文章目录
环境部署
相关环境部署的笔记如下:
-
zookeeper和spark安装:在zookeeper上搭建Spark集群的小笔记
-
kafka安装和使用:kafka学习笔记
-
sbt下载和安装:Linux无坑安装sbt
项目主要架构
数据总体上可以分为静态数据和流数据。对静态数据和流数据的处理,对应着两种截然不同的计算模式:批量计算和实时计算。批量计算以“静态数据”为对象,可以在很充裕的时间内对海量数据进行批量处理,计算得到有价值的信息。Hadoop就是典型的批处理模型,由HDFS和HBase存放大量的静态数据,由MapReduce负责对海量数据执行批量计算。流数据必须采用实时计算,实时计算最重要的一个需求是能够实时得到计算结果,一般要求响应时间为秒级。当只需要处理少量数据时,实时计算并不是问题;但是,在大数据时代,不仅数据格式复杂、来源众多,而且数据量巨大,这就对实时计算提出了很大的挑战。因此,针对流数据的实时计算——流计算,应运而生。
流计算处理过程包括数据实时采集、数据实时计算和实时查询服务。
- 数据实时采集:数据实时采集阶段通常采集多个数据源的海量数据,需要保证实时性、低延迟与稳定可靠。目前有许多互联网公司发布的开源分布式日志采集系统均可满足每秒数百MB的数据采集和传输需求,如Kafka和Flume等。
- 数据实时计算:流计算处理系统接收数据采集系统不断发来的实时数据,实时地进行分析计算,并反馈实时结果。
- 实时查询服务:流计算的第三个阶段是实时查询服务,经由流计算框架得出的结果可供用户进行实时查询、展示或储存。(一般是把计算结果实时地推送给用户)
-
实时计算架构
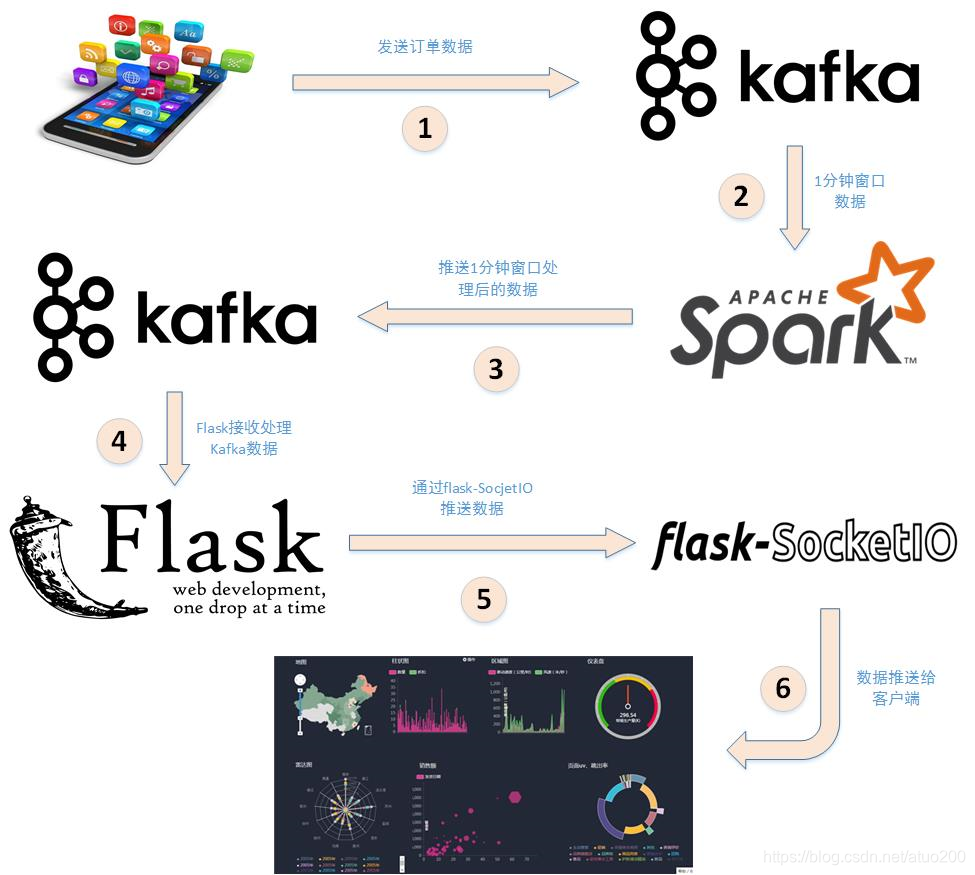
- python读取csv文件,传送数据到kafka
- spark-streaming和kafka集成
- spark-streaming读取传送到kafka的数据,进行实时统计,统计后的数据再推送到kafka
- flask实时接收处理好的kafka数据,利用flask-socketio推送到客户端,进行绘图展示
-
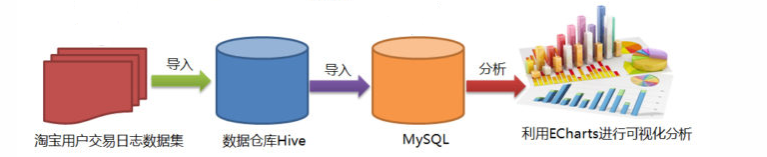
批量计算架构
- 把待分析的数据集导入hive
- hive编写HQL语句批量分析数据
- sqoop把hive中分析后的结果导入mysql中
- flask读取mysql数据,利用echarts绘图进行可视化分析
具体步骤
流计算步骤
在统计淘宝双11的各省份的实时销量、淘宝双11的实时年龄分布、淘宝双11的各购物行为所占的比重、淘宝双11那天的日活量均采用流计算。
python连接kafka
在这一步中,python读取csv文件并连接kafka,把数据传送过去
需要安装pykafka、pandas等第三方库
pip install pykafka
python连接kafka代码
# coding: utf-8
import pandas as pd
from pykafka import KafkaClient
import json
class DataHandle:
def __init__(self):
self.path = "data_format/user_log.csv"
self.double11_path = "data_format/double11_user_log.csv"
self.double11Buy_path = "data_format/double11Buy_user_log.csv"
def select_double11AndBuy(self):
data = pd.read_csv(self.path)
data.drop_duplicates(inplace = True)
# #筛选出双11那天的用户购买记录数据并保存
buy_data = data.loc[data['action'] == 2]
double11_buyData = buy_data[(buy_data["month"] == 11)&(buy_data["day"] == 11)]
double11_buyData.to_csv(self.double11Buy_path,index=None)
#筛选出双11的用户行为记录(点击、收藏、购买、关注)
double11_data = data[(data["month"] == 11)&(data["day"] == 11)]
double11_data.to_csv(self.double11_path,index = None)
return 0
def get_area_data(self):
"""获得双11那天的省份销量数据"""
area_data = pd.read_csv(self.double11Buy_path)
return area_data["province"]
def get_transform_data(self):
transform_data = pd.read_csv(self.double11_path)
return transform_data["action"]
def get_age_data(self):
transform_data = pd.read_csv(self.double11Buy_path)
return transform_data["age_range"]
class operateKafka:
def __init__(self):
self.myhosts = "Master:9092"
self.client = KafkaClient(hosts=self.myhosts)
def sendMessage(self, dataList,topic_name):
topic = self.client.topics[topic_name]
with topic.get_sync_producer() as producer:
for data in dataList:
mydict = str(data)
python_to_json = json.dumps(mydict, ensure_ascii=False)
producer.produce((str(python_to_json)).encode())
if __name__ == "__main__":
dataHandle = DataHandle()
myopKafka = operateKafka()
dataHandle.select_double11AndBuy()
#各个地区的销量
myopKafka.sendMessage(dataHandle.get_area_data().values,"area_data2")
myopKafka.sendMessage(dataHandle.get_transform_data().values,"action_class")
myopKafka.sendMessage(dataHandle.get_age_data().values,"age_data")
执行上述代码之后可在kafka集群这边任意一个节点上测试是否能接收到数据,从而判断数据是否成功传送到kafka。(以实时省份销量数据为例)
cd /usr/local/kafka/bin
./kafka-console-consumer.sh --bootstrap-server Master:9092 --topic area_data2 --from-beginning

spark-streaming集成kafka
Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据,能做到秒级响应,不能做到毫秒级响应。Spark Streaming实际上是仿照流计算,并不是真正实时的流计算框架。
kafka安装:kafka学习笔记,为和下面的spark-streaming-kafka集成jar包适配,建议装0.8或者0.10版本的kafka(分情况,看spark版本)。
下载spark-streaming-kafka的jar包:
spark2.3.0版本以下(不包括2.3.0)的可以下载spark-streaming-kafka-0-8的集成:spark-streaming-kafka-0-8,选择与自己scala和spark版本相对应的jar包下载
spark2.3.0以上版本(包括2.3.0)的可以下载spark-streaming-kafka-0-10以上的集成:spark-streaming-kafka-0-10
把下载的jar包拷贝到/usr/local/spark/jars下
在/usr/local/spark/jars目录下,新建一个kafka目录,把kafka安装目录的libs目录下的所有jar文件复制到/usr/local/spark/jars/kafka目录下,
cd /usr/local/kafka/libs
cp ./* /usr/local/spark/jars/kafka
下面测试spark和kafka环境是否连通
启动spark-shell
cd /usr/local/spark/bin
./spark-shell --master spark://Master:7077
在spark-shell里引入如下jar包
import org.apache.spark.streaming.kafka010._
若引入jar包不出错,说明kafka和spark环境已经连通
编写并运行spark-streaming程序(实时词频统计)
scala的官方API文档:https://www.scala-lang.org/api/2.11.12/#scala.package,此文档对应的scala版本是2.11.12,也可以到:https://docs.scala-lang.org/api/all.html 查找与自己的scala版本相对应的API文档。
spark的官方API文档:http://spark.apache.org/docs/2.4.5/api/scala/index.html#org.apache.spark.package,此文档对应的scala版本是2.11.12,也可以到:http://spark.apache.org/docs/ 查找与自己的spark版本相对应的API文档。
创建项目spark_connect_kafka
cd /usr/local/spark/mycode
mkdir spark_connect_kafka
cd spark_connect_kafka
mkdir -p src/main/scala
编写scala代码
vi kafkaCount.scala
package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{
KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.json4s._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.write
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.Interval
import org.apache.spark.streaming.kafka010._
object KafkaWordCount {
//数据格式化时需要
implicit val formats = DefaultFormats
def main(args: Array[String]): Unit={
//判断参数输入是否齐全,当不齐全时退出程序
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <brokers> <groupId> <topics>")
System.exit(1)
}
/* 输入的四个参数分别代表着
* 1. brokers为要消费的topics所在的broker地址
* 2. group为消费者所在的组
* 3. topics该消费者所消费的topics
* 4. topics2为要推送到kafka的数据分析结果的topics
*/
//把输入的4个参数封装成数组
val Array(brokers, groupId, topics,topics2) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
//把检查点写入本地磁盘文件,不写入hadoop不必启动hadoop
ssc.checkpoint("file:///home/hadoop/data/checkpoint")
//一个consumer-group可以消费多个topic,这里把topics按照“,”分割放进set里(虽然我们一般只是传进去一个topic)
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
"auto.offset.reset" -> "earliest",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
//创建连接Kafka的消费者链接
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
//获取输入的每行数据,将输入的每行用空格分割成一个个word(这里的代码逻辑是词频统计的逻辑)
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
// 对每一秒的输入数据进行reduce,然后将reduce后的数据发送给Kafka
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_+_,_-_, Seconds(3), Seconds(1), 3).foreachRDD(rdd => {
if(rdd.count !=0 ){
//创建kafka生产者配置文件(数据结构为HashMap,初始为空,不断添加配置)
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "Master:9092")
//key序列号方式
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
//value序列号方式
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
//实例化一个Kafka生产者
val producer = new KafkaProducer[String, String](props)
//rdd.colect即将rdd中数据转化为数组,然后write函数将rdd内容转化为json格式
val str = write(rdd.collect)
//封装成Kafka消息,发送给相应的topics
val message = new ProducerRecord[String, String](topics2, null, str)
//给Kafka发送消息
producer.send(message)
}
})
//启动流式计算
ssc.start()
//等待直到计算终止
ssc.awaitTermination()
}
}
其中有一句"reduceByKeyAndWindow(+,-, Seconds(1), Seconds(1), 1)",关于reduceByKeyAndWindow算子所执行的操作可以戳:SparkStreaming滑动计算窗口reduceByKeyAndWindow图解说明,说通俗点,可以把每一次窗口以内的数据看作是一个池塘里的鱼,当窗口以指定的滑动时间滑动时,每一次滑动都有鱼游入和游出,当有鱼游入时,就加上游入的该类鱼的数量,当有鱼游出去时,就减去游出的该类鱼的数量,以此统计出每一次窗口内的每类鱼的数量。
这样做是为了减少计算量,通过只计算游出去多少鱼和游进来多少鱼而得到当前池塘(窗口)的鱼的数量,而不必把整个池塘(窗口)都统计一遍,减少了窗口长度-(2*滑动时间)的运算量。
编写sbt文件
vi spark_connect_kafka.sbt
name := "spark_connect_kafka Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.5"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.4.5"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-10_2.11" % "2.4.5"
libraryDependencies += "org.json4s" %% "json4s-jackson" % "3.2.11"
然后编译并打包程序
cd /usr/local/spark/mycode/spark_connect_kafka
sbt package
打包成功之后,可以编写运行脚本,在/usr/local/spark/mycode/spark_connect_kafka目录下新建startup.sh文件,输入如下内容(以统计各省份实时销量时的参数为例,在统计其他类型的数据时,需自行更改spark-streaming消费的topics和生产的topics)
/usr/local/spark/bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* --class "org.apache.spark.examples.streaming/KafkaWordCount" /usr/local/spark/mycode/spark_connect_kafka/target/scala-2.11/spark_connect_kafka-project_2.11-1.0.jar Master:9092 2 area_data2 areaTopic2
最后在/usr/local/spark/mycode/spark_connect_kafka目录下,运行如下命令即可执行刚编写好的Spark Streaming程序
sh startup.sh
编写并运行spark-streaming程序(累加词频统计)
spark-streaming的累加词频统计其他均与spark-streaming的实时词频统计一致,只是scala代码中增加了updateStateByKey算子来累加上一批次计算的结果。
package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{
KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.json4s._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.write
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.Interval
import org.apache.spark.streaming.kafka010._
object KafkaWordCount {
implicit val formats = DefaultFormats//数据格式化时需要
def main(args: Array[String]): Unit={
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <brokers> <groupId> <topics>")
System.exit(1)
}
val Array(brokers, groupId, topics) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint("file:///home/hadoop/data/checkpoint")
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
"auto.offset.reset"->"earliest",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" ")).map((_, 1))//将输入的每行用空格分割成一个个word
//words.updateStateByKey为每个key维护一个state,并持续不断的更新该值
val wordCounts = words.updateStateByKey(
//每个单词每次batch计算的时候都会调用这个函数
(values: Seq[Int], state: Option[Int]) => {
//state.getOrElse(0)的含义是,如果该单词没有历史词频统计汇总结果,那么,就取值为0,如果有历史词频统计结果,就取历史结果
var newValue = state.getOrElse(0)
values.foreach(newValue += _)
Option(newValue)
}).foreachRDD(rdd => {
if(rdd.count !=0 ){
//创建kafka生产者配置文件(数据结构为HashMap,初始为空,不断添加配置)
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "Master:9092")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
val str = write(rdd.collect)
println("come rdd.collect")
val message = new ProducerRecord[String, String](topics2, null, str)
producer.send(message)
println("haved send")
}else{
println("else")
}
})
//启动流式计算
ssc.start()
//等待直到计算终止
ssc.awaitTermination()
}
}
在kafka上查看数据统计结果
开启消费,看是否能消费到上面spark-streaming程序生产出的topics消息(以省份统计数据为例)
./kafka-console-consumer.sh --bootstrap-server Master:9092 --topic areaTopic2 --from-beginning
批量计算步骤
用于统计淘宝双11销量前20的商品类型ID
往hive中导入数据
启动hive
hive
根据数据集字段创建相应的表
create table double11Buy_table(
id int,
user_id int,
item_id int,
cat_id int,
merchant_id int,
brand_id int,
month int,
day int,
action int,
age_range int,
gender int,
province string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
导入数据
load data local inpath "root/Desktop/double11Buy_user_log.csv" into table double11Buy_table
筛选出销量前20的商品类型ID
create table catCountAll as select cat_id,count(id) as count from double11Buy_table group by cat_id;
create table catCountTop20 as select * from catCountAll group by count desc limit 20;

sqoop导出数据到mysql
在mysql上创建相应的数据库和数据表
create database double11;
use double11;
create table catCount_table(
cat_id varchar(50),
count int
)
sqoop导出数据到mysql
sqoop export --connect jdbc:mysql://192.168.100.10:3306/double11 --username root --password root --table catCount_table --export-dir /user/hive/warehouse/catcounttop20 –fields-terminated-by "\001"
mysql这边查看,可以看到数据成功导入
select * from catCount_table;
淘宝RFM用户划分
选取11月份之前的用户购买记录数据进行RFM用户划分,为每一个用户打上标签。从而统计双11活动周的营销策略在唤回用户方面的效果。
在这里由于数据集不包含用户消费金额,所以用户划分只从R、F两个维度来进行划分。
只选取11月份之前的用户购买记录来进行RFM用户模型建模是因为:双11是特殊的一天,几乎所有的用户在双11那天都有消费记录,而数据集的数据记录又只记录到11月12日那天,如果选取包含11月份的数据在内的数据进行RFM用户模型建模,那么几乎所有的用户的R值都会趋于一致,用户在R维度上的区别都会被抹平。
import pandas as pd
import datetime
data = pd.read_csv("data_format/double11Buy_user_log.csv")
data["time"] = data.apply(lambda item:"2015-"+str(item["month"])+"-"+str(item["day"]),axis=1)
data["time"] = pd.to_datetime(data["time"],format="%Y-%m-%d")
data["r_value_single"] = data["time"].apply(lambda x:(datetime.datetime.strptime('2015-11-1','%Y-%m-%d')-x).days)
r_value = data.groupby(['user_id']).r_value_single.min()
f_value = data.groupby(['user_id']).size() # 按每个用户id累积订单数量作为f值
rfm_df = pd.concat([r_value, f_value], join='outer', axis=1)
rfm_df.columns = ["r_value","f_value"]
rfm_df["user_id"] = rfm_df.index
rfm_df["r_score"] = (rfm_df["r_value"] > rfm_df["r_value"].mean())*1
rfm_df["f_score"] = (rfm_df["f_value"] > rfm_df["f_value"].mean())*1
def put_label(item):
return str(item["r_score"])+str(item["f_score"])
rfm_df["class_index"] = rfm_df.apply(put_label,axis=1)
def transform_user_class(x):
if x == "11":
user_label = "重要价值用户"
elif x == "01":
user_label = "重要深耕用户"
elif x == "10":
user_label = "重要唤回用户"
else:
user_label = "流失用户"
return user_label
rfm_df["user_class"] = rfm_df["class_index"].apply(transform_user_class)
print(rfm_df.head(20))
user_count = rfm_df["user_class"].value_counts()
user_count.to_json('static/user_count.json')
Flask-SocketIO实时推送数据
在流计算步骤和批量计算步骤获得所需的数据后,可利用flask读取kafka和mysql中的数据,利用flask-socketio把数据实时推送到客户端,客户端通过socket.io.js实时接收数据,利用echarts进行动态绘图展示
flask应用程序代码,一个主线程三个子线程
import json
import time
from flask import Flask, render_template,jsonify
from flask_socketio import SocketIO
from pykafka import KafkaClient
from sqlalchemy import create_engine
import pandas as pd
app = Flask(__name__)
app.config['SECRET_KEY'] = 'secret!'
socketio = SocketIO(app)
thread = None
thread2 = None
thread3 = None
# 实例化一个consumer,接收topic的消息
client = KafkaClient(hosts="Master:9092")
# # 确定使用的topic
topic = client.topics['areaTopic2']
consumer = topic.get_simple_consumer(
consumer_group="consumer",
reset_offset_on_start=True
)
topic2 = client.topics['actionClass']
consumer2 = topic2.get_simple_consumer(
consumer_group="consumer2",
reset_offset_on_start=True
)
topic3 = client.topics['ageData']
consumer3 = topic3.get_simple_consumer(
consumer_group="consumer3",
reset_offset_on_start=True
)
def age_background_thread():
for msg in consumer3:
data_json = msg.value.decode('utf8')
data_list = json.loads(data_json)
chart_data = []
for data in data_list:
if list(data.keys())[0] == '"0"':
key = "未知"
elif list(data.keys())[0] == '"1"':
key = "小于18岁"
elif list(data.keys())[0] == '"2"':
key = "18到24岁"
elif list(data.keys())[0] == '"3"':
key = "25到29岁"
elif list(data.keys())[0] == '"4"':
key = "30到34岁"
elif list(data.keys())[0] == '"5"':
key = "35到39岁"
elif list(data.keys())[0] == '"6"':
key = "40到49岁"
else:
key = "大于49岁"
chart_data.append({
"name":key,
"value":list(data.values())[0]
})
socketio.emit('age_message',chart_data)
time.sleep(1)
def action_background_thread():
for msg in consumer2:
chart_data = []
data_json = msg.value.decode('utf8')
data_list = json.loads(data_json)
for data in data_list:
if list(data.keys())[0] == '"0"':
key = "点击"
elif list(data.keys())[0] == '"1"':
key = "加入购物车"
elif list(data.keys())[0] == '"2"':
key = "购买"
else:
key = "关注"
chart_data.append({
"value":list(data.values())[0]/100,
"name":key
})
socketio.emit('action_message',chart_data)
time.sleep(1)
def area_background_thread():
for msg in consumer:
data_json = msg.value.decode('utf8')
data_list = json.loads(data_json)
chart_data = []
for data in data_list:
chart_data.append({
"name":list(data.keys())[0].replace('"',""),
"value":list(data.values())[0]
})
socketio.emit('area_message',chart_data)
time.sleep(1)
#客户端发送age_connect事件时的处理函数
@socketio.on('age_connect')
def age_connect(message):
global thread3
if thread3 is None:
# 单独开启一个线程给客户端发送数据
thread3 = socketio.start_background_task(target=age_background_thread)
@socketio.on('area_connect')
def area_connect(message):
global thread
if thread is None:
# 单独开启一个线程给客户端发送数据
thread = socketio.start_background_task(target=area_background_thread)
socketio.emit('connected', {
'data': 'Connected'})
#客户端发送test_connect事件时的处理函数
@socketio.on('action_connect')
def action_connect(message):
global thread2
if thread2 is None:
thread2 = socketio.start_background_task(target=action_background_thread)
@app.route('/catsql_data',methods = ["GET","POST"])
def get_place_data():
conn = create_engine("mysql+pymysql://root:root@Master/double11?charset=utf8")
result = pd.read_sql("select * from catCount_table",con=conn)
data = list(result.apply(lambda item:{
"name":item["cat_id"],"value":item["count"]},axis = 1))
return jsonify(data)
@app.route("/")
def handle_itemClassMes():
return render_template("index.html")
if __name__ == '__main__':
socketio.run(app,debug=True,host='127.0.0.1',port=5000)
Echarts动态绘图
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>淘宝双11实时大屏数据分析</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/1.10.0/jquery.min.js"></script>
<script type="text/javascript" src="//cdn.bootcss.com/socket.io/1.5.1/socket.io.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/echarts.min.js"></script>
<script type="text/javascript" src="../static/china.js"></script>
<script src="https://echarts-www.cdn.bcebos.com/zh/asset/theme/macarons.js"></script>
<script src="../static/esl.js"></script>
<style type="text/css">
body {
background-image: url("/static/timg.jpg");
}
h1 {
color: #fff;
}
#action_box,
#user_box,
#dailylife_box,
#cat_box,
#area_box,
#age_box {
background-color: rgba(230, 255, 255, 0.945)!important;
display: inline-block;
}
.contain {
text-align: center;
}
.public {
width: 600px;
height: 500px;
padding: 5px;
border: 1px solid #ccc;
box-shadow: 0 0 3px #aaa inset;
}
.empty {
height: 30px;
}
</style>
</head>
<body>
<h1 align="center">淘宝双11实时大屏数据分析</h1>
<div class="empty"></div>
<div class="contain">
<div id="action_box" class="public"></div>
<div id="user_box" class="public"></div>
<div id="age_box" class="public"></div>
<div id="dailylife_box" class="public"></div>
<div id="cat_box" class="public"></div>
<div id="area_box" class="public"></div>
</div>
</body>
<script>
var action_chart = echarts.init(document.getElementById('action_box'), "macarons");
var socket = io.connect('http://' + document.domain + ':' + location.port);
//客户端发起链接
socket.on('connect', function() {
socket.emit('action_connect', {
data: 'I\'m connected(action)!'
});
socket.emit('age_connect', {
data: 'I\'m connected(age)!'
});
socket.emit('area_connect', {
data: 'I\'m connected!'
});
socket.emit('action_connect', {
data: 'I\'m connected(daily)!'
});
});
var update_mychart = function(res) {
var option = {
title: {
text: '淘宝双11各购物行为漏斗图',
x: 'center'
},
tooltip: {
trigger: 'item',
formatter: "{a} <br/>{b} : {c}人"
},
toolbox: {
feature: {
dataView: {
readOnly: false
},
restore: {
},
saveAsImage: {
}
}
},
series: [{
name: '漏斗图',
type: 'funnel',
left: '10%',
top: 60,
bottom: 40,
width: '80%',
min: 0,
max: 100,
minSize: '0%', //数据最小值 min 映射的宽度,默认为0%
maxSize: '100%', //绝对的像素大小,也可以是相对布局宽度的百分比
sort: 'descending',
gap: 2,
label: {
show: true,
position: 'inside'
},
labelLine: {
length: 10,
lineStyle: {
width: 1,
type: 'solid'
}
},
itemStyle: {
borderColor: '#fff',
borderWidth: 1
},
emphasis: {
label: {
fontSize: 20
}
},
data: res
}]
};
action_chart.setOption(option);
};
socket.on('action_message', function(message) {
update_mychart(message)
});
var myChart = echarts.init(document.getElementById('user_box'), 'macarons');
$.get('../static/user_count.json', function(data) {
dataAxis = Object.keys(data);
dataValue = Object.values(data);
// 指定图表的配置项和数据
var option2 = {
title: {
text: '淘宝用户类型分布',
x: "center"
},
tooltip: {
},
xAxis: {
data: dataAxis
},
yAxis: {
},
series: [{
name: '用户等级',
type: 'bar',
data: dataValue
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option2);
});
var age_chart = echarts.init(document.getElementById('age_box'), "macarons");
var update_agechart = function(res) {
var option3 = {
title: {
text: '淘宝双11买家年龄分布',
x: 'center'
},
tooltip: {
trigger: 'item',
formatter: '{a} <br/>{b} : {c} ({d}%)'
},
series: [{
name: '年龄分布',
type: 'pie',
radius: '55%',
center: ['50%', '60%'],
data: res,
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}]
};
age_chart.setOption(option3);
};
socket.on('age_message', function(message) {
update_agechart(message)
});
var area_chart = echarts.init(document.getElementById('area_box'), "macarons");
var update_areachart = function(res) {
var option4 = {
title: {
text: '淘宝双11各省份实时销量',
x: 'center'
},
tooltip: {
trigger: 'item'
},
dataRange: {
min: 0,
max: 150,
x: 'left',
y: 'center',
color: ['#006edd', '#e0ffff'],
text: ['高', '低'],
calculable: true
},
series: [{
name: '数据',
type: 'map',
mapType: 'china',
roam: true,
label: {
normal: {
show: true //省份名称
},
emphasis: {
show: true
}
},
data: res
}]
};
area_chart.setOption(option4);
};
socket.on('area_message', function(message) {
update_areachart(message)
});
var catChart = echarts.init(document.getElementById('cat_box'), "macarons");
$.get('/catsql_data', function(data) {
var chart_data = data;
var option5 = {
title: {
text: '淘宝双11商品类别销量Top20',
x: "center"
},
tooltip: {
trigger: 'item',
formatter: "{b}: {c}"
},
toolbox: {
show: true,
feature: {
mark: {
show: true
},
dataView: {
show: true,
readOnly: false
},
restore: {
show: true
},
saveAsImage: {
show: true
}
}
},
calculable: false,
series: [{
name: '矩形树图',
type: 'treemap',
data: chart_data
}]
};
catChart.setOption(option5)
})
var dailyChart = echarts.init(document.getElementById('dailylife_box'), 'macarons');
var update_dailychart = function(res) {
dataAxis = []
dataValue = []
for (var item in res) {
dataAxis.push(res[item]["name"])
dataValue.push(Math.round(res[item]["value"] * 100))
}
console.log(dataValue)
var option6 = {
title: {
text: '淘宝双11日活量',
x: "center"
},
xAxis: {
type: 'category',
data: dataAxis
},
yAxis: {
type: 'value'
},
series: [{
data: dataValue,
type: 'bar',
label: {
show: true,
position: 'inside'
},
showBackground: true,
backgroundStyle: {
color: 'rgba(220, 220, 220, 0.8)'
}
}]
};
dailyChart.setOption(option6)
}
socket.on('action_message', function(message) {
update_dailychart(message)
});
</script>
</html>
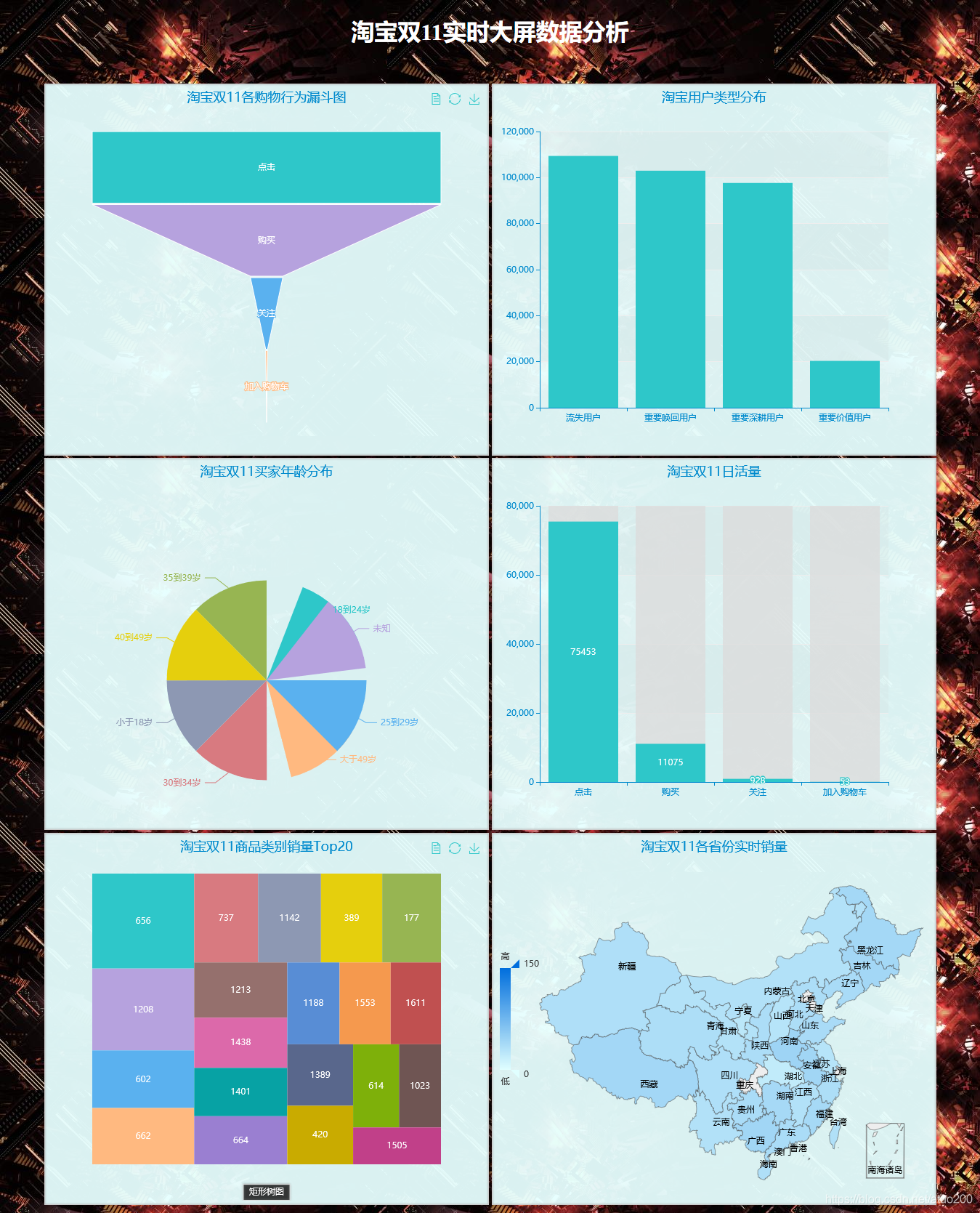
项目结果