第一部分:皮尔逊相关系数的计算以及数据的描述性统计
本讲我们将介绍两种最为常见的相关系数:皮尔逊person相关系数和斯皮尔曼spearman等级相关系数。它们可以用来衡量两个变量之间的相关性的大小,根据数组满足的不同条件,我们要选择不同的相关性系数进行行计算和分析(建模论文中最容易用错的方法)。
总体和样本:
总体皮尔逊相关系数:
皮尔逊相关系数中各专业术语的公式/定义:
总体皮尔逊相关系数:
样本皮尔逊相关系数(分母变为了n-1)
相关性可视化图(spss版):
关于皮尔逊相关系数的一些理解误区:(在我们使用皮尔逊系数前买两个变量本身必须满足线性的关系)


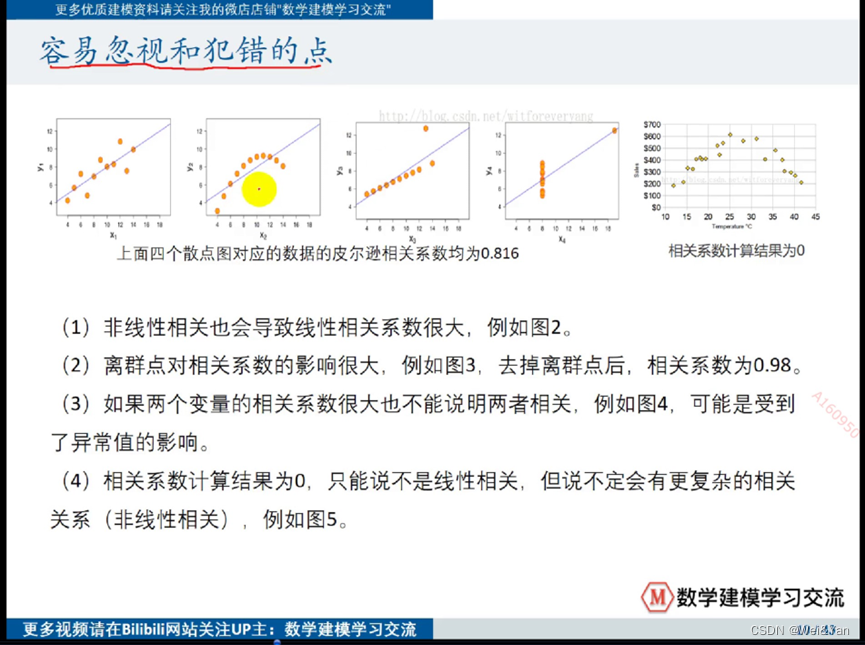

(在使用皮尔逊相关系数前我们可以提前绘制散点图来判断是否符合线性关系)
对相关系大小的解释: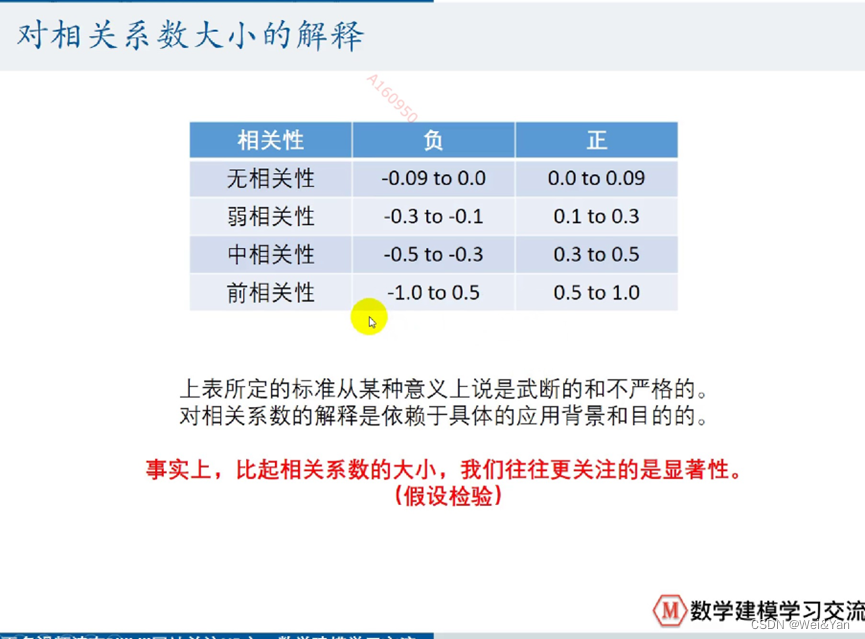
列题:求八年级女生体测各数据之间的相关性: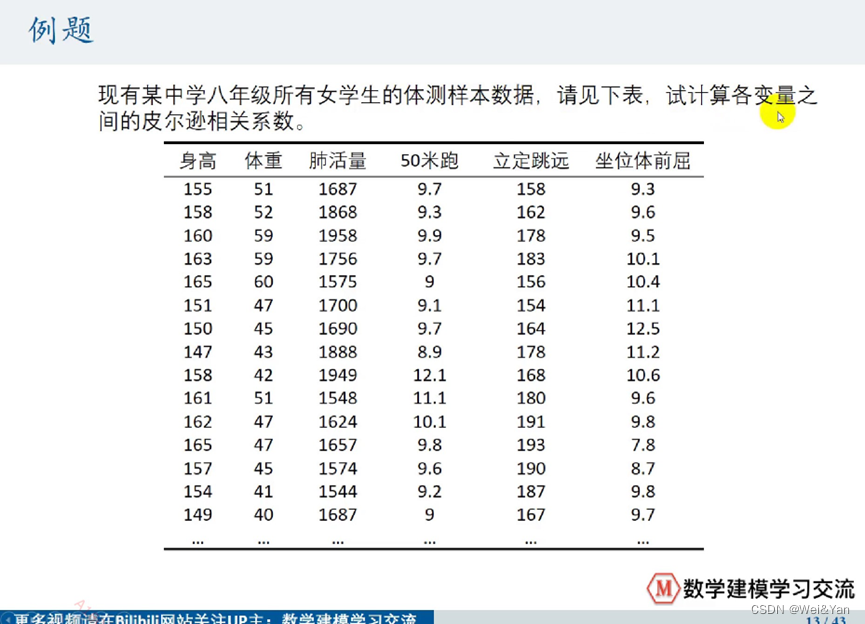
解法1:利用matlab来求解各项数据之间的关系
(matlab中求各项数据用到的函数)
代码实现: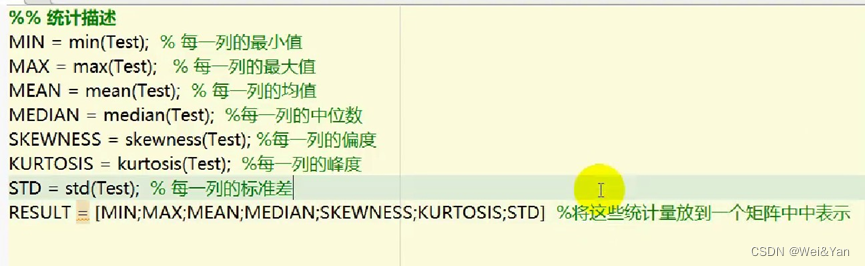
将得出的数据结果存入excel表中: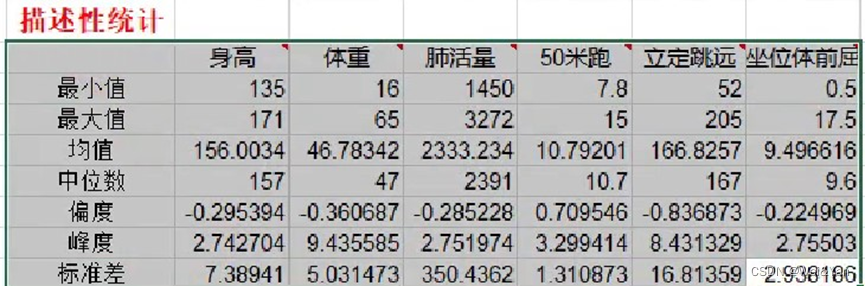
解法2:用spss软件
a.导入数据
b.数据统计
分析->描述->ctrl+a(全选)->选项(统计内容)->确定->等待生成数据图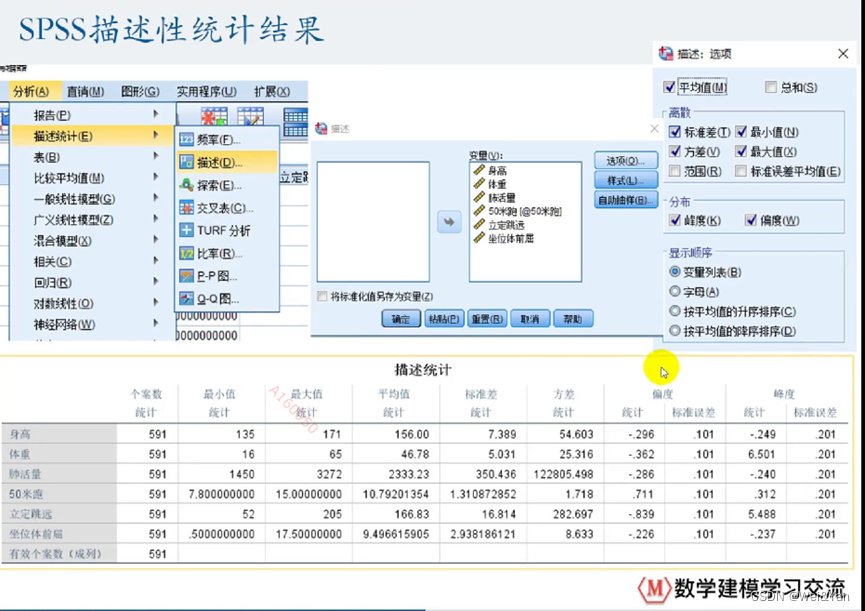
皮尔逊相关系数(R)的计算:
a:matlab中有专门计算相关系数的函数corrcoef函数
R=corrcoef(传入的数据)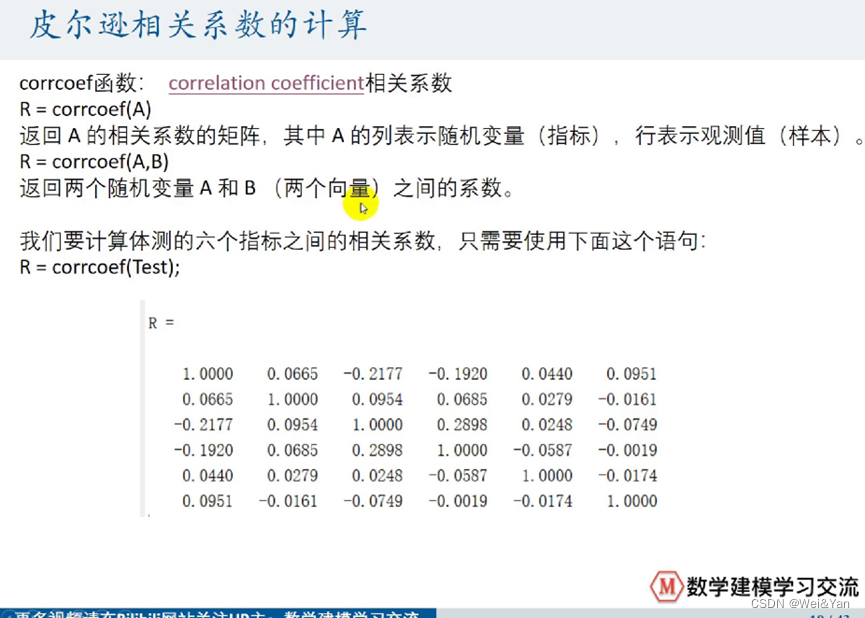
美化相关系数表:
将数据导入excel中
1调整行高,字体大小,字体位置(居中),列宽,小数点保留四位
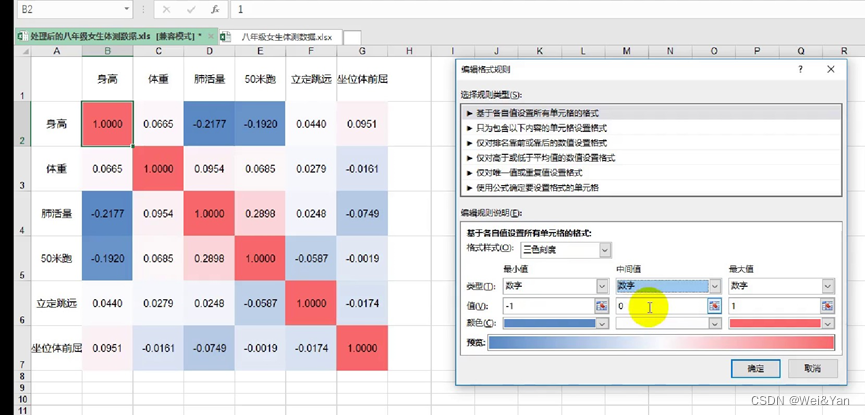
2设置成便于观察的有色表格:开始->条件格式->色阶(随便选择一个都可以,上图中选择的红-白-蓝)->规则类型->编辑格式规则->最小值->数字->-1,中间值->数字->0->最大值->数字->1.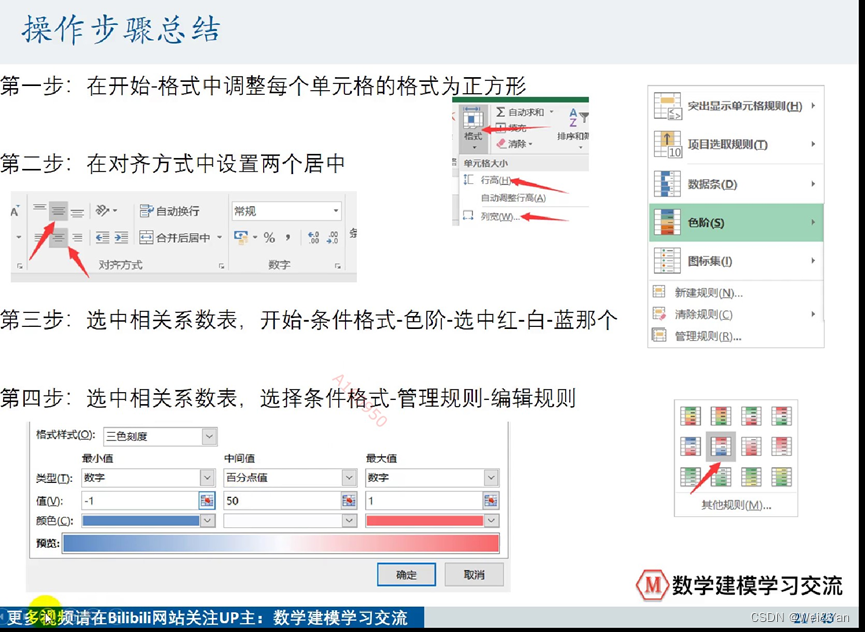
b:利用spss软件可以生成相关系数图
步骤:图形->旧对话框->散点图/点图->矩阵散点图->定义->ctrl+a(全选)导入矩阵变量->确定
生成图像: 
第二部分:假设检验
- 第一步:零假设(H0):我们要验证或者推翻的假设,默认为所观察到的现象是由随机原因引起的,没有任何真实的效应或者关联。在这种情况下,我们可以假设没有校园交通事故与电动车超速之间的关联,即H0:电动车超速与校园交通事故无关。
- 备择假设(H1):对零假设的补充或者反面假设,表示我们想要证明的观察结果是由真实效应引起的。在这种情况下,备择假设可以是H1:电动车超速与校园交通事故有关。
- 显著性水平(α):代表我们在假设检验中所接受的错误率的界限。常见的显著性水平包括0.05和0.01。选择适当的显著性水平取决于研究的目的以及行业的标准。
- 检验统计量:根据研究问题和数据类型选择适当的检验统计量。对于校园交通事故与电动车超速之间的关系,可以使用统计方法(如卡方检验或者回归分析)来评估两者之间的相关性。
- 计算p值:根据所选择的检验统计量和样本数据计算出实际观察到的统计量的概率(即p值)。p值表示在零假设下观察到与实际观察到的统计量相同或更极端结果的概率。
- 做出决策:根据计算得到的p值与显著性水平进行比较,如果p值小于显著性水平,则拒绝零假设,认为结果具有统计显著性,支持备择假设。如果p值大于显著性水平,则无法拒绝零假设,无法得出结论。
需要注意的是,假设检验是一种统计推断方法,结果并不总是能得出确定的结论,而是提供了针对零假设的证据。此外,假设检验的可靠性还取决于采集的样本数据的质量、样本容量以及其他假设前提的满足程度。因此,在进行假设检验时,需要谨慎解释结果并综合考虑其他相关因素。
P值若小于我们假设的α则说明我们拒绝我们的零假设。
若p值大于则说明我们无法拒绝我们的零假设。
在假设检验中,我们可以使用单侧检验或双侧检验来评估零假设的可行性。这两种检验方法的选择取决于研究问题和预期效应的方向。
- 单侧检验(One-tailed test):在单侧检验中,我们关注的是假设效应在一个方向上是否显著。单侧检验适用于我们有明确的理论依据或研究目的,希望验证或推断效应的方向。例如,我们研究一种新药物是否能够显著降低血压,我们只关心药物对血压的降低是否显著,而不关心是否会增加血压。在单侧检验中,显著性水平(α)只存在于一个尾部。
- 双侧检验(Two-tailed test):在双侧检验中,我们关注的是假设效应在两个方向上是否显著。双侧检验适用于我们对效应的方向没有明确的预期,只想确定是否存在显著的效应。例如,我们研究一种新的教学方法是否能够显著提高学生的成绩,但我们不确定这种方法会显著提高还是显著降低学生成绩。在双侧检验中,显著性水平(α)在两个尾部进行比较。
在进行单侧检验或双侧检验时,我们需要计算得到的检验统计量与相应的临界值进行比较。对于单侧检验,我们只关注一个尾部的临界值;而对于双侧检验,我们要考虑两个尾部的临界值。如果计算得到的检验统计量在临界值范围内或小于显著性水平(α),则可以拒绝零假设,认为结果具有统计显著性。
需要注意的是,在选择单侧检验还是双侧检验时,要根据研究问题和预期效应来确定。如果有明确的预期效应方向,可以选择单侧检验;如果没有明确的预期效应方向,可以选择双侧检验。
(上图中就是单侧检验)
双侧检验的p值比较是需要×2再去比较:
第三部分:皮尔逊相关系数假设检验
对相关系数大小的解释: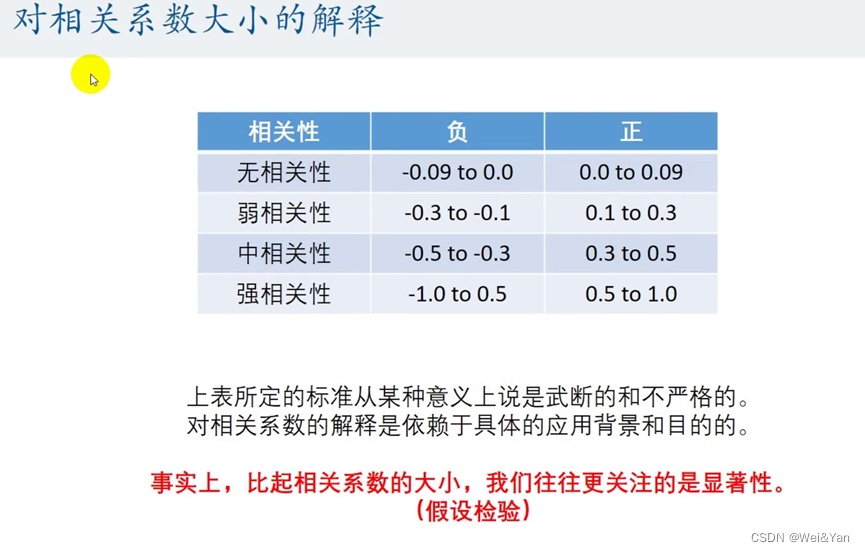
对皮尔逊相关系数进行假设检验:
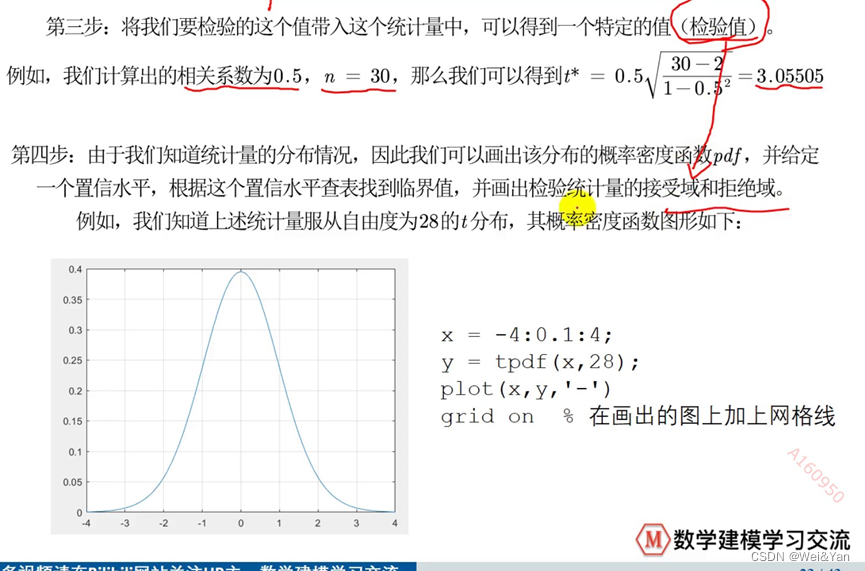
步骤:


Matlab中求临界值: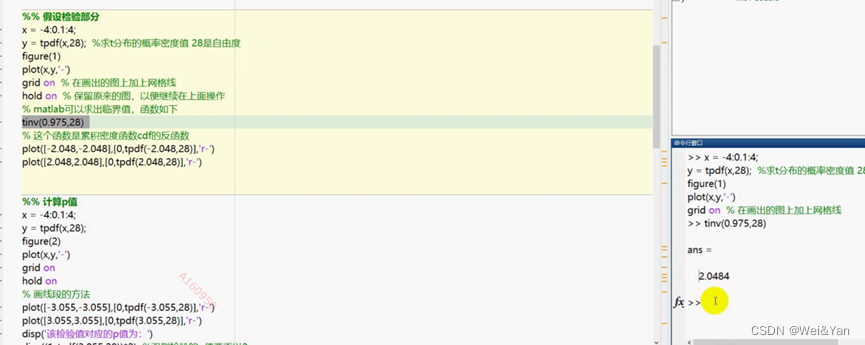
更好的判断方法P值判断法: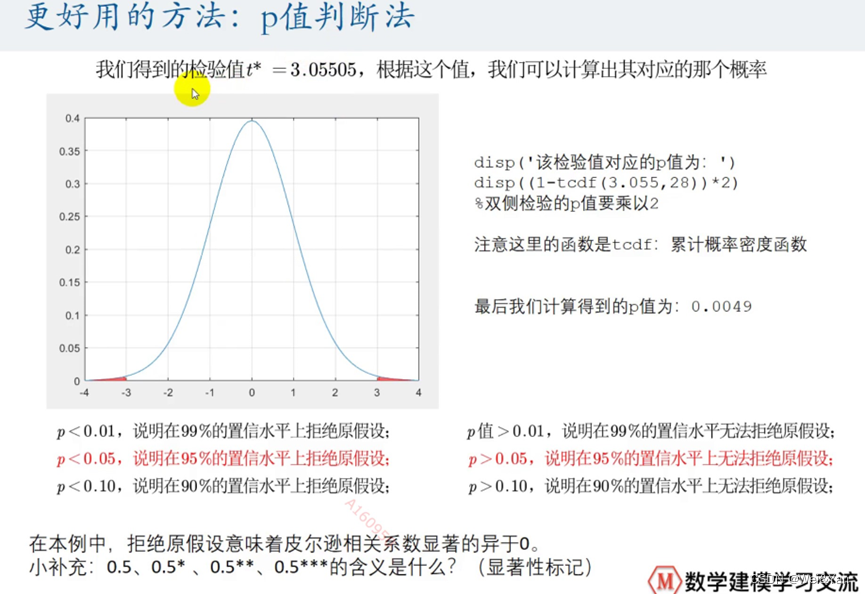
matlab中求p值:
corrcoef有两个接收值的时候第一个为相关性,第二个为p值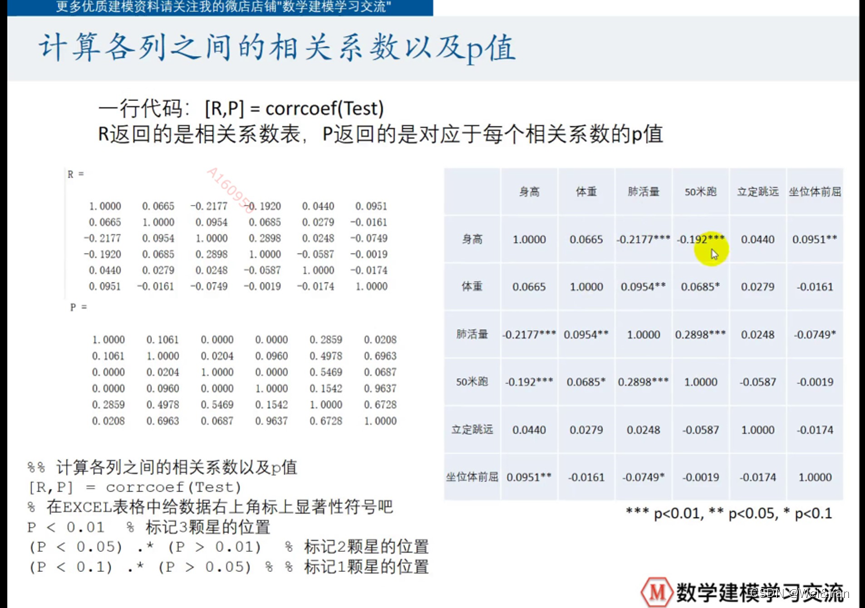
单侧:1-累计密度函数tcdf(x值,自由值)
双侧:单侧结果*2
显著性标记:一般p值<0.01***,p>0.01&&p<0.05**,p>0.05&&p<0.1* 
计算各列之间的相关系数以及p值
也可以用spss计算p值更加方便:


生成已经标记好的图像(spss中一般最多标记两个*):
第四部分皮尔逊相关系数假设性检验的条件
正态分布JB检验(大样本n>30)
定义:
偏度和峰度: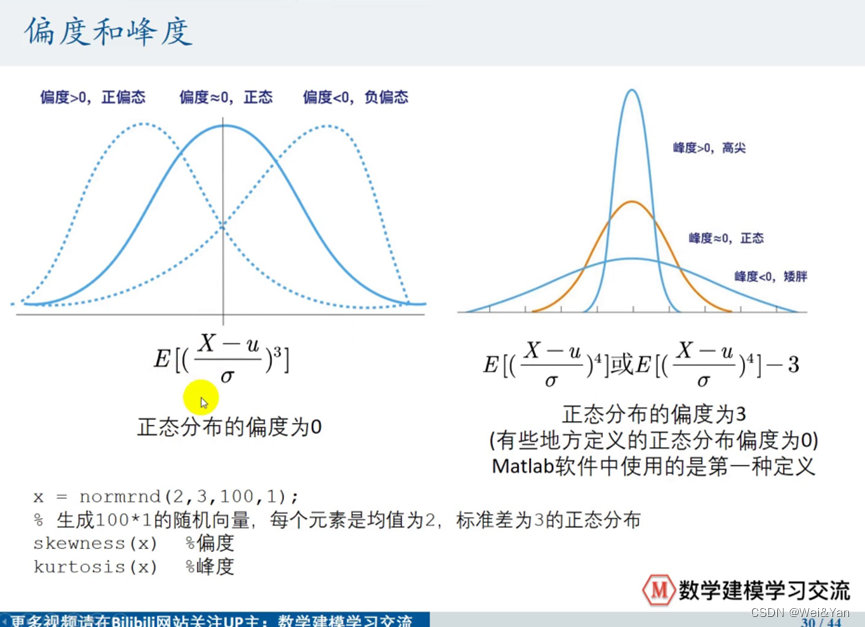
Matlab中JB检验的函数:(但是matlab中的jb检验只能按列检验,所以需要利用循环将将数据中的元素按列检验,得到每列的检验结果)
代码实现(检验数据:八年级女生体测):
%JB检验
%jbtest只能每次按列求
[h,p] = jbtest(S(:,1),0.05);%参数为正态分布,alpha(阿尔法)
[h,p] = jbtest(S(:,1),0.01);
%每列进行jb检验
[r,c] = size(S)
%提前开辟好相应的矩阵空间方便节省时间
H = zeros(1,c);
P = zeros(1,c);
%因为每次jb检验只能检验一列,所以利用for循环检验所有数据
for i=1:c
[h,p] = jbtest(S(:,i),0.05)
H(i) = h;
P(i) = p;
end
disp(H)
disp(P)运行结果:
H是检验自己的零假设是否成立,返回0则成立返回1则不成立
P的值过小则返回0.01(可看成0)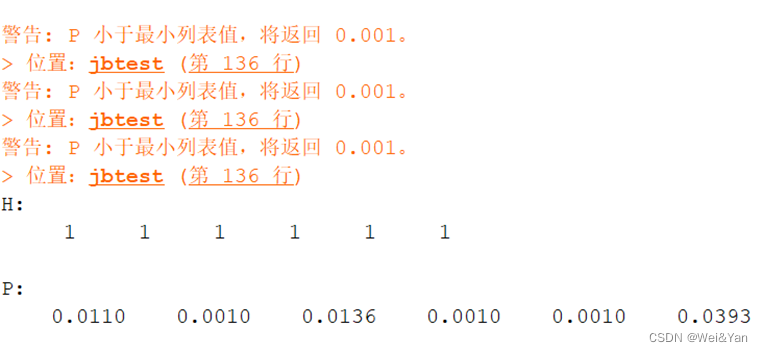
夏皮洛-威尔克检验(小样本3<=n<=50):
利用spss软件检验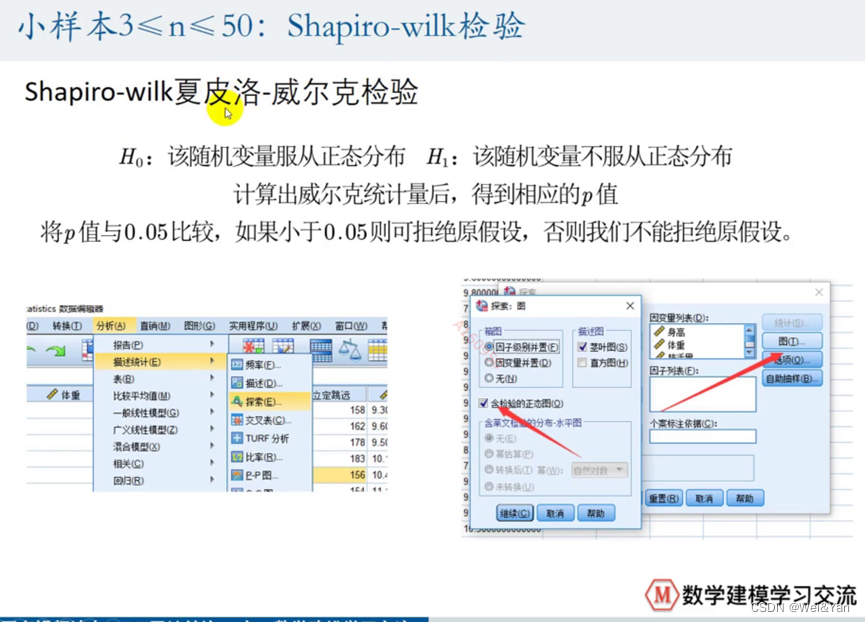
检验结果:
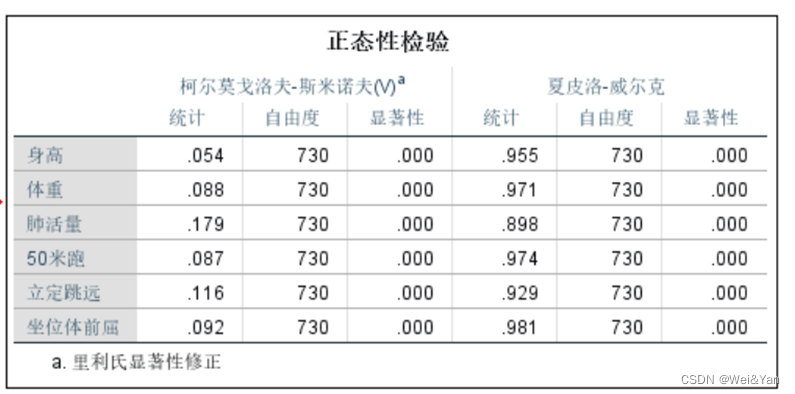
Q-Q图检验正态分布
看数据点是否都落在直线上,若有偏差的话则不符合正态分布(只能按列检验生成相应的QQ图)
Matlab中的QQ图函数:
qqplot(数据)
在spss中可以直接全部显示所有列的qq图:
(在夏洛皮及检验方法中就会生成qq图)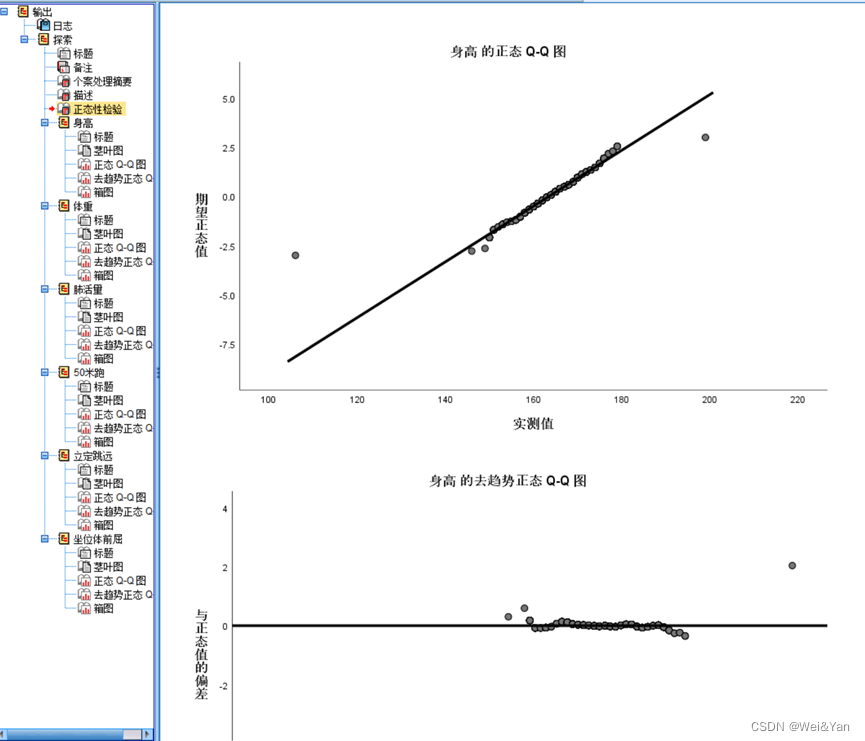
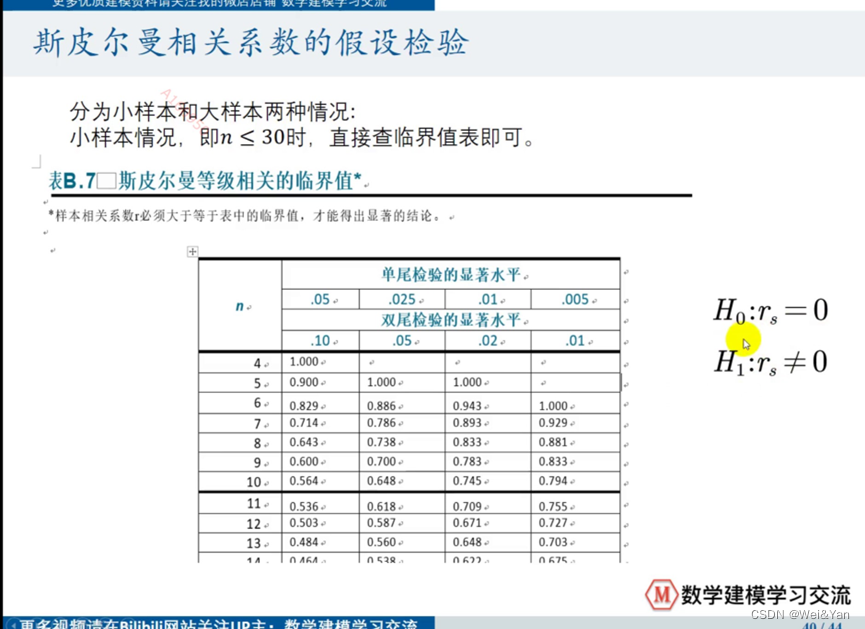
第五部分:斯皮尔曼相关系数
定义:
斯皮尔曼相关系数是利用数据在经过排序后的在数据在的序号用来检验,通过计算得到R

斯皮尔曼的两种方法: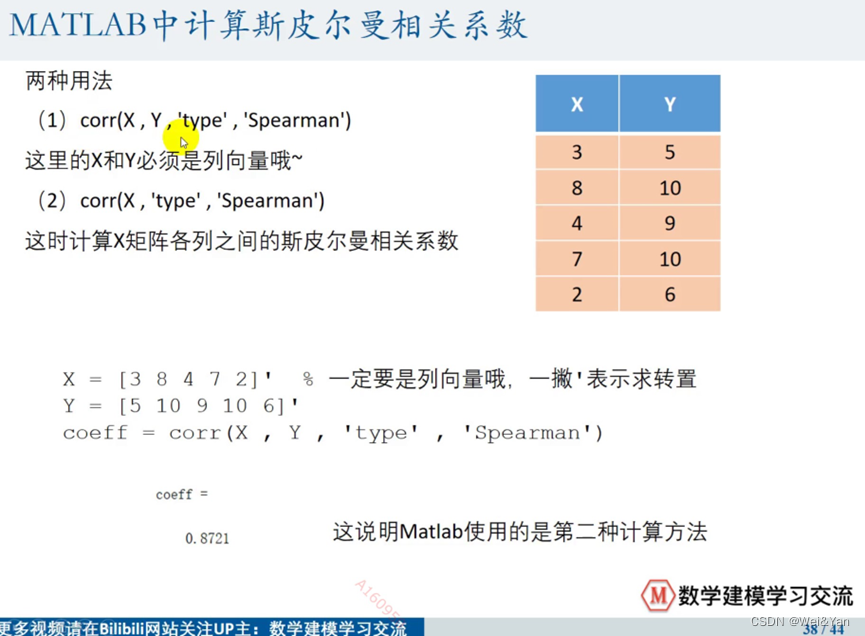
代码实现: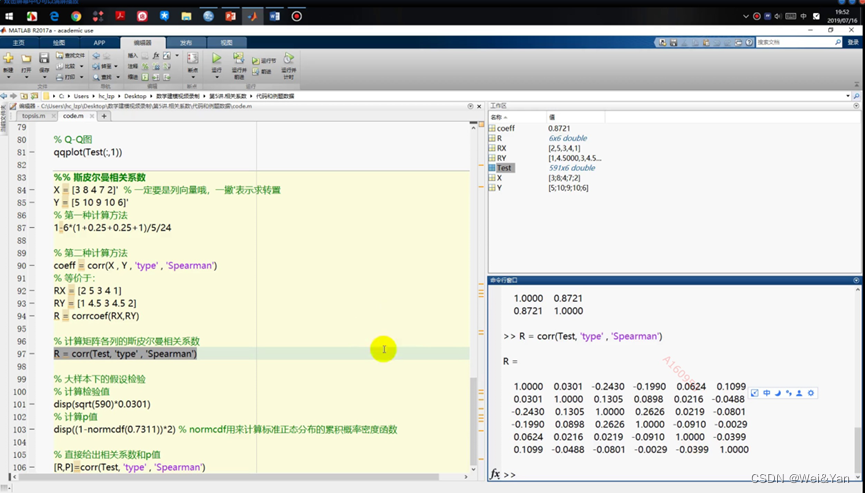
也可以用spss生成:
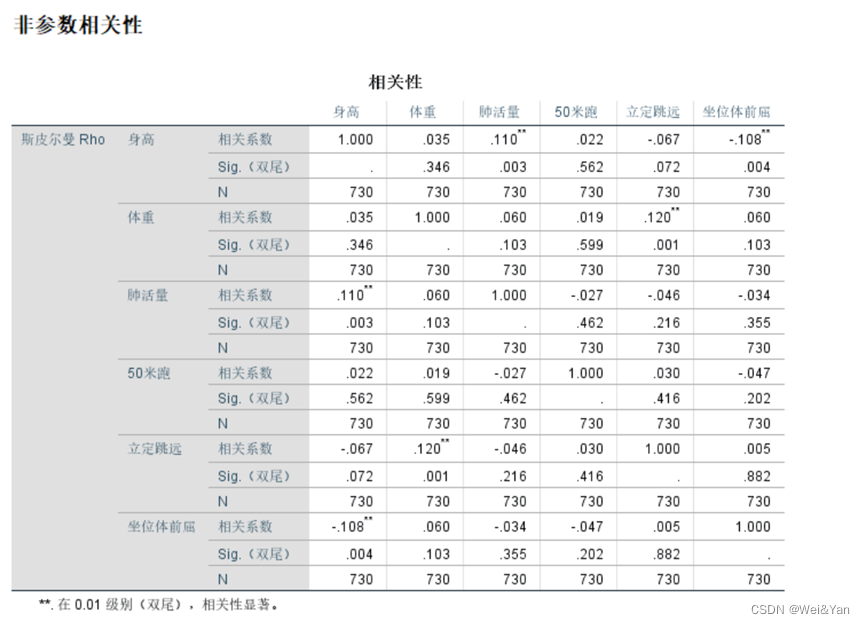
斯皮尔相关系数与皮尔逊相关系数的对比:

斯皮尔曼相关系数的假设检验:

Matlab中斯皮尔假设检验的函数:

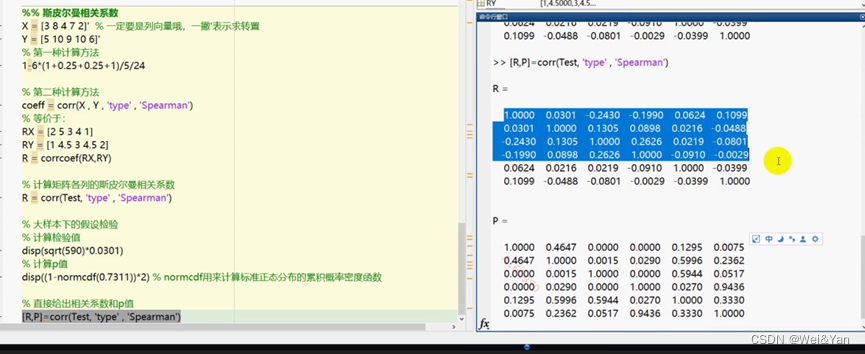
两个相关系数的总结与对比:

我们得到一组数据后可以先利用spss检验是否符合正态分布
分析->描述统计->探索-->导入数据-->图-->含检验的正态图
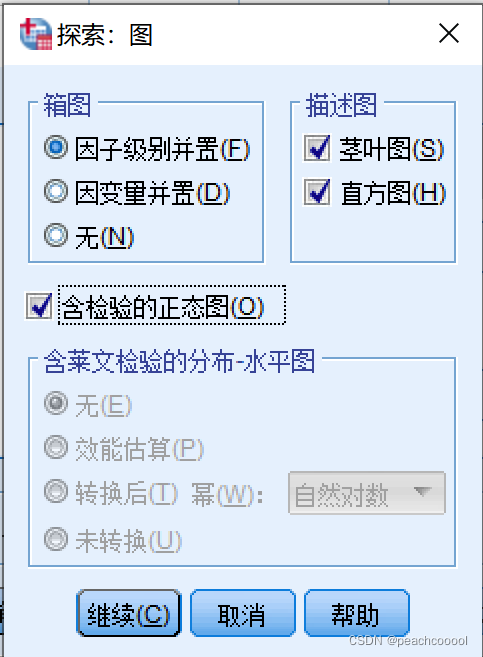
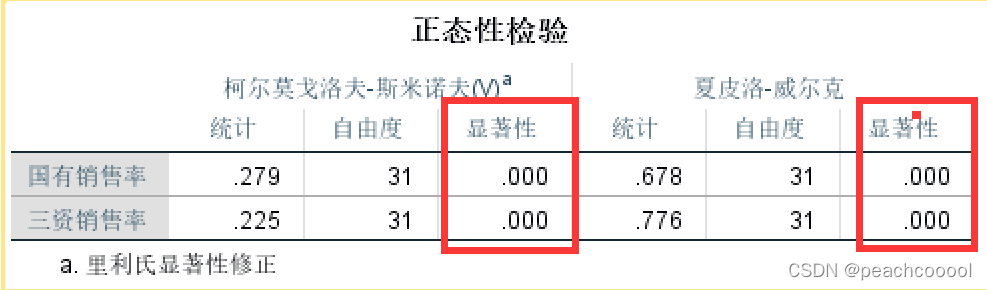
若P值>0.05,服从正态分布
若P值<0.05,不服从正态分布
故结论:两个数据都不服从正态分布
本篇文章中八年级女生体测数据代码参考:
clear;clc
%S为女生数据,B为男生数据
load 相关性系数\girl_data.mat
%统计描述
MIN = min(S);%最小值
MAX = max(S);%最大值
MEAN = mean(S);%均值
MEDIAN = median(S);%中位数值
SKEWNESS = skewness(S);%偏度
KURTOSIS = kurtosis(S);%峰度
STD = std(S);%标准差
Result = [MIN;MAX;MEAN;MEDIAN;SKEWNESS;KURTOSIS;STD];
%计算各列之间的相关系数R,P值
[R,P] = corrcoef(S);
%通过P值判断法进行相关性检验
P<0.01 %标记三颗星
(P>0.01) .* (P<0.05);%标记两颗星
(P>0.05) .* (P<0.10);%标记一颗星
%构建一个随机的正态分布
x = normrnd(2,3,100);
%求其偏度
skewness(x);
%求其峰度
kurtosis(x);
%JB检验
%jbtest只能每次按列求
[h,p] = jbtest(S(:,1),0.05);%参数为正态分布,alpha(阿尔法)
[h,p] = jbtest(S(:,1),0.01);
%每列进行jb检验
[r,c] = size(S)
%提前开辟好相应的矩阵空间方便节省时间
H = zeros(1,c);
P = zeros(1,c);
%因为每次jb检验只能检验一列,所以利用for循环检验所有数据
for i=1:c
[h,p] = jbtest(S(:,i),0.05);
H(i) = h;
P(i) = p;
end
disp('H:')
disp(H)
disp('P:')
disp(P)
qqplot(S(:,1))
%~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
%通过斯皮尔曼系数求男生数据
%求男生体测数据的列和行
[l,h] = size(B);
%利用斯皮尔曼相关系数求[相关性,显著性(p值)]
[R2,P2] = corr(B,'type','Spearman')
博主主要跟着清风数学建模的课程学习,其中里面的一些图片都来源于上课视频的截图。