文章作者邮箱:[email protected] 地址:广东惠州
▲ 本章节目的
⚪ 了解hadoop的定义和特点;
⚪ 掌握hadoop的基础结构;
⚪ 掌握hadoop的常见命令;
⚪ 了解hadoop的执行流程;
一、简介
1. 概述
1. HDFS(Hadoop Distributed File System - Hadoop分布式文件系统)是Hadoop提供的一套用于进行分布式存储的机制。
2. HDFS是Doug Cutting根据Google的论文<The Google File System>(GFS)来仿照实现的。
2. 特点
1. 能够存储超大文件。在HDFS集群中,只要节点数量足够多,那么一个文件无论是多大都能够进行存储 - HDFS会对文件进行切块处理。
2. 快速的应对和检测故障。在HDFS集群中,运维人员不需要频繁的监听每一个节点,可以通过监听NameNode来确定其他节点的状态 - DataNode会定时的给NameNode来发送心跳。
3. 具有高容错性。在HDFS中,会自动的对数据来保存多个副本,所以不会因为一个或者几个副本的丢失就导致数据产生丢失。
4. 具有高吞吐量。吞吐量实际上指的是集群在单位时间内读写的数据总量。
5. 可以在相对廉价的机器上来进行横向扩展。
6. 不支持低延迟的访问。在HDFS集群中,响应速度一般是在秒级别,很难做到在毫秒级别的响应。
7. 不适合存储大量的小文件。每一个小文件都会产生一条元数据,大量的小文件就会产生大量的元数据。元数据过多,会占用大量内存,同时会导致查询效率变低。
8. 简化的一致性模型。在HDFS中,允许对文件进行一次写入多次读取,不允许修改,但是允许追加写入。
9. 不支持超强事务甚至不支持事务。在HDFS中,因为数据量较大,此时不会因为一个或者几个数据块出现问题就导致所有的数据重新写入 - 在数据量足够大的前提下,允许出现容错误差。
二、基本概念
1. 基本结构
1. HDFS本身是一个典型的主从(M/S)结构:主节点是NameNode,从节点是DataNode。
2. HDFS会对上传的文件进行切分处理,切出来的每一个数据块称之为Block。
3. HDFS会对上传的文件进行自动的备份。每一个备份称之为是一个副本(replication/replicas)。如果不指定,默认情况下,副本数量为3。
4. HDFS仿照Linux设计了一套文件系统,允许将文件存储到不同的虚拟路径下,同时也设计了一套和Linux一样的权限策略。HDFS的根路径是/。
2. Block
1. Block是HDFS中数据存储的基本形式,即上传到HDFS上的数据最终都会以Block的形式落地到DataNode的磁盘上。
2. 如果不指定,默认情况下,Block的大小是134217728B(即128M)。可以通过dfs.blocksize属性来调节,放在hdfs-site.xml文件中,单位是字节。
3. 如果一个文件不足一个Block的指定大小,那么这个文件是多大,它所对应的Block就是多大。例如一个文件是70M,那么对应的Block就是70M。属性dfs.blocksize指定的值实际上可以立即为一个Block的最大容量。
4. 注意,在设计Block大小的时候,Block是维系在DataNode的磁盘上,要考虑Block在磁盘上的寻址时间以及传输时间(写入时间)的比例值。一般而言,当寻址时间是传输时间的1%的时候,效率最高。而计算机在磁盘上的寻址时间大概在10ms左右,那么写入时间就是10ms/0.01=1000ms=1s。考虑到绝大部分的服务器使用的是机械磁盘,机械磁盘的写入速度一般在120MB/s左右,此时一个Block大小是1s*120MB/s=120M左右。
5. HDFS会为每一个Block来分配一个唯一的编号BlockID。
6. 切块的意义:
a. 能够存储超大文件。
b. 能够进行快速备份。
3. NameNode
1. NameNode是HDFS中的主(核心)节点。在Hadoop1.X中,NameNode只能有1个,容易存在单点故障;在Hadoop2.X中,NameNode最多允许存在2个;在Hadoop3.X中,不再限制NameNode的数量,也因此在Hadoop3.X的集群中,NameNode不存在单点故障。
2. NameNode的作用:对外接收请求,记录元数据,管理DataNode。
3. 元数据(metadata)是用于描述数据的数据(大概可以将元数据理解为账本)。在HDFS中,元数据实际上是用于描述文件的一些性质。在HDFS中,将元数据拆分成了很多项,主要包含了以下几项:
a. 上传的文件名以及存储的虚拟路径,例如/log/a.log。
b. 文件对应的上传用户以及用户组。
c. 文件的权限,例如-rwxr-xr--。
d. 文件大小。
e. Block大小。
f. 文件和BlockID的映射关系。
g. BlockID和DataNode的映射关系。
h. 副本数量等。
4. 一条元数据大小大概在150B左右。
5. 元数据是维系在内存以及磁盘中。
a. 维系在内存中的目的是查询快
b. 维系在磁盘中的目的是持久化
6. 元数据在磁盘上的存储位置由属性hadoop.tmp.dir来决定,是放在core-site.xml文件中。如果不指定,默认情况下是放在/tmp下。
7. 和元数据相关的文件:
a. edits:写操作文件。用于记录HDFS的写操作。
b. fsimage:元映像文件。存储了NameNode对元数据的序列化形态(大概可以理解为元数据在磁盘上的持久化存储形式)。
8. 当NameNode接收到写操作(命令)的时候,会先将这个写操作(命令)记录到edits_inprogress文件中。记录成功之后,NameNode会解析这个命令,然后修改内存中的元数据。修改成功之后,会给客户端来返回一个ACK信号表示成功。在这个过程中,会发现,fsimage文件中的元数据并没有发生变化。
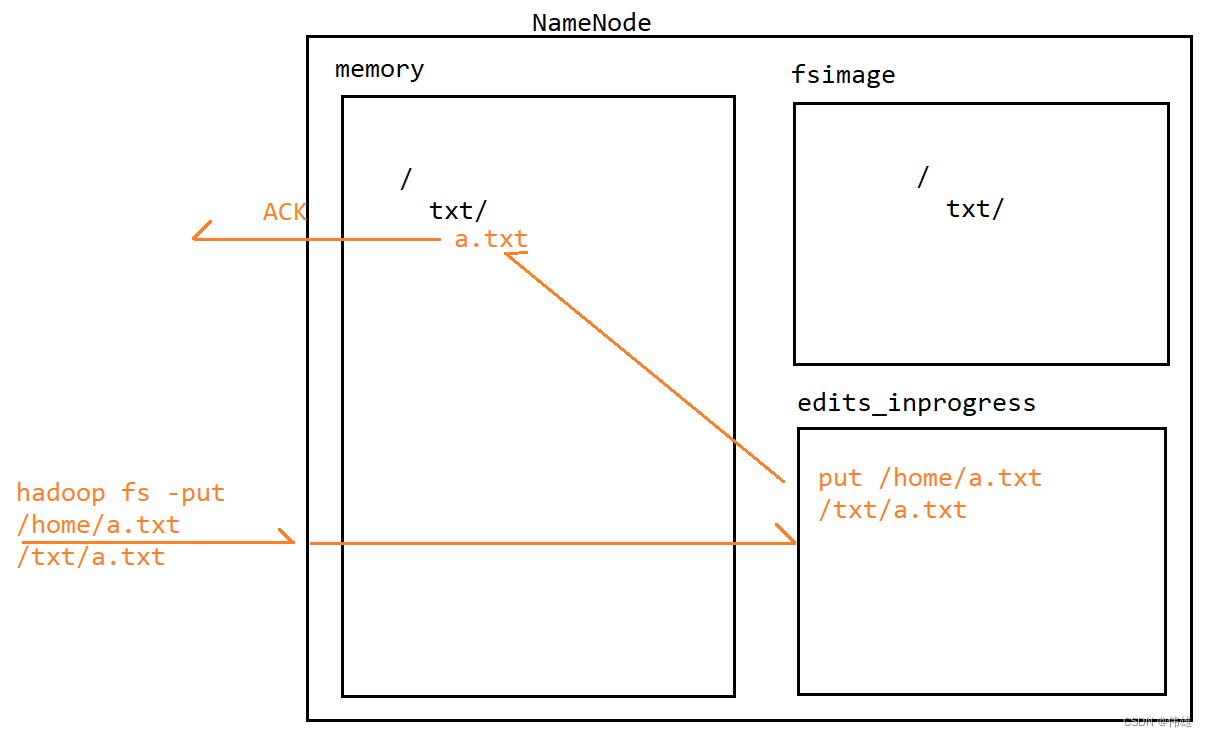
9. 随