声明:以下部分图片来源于网上
业务背景
现在越来越多的互联网应用都在提供基于地理位置的服务,假设现在有这样一个业务场景,加油站想要知道附近的车辆信息,那么我们该怎么做?这里主要涉及两个步骤,一个是对应的应用要保存和更新车辆实时的上报信息数据,二就是我们要根据加油站的信息来查询它附近的车辆信息。
这里我们首先忽略车辆信息上报这个阶段,因为这涉及到车子与加油站业务对接的相关内容。那么我们来看一下第二个搜索阶段,也就是今天要说的,根据加油站的地理位置信息(这里指的是经纬度)和给定的距离信息来搜索出周边满足条件的车辆,然后根据需要可以进一步按照距离远近进行排序或者限制返回的数量。

2.探索-解决方案选择
在看到搜索这个词的时候,首先意识到这是个对性能有要求的查询,无论是读或者还是写数据,都是要求非常快速的。并且车辆这个数据应该是蛮大的,因为车辆数和车辆的实时数据就是一个大批量的数据了。所以想到了与缓存相关的技术redis,它的读写非常快速,读的速度能达到11万次每秒,写的速度能达到8.1万次每秒。

(1)模糊匹配-keys
使用redis的keys命令,它是遍历算法,时间复杂度是O(N)。由于redis是单线程的,可能会阻塞进程,导致Redis服务卡顿,严重情况下,会导致宕机的可能。在实际生产中是不能使用的,因此不予采用。
(2)扫描-scan
使用redis的scan命令,它的时间复杂度虽然也是O(N),但是它是通过游标分步进行的,不会阻塞线程,还提供了limit参数,可以控制每次返回结果的最大条数。然而通过实际测试,在达到一定量的数据中查找时,还是挺耗时的,这个时间大概在2~5s,无法满足我们这个业务需求。
(3)GEO
使用redis的扩展类型GEO,它的时间复杂度是O(logN),通过实际性能测试,百万级数据查询可以在极短的时间内返回。采用此方案,下面主要就是介绍这个方案。
3. 经纬度
这里简单先介绍一下经纬度的概念,将一张世界地图铺开,以赤道为界将地球分成南北,以本初子午线将地球分成东西。赤道和本初子午线都是0度;以赤道0度开始,向上和向下分别分出90度,南极和北极分别为南纬90度和北纬90度,南极到北极的跨度是(-90,90),其中赤道到南极称为南纬,赤道到北极称为北纬;从本初子午线0度开始,向左和向右分别分出180度,跨度是(-180,180),其中本初子午线向左称为西经,本初子午线向右称为东经
坐标限制:
Redis有效的经度从-180度到180度。有效的纬度从-85.05112878度到85.05112878度。当坐标位置超出上述指定范围时,该命令将会返回一个错误。中国的经度范围:73°33′E至135°05′E。纬度范围:3°51′N至53°33′N。

4. GEO算法
(1)geo算法介绍
Geo算法是业界比较常用的地理位置排序算法,Redis也采用该算法,它是将二维的经纬度数据映射到一维的整数,这样所有的元素都会被挂在到一条线上,距离相近的二维坐标映射到一维后的点之间距离也会很近,当加油站查找附近的车辆时候,首先将目标位置映射到这条线上,然后在这个一维的线上获取附近的点就可以了。
下图展示了天安门 9 个区域的 geohash 字符串,每个字符串表示一个矩形区域(使用一维数据来表示二维坐标)。

(2)分块思想:

Geo算法将整个地球看成一个二维平面,然后划分成了一系列正方形的方格,就像围棋棋盘,所有地图元素坐标都被放置于唯一的方格中,方格越小,坐标越精确,随后对这些方格进行整数编码,越是靠近的方格编码越接近。对于一个完整的二维空间,我们可以用二分的思想将它均匀划分。也就是在水平方向上一分为二,在垂直方向上也一分为二。这样一个空间就会被均匀地划分为四个子空间,这四个子空间,我们可以用两个比特位来编号。在水平方向上,我们用 0 来表示左边的区域,用 1 来表示右边的区域;在垂直方向上,我们用 0 来表示下面的区域,用 1 来表示上面的区域。
应用上述的分块思想,对某块区域进行编码:
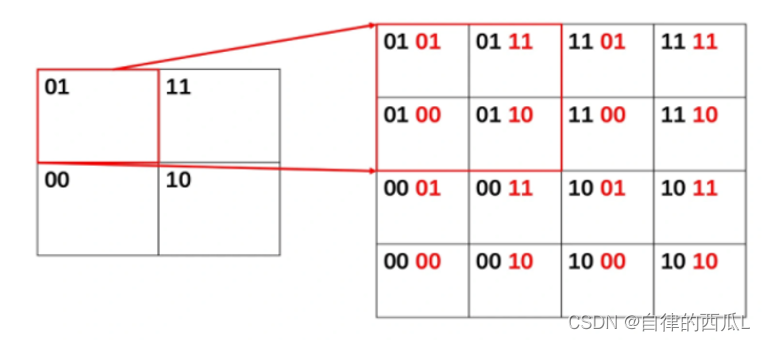
这种区域编码的方式有 2 个优点:
a.区域有层次关系:如果两个区域的前缀是相同的,说明它们属于同一个大区域;
b.区域编码带有分割意义:奇数位的编号代表了垂直切分,偶数位的编号代表了水平切分,这会方便区域编码的计算(奇偶位是从右边以第 0 位开始数起的)。
5.GeoHash编码原理
(1)编码原理
GeoHash是一种地址编码方法,基本原理就是“二分区间,区间编码”。当我们要对一组经纬度进行 GeoHash 编码时,我们要先对经度和纬度分别编码,然后再把经纬度各自的编码组合成一个最终编码。而后base32后成为一个短字符串。
(2)编码过程
以经纬度(116.397457,39.909181)为例计算geohash
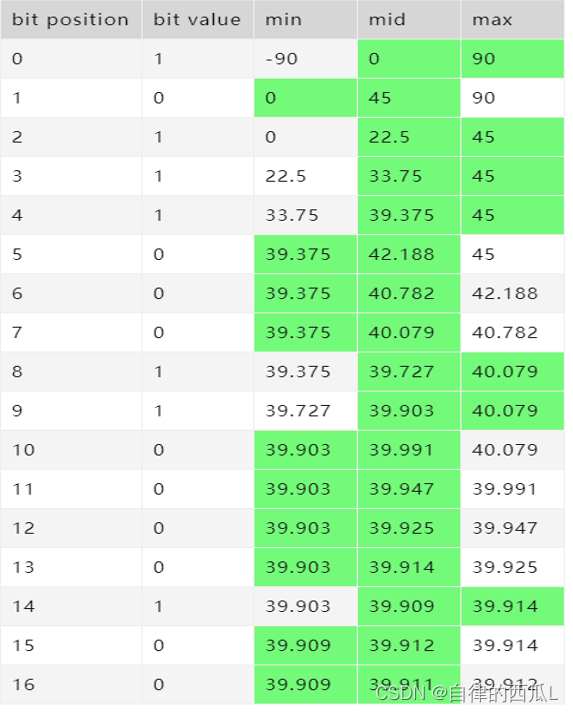
a.经纬度分别编码
纬度 39.909181 编码为:1011100011 00001 00
同理,地球经度区间是[-180,180],
经度116.397457编码为:1101001011 00010 110
b.合并:偶数位放经度,奇数位放纬度,结果如下:
将 11100 11101 0010001111 00000 01001 10100 转成十进制,分别是:28、29、4、15、0、9、20
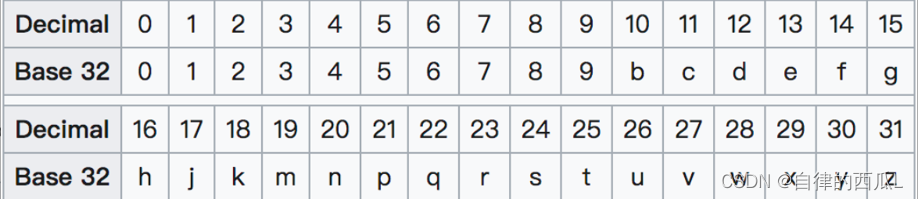
base32的编码(0-9、a-z,去掉a、i、l、o四个字母)
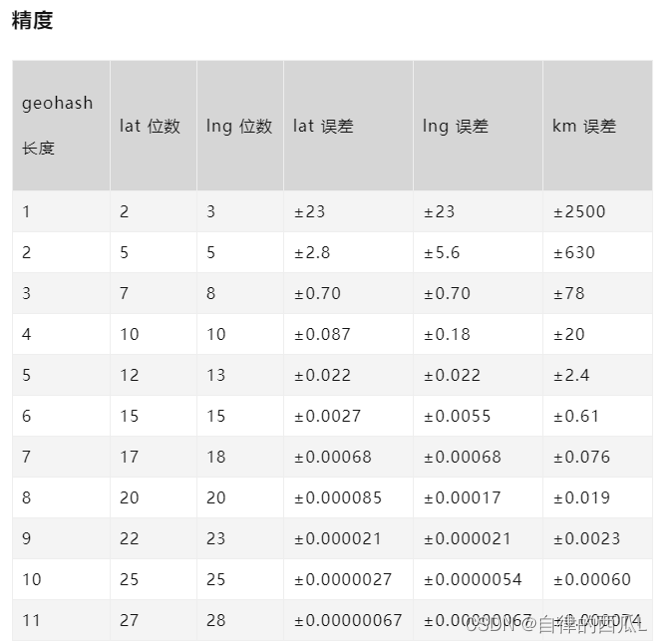
(3)经纬度距离换算(精度)
在纬度相等的情况下:
经度每隔0.00001度,距离相差约1米;每隔0.0001度,距离相差约10米;每隔0.001度,距离相差约100米;每隔0.01度,距离相差约1000米;每隔0.1度,距离相差约10000米。
在经度相等的情况下:
纬度每隔0.00001度,距离相差约1.1米;每隔0.0001度,距离相差约11米;每隔0.001度,距离相差约111米;每隔0.01度,距离相差约1113米;每隔0.1度,距离相差约11132米。
6.ZSET数据结构(简单介绍)
GEO 类型的底层数据结构就是用 Sorted Set 来实现的, GEO 类型是把经纬度所在的区间编码作为 Sorted Set 中元素的权重分数,把和经纬度相关的车辆 VIN码作为 Sorted Set 中元素本身的值保存下来,这样相邻经纬度的查询就可以通过编码值的大小范围查询来实现。如下图, Sorted Set的value值就是用户的ID ,score值就是GeoHash的52位整数值,在redis中使用的时候,通过Sorted Set的score排序就可以得到附近的元素,然后在将score值还原成经纬度坐标信息。

Sorted Set使用了两种不同的存储结构,分别是 zipList(压缩列表)和 skipList(跳跃列表)。
(1)zipList(压缩列表)
当 zset 满足以下条件时使用压缩列表:成员的数量小于128个;每个成员的字符串长度都小于 64 个字节。下图展示的是ziplist的数据结构

(2)skipList(跳跃列表)
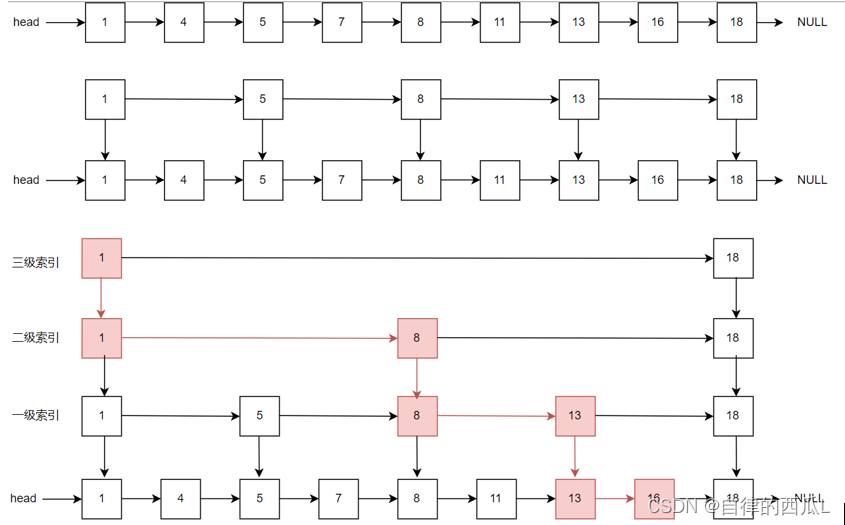
当有序集合不满足使用压缩列表的条件时,就会使用 skipList 结构来存储数据。对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低。如下图所示,这样我们就需要使用跳表(使用多级索引)来解决。