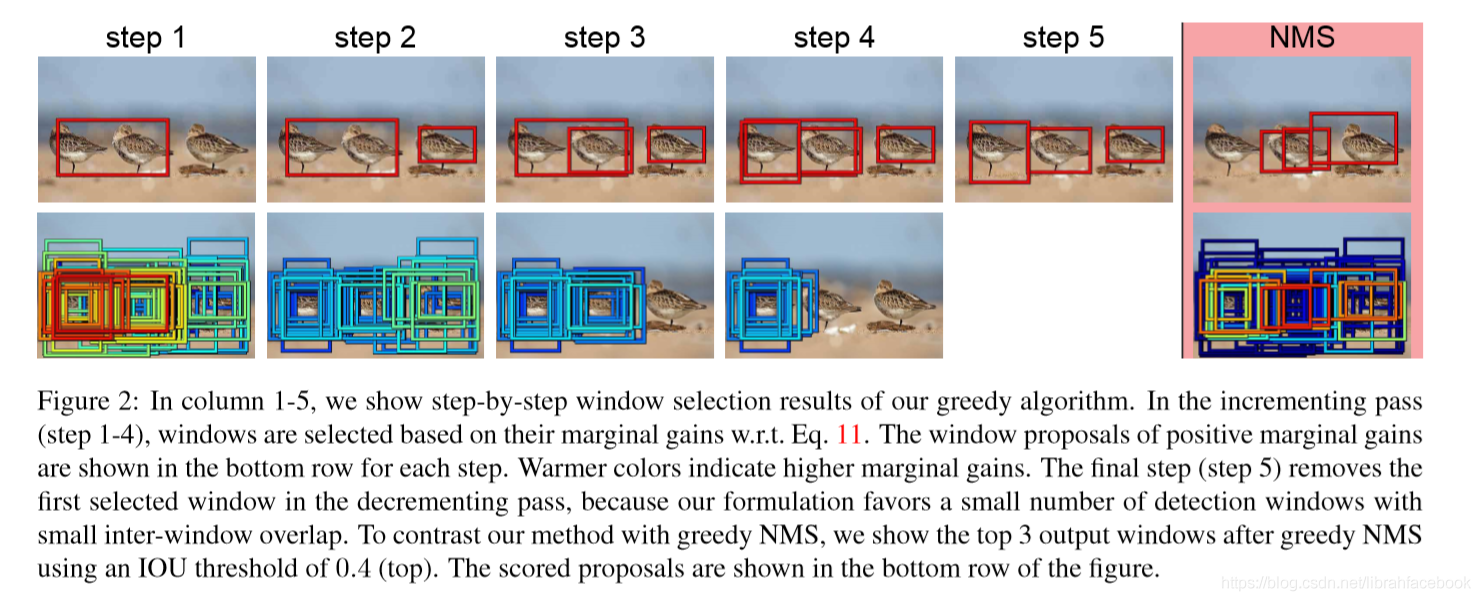
(2)基于全卷积网络(FCN)的模型
-
RFCN:现在PASCAL VOC2010分段数据集上进行了预训练,以学习语义信息,然后调整到SOD数据集以预测前景和背景。显著性图是前景和背景分数的softmax组合。我们通过使用循环完全卷积网络(RFCN)开发新的显著性模型更进一步。此外循环结构使我们的方法能够通过纠正先的错误自动学习优化显著性映射。为了训练具有多个参数的网络,我们提出了使用语义分割数据的预训练策略,其同时利用对分割任务的强有力的监督来进行更好的训练,并使网络能够捕获对象的通用表示以用于显著性检测。
-
FSN:受到人类观察事物的启发,显著物体通常会获得人们的视觉关注,将眼睛注视流和语义流的输出融合到初始分割模块中以预测显著性。
(3)基于混合网络的模型,利用多尺度上下文产生边缘保留检测
-
DCL:该网络包括两个部分,一个是像素级的全卷积流和片段级的稀疏池化流。第一步产生一个显著图,第二步产生片段级特征和显著性间断点。最后一个全连接CRF模型可以进行合并改善。
-
CRPSD:结合了超像素级和超级像素级别显著性。前者是通过融合FCN的最后和倒数第二侧输出特征生成的,而后者是通过将MCDL应用于自适应生成区域而获得的。只有FCN和融合层是可以进行训练的。
(4)利用金字塔扩张卷积结构和ConvLSTM的结合模型
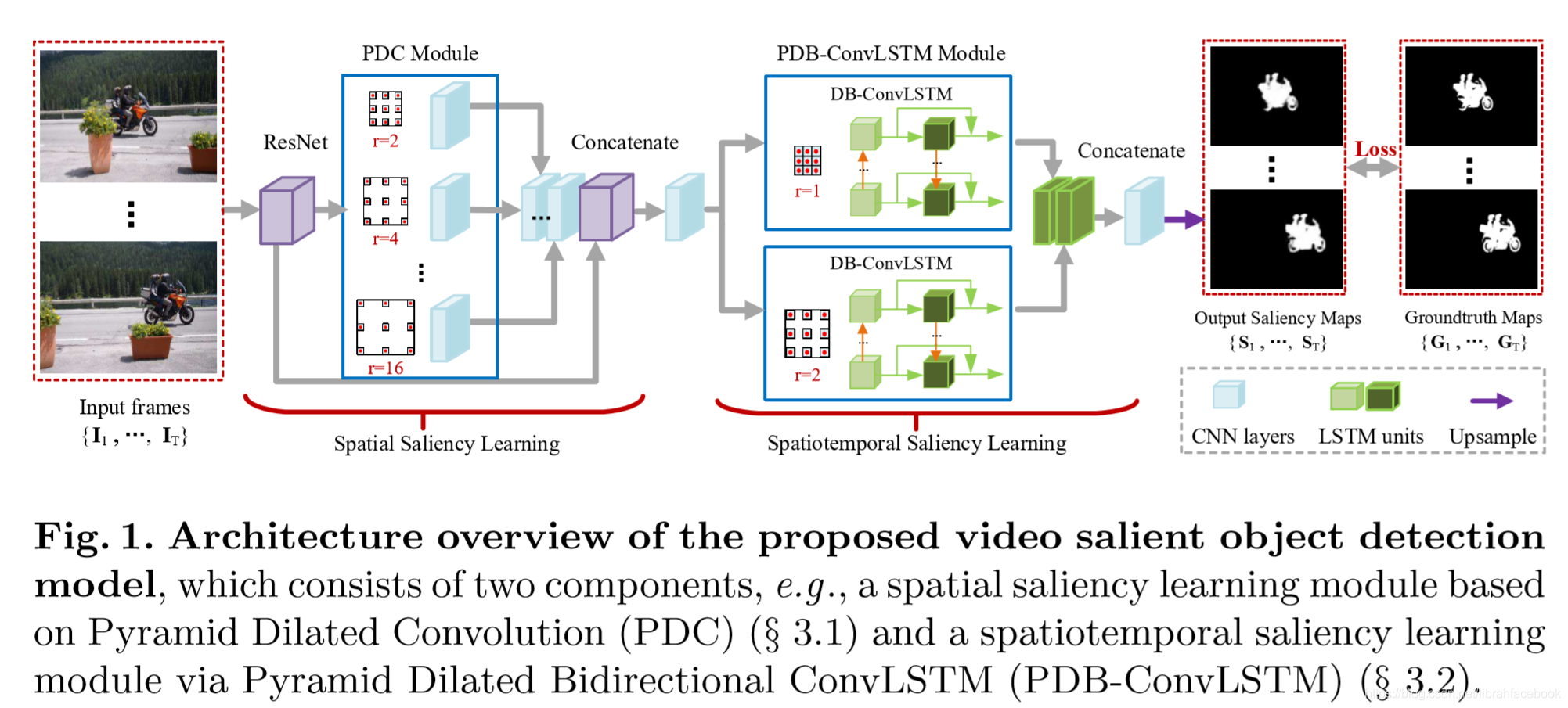
- PDB-ConvLSTM:由PDC模块和PDB-ConvLSTM模块组成。在PDC模块中,一组并行的扩张卷积被用来提取多尺度的空间特征。在PDB-ConvLSTM模块中,卷积ConvLSTM被更深的信息提取和并行的两个ConvLSTM来扩展,从而提取不同尺度的序列特征。
- SSAV:由两部分组成,金字塔扩张卷积(PDC)模块和显著性转移感知ConvLSTM(SSLSTM)模块。前者用于有效的静态显著性学习,后者用于同时捕获时间动态和显著性转换。
三、显著目标检测数据集
(1)早期包含简单场景的SOD数据集
-
MSRA-A (Learning to detect a salient object) 包含从各种图像论坛和图像搜索引擎收集的20,840张图像。 每个图像都有一个清晰,明确的对象,相应的注释是三个用户提供的边界框由“少数服从多数”选择制定。
-
MSRA-B (Learning to detect a salient object) 作为MSRA-A的一个子集,有由9个用户使用边界框重新标记的5000个图像。与MSRA-A相比,MSRA-B的模糊度较低。 突出的对象。 MSRA-A和MSRA-B的性能变得饱和,因为大多数图像仅包括围绕中心位置的单个且清晰的显着物体。
-
SED(Image Segmentation by Probabilistic Bottom-Up Aggregation and Cue Integration) 包括单个对象子集SED1和双个对象子集SED2,每个子集包含100个图像并具有逐像素注释。 图像中的物体通过各种低级线索(例如强度,纹理等)与周围环境不同。每个图像由三个主体分割。,如果至少两个主体同意,则将像素视为前景。
-
ASD(Frequency-tuned Salient Region Detection) 包含1,000个逐像素真值。 从MSRA-A数据集中选择图像,其中仅提供显着区域周围的边界框。 ASD中的精确突出掩模是基于对象轮廓创建的。
(2)最近流行的SOD数据集
-
SOD (Design and perceptual validation of performance measures for salient object segmentation) 包含来自伯克利分割数据集的120张图像。每个图像由七个主题标记。许多图像具有多个与背景或与图像边界形成低色彩对比度的显著对象。提供像素注释。
-
MSRA10K(Frequency-tuned Salient Region Detection) 也称为THUS10K,包含从MSRA中选择的10,000张图像,涵盖了ASD中的所有1,000张图像。 图像具有一致的边界框标记,并且进一步使用像素级注释进行扩充。 由于其大规模和精确的注释,它被广泛用于训练深SOD模型(见表2)。
-
ECSSD(Hierarchical saliency detection) 由1000个图像组成,具有语义上有意义但结构复杂的自然上下文。 真值由5名参与者注释。
-
DUT-OMRON(Saliency detection via graph-based manifold ranking) 包含5,168张背景相对复杂和内容多样性的图像。 每个图像都伴有像素级真值注释。
-
PASCAL-S(The secrets of salient object segmentation) 由从PASCALVO 2010的VAL集合中选择的850个具有挑战性的图像。除了眼动点记录外,还提供了粗略的像素和非二值显著目标注释。
-
HKU-IS(Visual saliency based on multiscale deep features) 包含4,447个复杂场景,其通常包含具有相对不同空间分布的多个断开连接的对象,即,至少一个显著对象接触图像边界。 此外,类似的前/后地面外观使这个数据集更加困难。
-
DUTS(Learning to detect salient objects with image-levels supervision) 最大的SOD数据集,包含10,553个训练和5,019个测试图像。 训练图像选自ImageNet DET 训练集/值集,以及来自ImageNet测试集和SUN数据集的测试图像。 自2017年以来,许多深度SOD模型都使用了DUTS训练集训练。
(3)当前实验所用数据集
- DAVSOD:我们根据真实的人类注视点来标注显著的对象,并且首次标注了注意力转移所发生的时刻,强调了该领域中显著性转移这一更具挑战的任务。它具有以下几个重要特征:丰富多样的显著对象,显著对象实例的数量更多,显著对象的尺寸变化范围更广,具有多样化的相机运动模式,不同的对象运动模式,中心偏向。
四、评估指标
- Precision-Recall(PR):根据二值化显著mask和真值来计算, 为了获得二进制掩码,应用一组范围从0到255的阈值,每个阈值产生一对精确/召回率来形成用于描述模型性能的PR曲线。
- F-measure:通过计算加权调和平均值来全面考虑精度和召回, . 根据经验一般所设定为0.3,来更加强调精度的影响。另一些方法使用自适应阈值,即预测显著图的平均值的两倍,以生成二元显著性映射并报告相应的平均F-measure值。
- Mean Absolute Error(MAE):用于通过测量归一化映射和真值掩码之间平均像素方向的绝对误差来解决这个问题。 .
- Structural measure(S-measure):用以评估实值显著性映射与真实值之间的结构相似性,其中So和Sr分别指对象感知和区域感知结构的相似性。 .
五、当前最先进的VSOD模型在数据集上的评测结果
- 37种最有代表性的VSOD模型总结:

- 17种最先进的VSOD模型在7个数据集上的表现结果

- 在所提出的DAVSOD数据集上的视觉表现结果
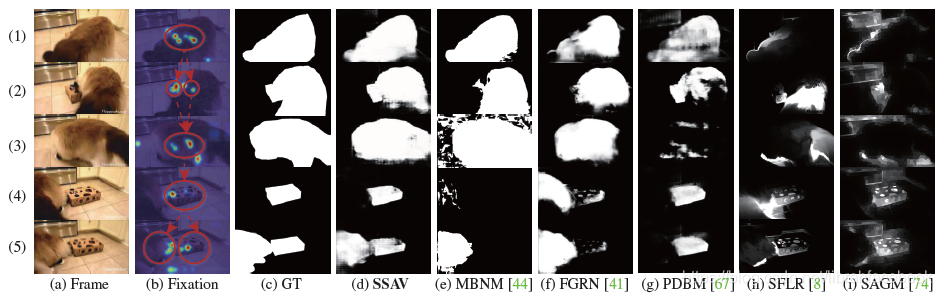
六、结论
在基于视频的显著性目标检测方面,最终的模型训练和测试效果主要由两个因素所决定:(1)数据集内容丰富度和标注细化度;(2)使用网络模型的主要结构,一般我们将其划分成两部分,第一个部分用来对静态图像的特征进行提取,可以通过扩张卷积来进行多尺度提取,第二个部分用来对连续视频帧序列的相关特征进行划分提取。随着SOD在计算机视觉领域的应用范围增长,其数据集和算法也会呈现较大程度的提高,更加接近于人工标注的显著性映射。
参考文献
1: https://www.cnblogs.com/imzgmc/p/11072100.html
2: Zhao R, Ouyang W, Li H, et al. Saliency detection by multi-context deep learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 1265-1274.
3: Lee G, Tai Y W, Kim J. Deep saliency with encoded low level distance map and high level features[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 660-668.
4: Zhang J, Sclaroff S, Lin Z, et al. Unconstrained salient object detection via proposal subset optimization[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 5733-5742.
5: Wang L, Wang L, Lu H, et al. Saliency detection with recurrent fully convolutional networks[C]//European conference on computer vision. Springer, Cham, 2016: 825-841.
6: Chen X, Zheng A, Li J, et al. Look, perceive and segment: Finding the salient objects in images via two-stream fixation-semantic cnns[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1050-1058.
7: Li G, Yu Y. Deep contrast learning for salient object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 478-487.
8: Tang Y, Wu X. Saliency detection via combining region-level and pixel-level predictions with CNNs[C]//European Conference on Computer Vision. Springer, Cham, 2016: 809-825.
9: Song H, Wang W, Zhao S, et al. Pyramid dilated deeper convlstm for video salient object detection[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 715-731.
10: Fan D P, Wang W, Cheng M M, et al. Shifting more attention to video salient object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2019: 8554-8564.
